ABSTRACT
추천 시스템에서는 새로운 아이템이 지속적으로 도입되며, 초기에는 상호작용 기록이 부족하지만 시간이 지남에 따라 점차 쌓이게 된다. 이러한 아이템의 클릭률(CTR)을 정확하게 예측하는 것은 수익과 사용자 경험을 향상하는 데 중요하다. 기존 방법들은 일반적인 CTR 모델 내에서 새로운 아이템의 ID 임베딩을 향상하는 데 중점을 두지만, 전역적인 특징 상호작용 접근 방식을 채택하는 경향이 있어 상호작용이 풍부한 아이템이 상호작용이 적은 새 아이템을 압도하는 경우가 많다. 이에 대응하여, 우리의 연구는 아이템별 특징 상호작용 패턴을 학습하여 콜드 스타트 CTR 예측을 강화하는 EmerG라는 새로운 접근 방식을 소개한다. EmerG는 하이퍼네트워크를 활용하여 아이템 특성에 기반한 아이템별 특징 그래프를 생성하며, 이 그래프는 그래프 신경망(GNN)에 의해 처리된다. 이 GNN은 특정 메시지 전달 메커니즘을 통해 모든 차수에서 특징 상호작용을 포착할 수 있도록 특별히 설계되었다. 우리는 하이퍼네트워크와 GNN의 매개변수를 다양한 아이템 CTR 예측 작업에서 최적화하는 메타 학습 전략을 설계하여 각 작업에서 최소한의 아이템별 매개변수만 조정한다. 이 전략은 제한된 데이터로 인한 과적합 위험을 효과적으로 줄인다. 벤치마크 데이터셋에 대한 광범위한 실험을 통해 EmerG가 새 아이템이 없거나, 적거나, 충분히 있는 경우에도 일관되게 최고의 성능을 보임을 확인하였다.
1 INTRODUCTION
콜드 스타트 문제는 추천 시스템에서 중요한 도전 과제로 나타나며, 특히 새로운 아이템이 사용자 상호작용이 없는 상태(콜드 스타트 단계)에서 몇 번의 초기 클릭을 얻는 상태(웜업 단계)로 전환할 때 두드러진다. 복잡한 특징 상호작용을 포착할 수 있는 딥러닝 모델은 클릭률(CTR) 예측을 개선하는 데 유망한 것으로 입증되었으며, 이는 다양한 아이템(예: 영화, 상품, 음악)에 대한 사용자 참여 가능성을 평가하는 중요한 지표이다. 그러나 이러한 모델은 최적의 성능을 달성하기 위해 방대한 데이터셋에 의존하는 경향이 있으며, 이는 콜드 스타트와 웜업 단계에서 제약이 된다. 모델의 상당한 매개변수 크기는 상호작용 기록이 제한된 이러한 단계에 효과적으로 적응하는 데 어려움을 초래하여 CTR 예측의 정확도를 높이고 비용을 들이지 않고 모델을 업데이트하는 데 어려움이 된다.
최근 연구들은 추천 시스템에서 아이템 콜드 스타트 문제를 완화하기 위한 전략으로 아이템 ID 임베딩의 초기화를 개선하는 데 중점을 두었으며, 웜업 단계에서 상호작용 기록이 제공되면 이를 통해 후속 업데이트를 수행한다. 이후 일반적인 CTR 백본을 활용하여 추가 처리를 수행한다. 그러나 이들은 중요한 측면을 간과하고 있다: 사용자와 아이템 간의 특징 상호작용 패턴의 독특함이다. 이러한 간과는 사용자-아이템 상호작용의 미묘한 역학을 완전히 포착하는 능력을 제한하며, 개인화된 추천이 중요한 시나리오에서 CTR 예측의 정확성과 효율성에 잠재적인 영향을 미칠 수 있다. 예를 들어, 고가의 럭셔리 아이템과 저가의 일상 필수품을 비교할 때 상호작용 패턴이 뚜렷하게 다르다. 고가의 럭셔리 아이템의 경우, 아이템의 가격과 사용자의 소득 수준 간의 상호작용이 결정적이다. 특히, 가격과 소득이라는 2차 특징 상호작용은 사용자가 해당 아이템을 구매할 의사를 결정하는 데 중요한 요소가 될 수 있다. 반면, 저가의 일상 필수품의 경우 소득 수준이 구매 결정에 미치는 영향은 줄어든다. 이러한 경우에는 사용자 나이와 아이템 카테고리 간의 상호작용과 같은 다른 특징 상호작용이 상대적으로 더 중요해진다. 이와 같은 차이는 아이템별 특징 상호작용 패턴을 모델링하는 필요성을 강조한다. 기존 연구들은 모두 사용자와 아이템 간의 전역적인 특징 상호작용 패턴을 학습하며, 이는 제한된 상호작용 기록을 가진 새 아이템을 풍부한 상호작용 기록을 가진 기존 아이템이 압도하게 한다.
