[논문] Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented Generation
·
AI
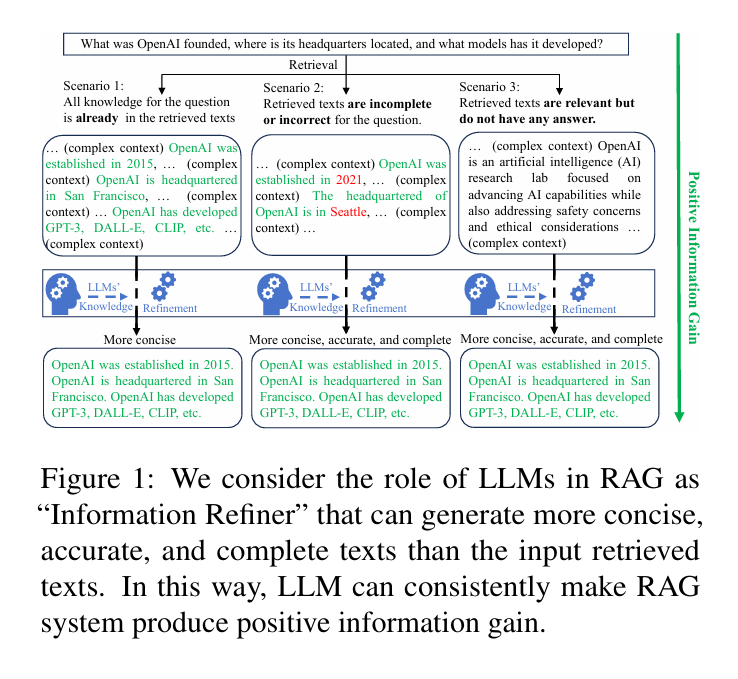
논문 링크 : https://arxiv.org/abs/2402.18150 Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented GenerationRetrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating additional information from retrieval. However, studies have shown that LLMs still face challenges in effectively using the retrieved information, even ignoring ..