특징 상호작용의 중요한 역할을 인식하여, 우리는 EmerG를 통해 새롭게 등장하는 아이템의 CTR 예측 문제를 해결하고자 하며, 상호작용 데이터가 점차적으로 증가하는 과정(상호작용 기록이 없는 단계에서 일부 기록이 있는 단계, 그리고 풍부한 기록을 가지는 단계로 발전)을 아이템별 특징 그래프 학습을 통해 다룬다. 우리의 기여는 다음과 같이 요약된다:
- 우리는 아이템별 특징 상호작용을 강조하는 독창적인 방법을 제안하여, 방대한 데이터를 가진 기존 아이템이 새로운 아이템을 압도하는 문제를 해결하며, CTR 예측의 문제를 해결한다. 하이퍼네트워크를 활용하여 특징을 노드로 하고 상호작용을 엣지로 하는 아이템별 특징 그래프를 구성하여 각 아이템에 고유한 복잡한 상호작용 패턴을 포착한다. 우리는 사용자 정의된 메시지 전달 과정을 갖춘 그래프 신경망(GNN)을 사용하여 모든 차수의 특징 상호작용을 포착할 수 있도록 설계하여, 이를 복잡하고 정확한 예측에 결합할 수 있게 한다.
- 제한된 데이터로 인해 발생하는 과적합을 완화하기 위해, 하이퍼네트워크와 GNN의 매개변수를 다양한 아이템 CTR 예측 작업에서 최적화하는 메타 학습 전략을 채택하며, 각 작업 내에서 최소한의 아이템별 매개변수만을 조정한다. 또한, 이러한 방식으로 학습된 하이퍼네트워크와 GNN은 각 작업에 쉽게 일반화될 수 있다.
- 우리는 벤치마크 데이터셋에 대한 광범위한 실험을 수행하여 EmerG가 새롭게 등장하는 아이템의 CTR 예측에서 최고의 성능을 발휘함을 확인하였다. 더 많은 학습 데이터를 제공한 경우에도 EmerG는 일관되게 최고의 성능을 나타냈다. 아이템별 특징 그래프를 기록하는 인접 행렬의 시각화는 EmerG가 아이템별 특징 상호작용을 올바르게 학습할 수 있음을 보여준다.
2 RELATED WORKS
CTR 예측에서 새로 등장한 아이템과 관련된 네 가지 방법군을 간략히 검토한다.
A. General CTR Models.
일반 CTR 모델은 저평가된 아이템을 우선시하지 않고 보편적으로 적용된다. 이 모델들은 CTR 예측 정확도를 높이는 데 중요한 복잡한 특징 상호작용을 모델링하는 데 주로 중점을 둔다 [3]. 이 분야의 발전은 로지스틱 회귀와 같은 선형 모델이 1차 상호작용을 포착하는 것에서 시작하여 [27], Factorization Machines(FM)이 2차 상호작용을 모델링하고 [26], 고차 FM(HOFM)이 고차 상호작용을 다루는 방향으로 진행되었다 [2]. 다양한 딥러닝 모델들은 이러한 복잡한 패턴을 자동으로 학습한다. Wide&Deep [5]와 DeepFM [9]은 2차 및 고차 상호작용을 다루기 위해 하이브리드 아키텍처를 채택한다. DIN [43]은 주의 메커니즘을 통해 사용자 관심사를 동적으로 포착하여 변화하는 광고 특징에 적응한다. AutoInt [28]는 멀티 헤드 셀프 어텐션 메커니즘 [30]을 도입하여 고차 특징 상호작용을 모델링한다. LorentzFM [40]은 파라미터 크기를 줄이기 위해 하이퍼볼릭 공간에서 특징 상호작용을 탐색한다. AFN [6]은 학습될 계수로 각 특징의 세기를 변환한다. FinalMLP [21]는 병렬로 구성된 두 개의 MLP 네트워크를 사용하여 특징 선택과 상호작용 집계 레이어를 갖추고 있다. FINAL [44]은 특징 상호작용 학습의 기하급수적 성장을 위한 분해된 상호작용 레이어를 도입한다. 특징 상호작용을 사용자 및 아이템 특징을 나타내는 노드로 구성된 그래프로 개념화할 수 있다는 점을 고려하여 그래프 신경망(GNN)이 사용된다 [15]. Fi-GNN [17]은 특징 임베딩 간의 유사성을 기준으로 엣지를 설정하여 특징 그래프 생성을 학습한다. FIVES [39]는 대규모 CTR 데이터셋에서 차별화된 검색을 통해 엣지를 설정하여 글로벌 특징 그래프를 학습하며, 이는 제한된 데이터로 인해 새 아이템이 저평가될 수 있다. GMT [22]는 아이템, 사용자 및 그 특징 간의 상호작용을 대규모 이종 그래프로 모델링한 후, 예측을 위해 타겟 사용자-아이템 쌍의 로컬 이웃을 제공한다. 그러나 이러한 일반적인 CTR 모델들은 대규모 데이터셋을 위해 설계되었기 때문에 콜드 스타트 및 웜업 단계에서 과적합 문제가 발생할 수 있다. EmerG는 다양한 CTR 작업에서 학습된 하이퍼네트워크를 통해 생성된 아이템별 특징 그래프를 사용하는 특화된 GNN을 도입하여 새로운 아이템에 대해 최소한의 매개변수 조정을 통해 특징 상호작용을 정확하게 모델링할 수 있다.
B. Methods for New Items without Interaction Records.
몇몇 방법들은 새로운 아이템이 상호작용 기록이 없는 콜드 스타트 단계에서 기존 아이템의 모델 성능을 유지하면서도 이러한 아이템에 중점을 두어 다룬다. DropoutNet [31]은 입력 샘플에 드롭아웃 메커니즘을 적용하여 결측 데이터를 추론하는 신경망을 학습한다. Heater [46]는 다중 게이트 전문가 혼합 접근 방식을 사용하여 아이템 임베딩을 생성한다. GAR [4]는 생성자와 추천자 사이의 적대적 학습 전략을 사용하여 기존 임베딩 분포를 모방하는 새로운 아이템 임베딩을 생성하여 추천 시스템을 속인다. ALDI [12]는 기존 아이템의 행동 정보를 새로운 아이템으로 이전하는 것을 학습한다. 그러나 이러한 방법들은 새로운 아이템에 대한 상호작용 기록의 수용을 고려하지 않으며, 이러한 아이템의 진화하는 상호작용 기록에 맞추기 위해 재훈련이 필요하다.
C. Methods for New Items with A Few Interaction Records.
새 아이템이 몇 가지 인스턴스만을 가지는 웜업 단계에 해당하는 상황에서 few-shot 학습 [35]이 자연스러운 해결책을 제공한다. few-shot 학습은 몇 개의 레이블이 지정된 샘플로 새로운 작업에 일반화하는 것을 목표로 하며, 이미지 분류 [8], 쿼리 의도 인식 [34], 약물 발견 [33, 38, 41]에 적용되었다. CTR 예측의 경우, 기존 연구들은 일반적으로 이를 𝑁-way 𝐾-shot 작업으로 접근하여, 각 새로운 아이템이 𝐾개의 레이블이 지정된 인스턴스와 연관되며, 그 후 고전적인 그래디언트 기반 메타 학습 전략을 사용한다 [8]. MeLU [16]는 그래디언트 하강을 통해 새로운 아이템에 맞추어 모델 매개변수를 선택적으로 조정하는 이 전략을 활용한다. MAMO [7]는 외부 메모리 메커니즘을 통합하여 적응력을 강화한다. MetaHIN [20]은 이질적인 정보 네트워크를 사용하여 사용자와 아이템 간의 풍부한 의미적 관계를 활용한다. PAML [32]은 유사한 사용자들 간의 정보 공유를 촉진하기 위해 사회적 관계를 활용한다. 최근의 접근 방식은 그래디언트 하강을 통한 사용자별 미세 조정에서부터 암묵화된 방법으로 전환하였다. 이러한 방법들은 사용자 상호작용 이력을 사용자별 매개변수로 직접 매핑하여 주요 네트워크를 반복적인 조정 없이 조정한다. TaNP [18]는 아이템 상호작용 기록을 기반으로 아이템별 매개변수를 조정하는 것을 학습한다. ColdNAS [37]는 네트워크 내에서 조정 함수의 최적화를 위해 신경망 구조 검색을 사용한다. 그러나 이러한 방법들은 상호작용 기록이 없는 새로운 아이템을 다루기 어렵고, 추가적인 상호작용 기록이 추가될 때 이를 동적으로 통합하지 못한다.
D. Methods for Emerging Items with Incremental Interaction Records.
산업의 동적 진화를 반영하여 새로운 아이템이 상호작용 기록이 없는 단계에서 몇 개의 기록을 가진 단계, 그리고 풍부한 기록을 가지는 단계로 점진적으로 발전하는 과정을 원활하게 관리하기 위해 모델이 개발되었다. 기존의 노력은 일반 CTR 백본에 대해 아이템 ID 임베딩을 향상시키는 데 주로 초점을 맞추고 있다. MetaE [24]는 그래디언트 기반 메타 학습을 사용하여 임베딩 생성기를 학습한다. MWUF [45]는 불안정한 아이템 ID 임베딩을 메타 네트워크를 사용하여 안정적인 임베딩으로 변환한다. CVAR [42]는 아이템 측면 정보를 기반으로 새로운 아이템 ID 임베딩을 디코딩하여 추가 데이터 처리를 피한다. GME [23]는 기존 아이템의 정보를 활용하여 새로운 아이템 ID 임베딩 생성을 지원한다. 그러나 이러한 방법들은 일반적으로 초기 아이템 ID 임베딩을 최적화하면서 전역적인 특징 상호작용 패턴을 유지하여, 이러한 아이템의 고유한 특성과 상호작용 역학을 포착하는 데 한계가 있다. 반면, EmerG는 하이퍼네트워크의 도움으로 각 아이템에 맞춘 특징 상호작용을 조정함으로써 새로운 아이템의 CTR 예측을 다룬다. 아이템별 특징 상호작용을 학습하여, 방대한 데이터를 가진 기존 아이템이 새 아이템을 압도하는 위험을 줄이고 예측 정확도를 향상시킨다.
3 PROBLEM FOR MULATION
V = {𝑣𝑖}를 아이템 집합으로 두며, 각 아이템 𝑣𝑖는 아이템 ID, 유형, 가격과 같은 𝑁𝑣 개의 아이템 특징과 연관되어 있다. 마찬가지로 U = {𝑢𝑗}를 사용자 집합으로 두며, 각 사용자 𝑢𝑗는 사용자 ID, 나이, 고향과 같은 𝑁𝑢개의 사용자 특징과 연관되어 있다. 사용자가 아이템 𝑣𝑖를 클릭하면 레이블 𝑦𝑖,𝑗 = 1, 그렇지 않으면 𝑦𝑖,𝑗 = 0이 된다. 학습 동안, 예측자는 구 CTR 예측 작업 집합 T_old = 𝑇𝑖_𝑡=1{𝑁𝑡}에서 학습되어 훈련 중 보지 않은 새로운 아이템의 작업을 예측할 수 있도록 일반화된다. 각 작업 T𝑖는 과거 아이템 𝑣𝑖에 대응하며, 기존 상호작용 기록을 포함하는 훈련 세트 S𝑖 = {(𝑣𝑖,𝑢𝑗,𝑦𝑖,𝑗)\}_{𝑗=1}^{𝑁𝑠}와 예측할 상호작용을 포함하는 테스트 세트 Q𝑖 = {(𝑣𝑖,𝑢𝑗,𝑦𝑖,𝑗)\}_{𝑗=1}^{𝑁𝑞}로 구성된다. 𝑁𝑠와 𝑁𝑞는 각각 S𝑖와 Q𝑖에서의 상호작용 수를 나타낸다.
테스트 시에는 상호작용 기록이 없는 새로운 아이템에서 시작해 점차 몇 개의 기록을 모으고 결국 충분한 기록을 쌓게 되는 새로운 아이템의 CTR 예측을 고려한다. 훈련 중 고려되지 않은 새로운 아이템 𝑣𝑘와 연관된 작업 T𝑘에서 다음 세 가지 단계를 다룬다:
- 콜드 스타트 단계: 훈련 세트가 제공되지 않음.
- 웜업 단계: 𝑣𝑘의 일부 상호작용 기록을 포함하는 훈련 세트 S𝑘가 주어진다. 상호작용 기록이 점진적으로 축적되는 여러 웜업 단계를 가질 수 있다.
- 공통 단계: 𝑣𝑘의 훈련 상호작용 기록이 충분히 축적됨.
모든 단계에서 성능은 테스트 세트 Q𝑘에서 평가된다.
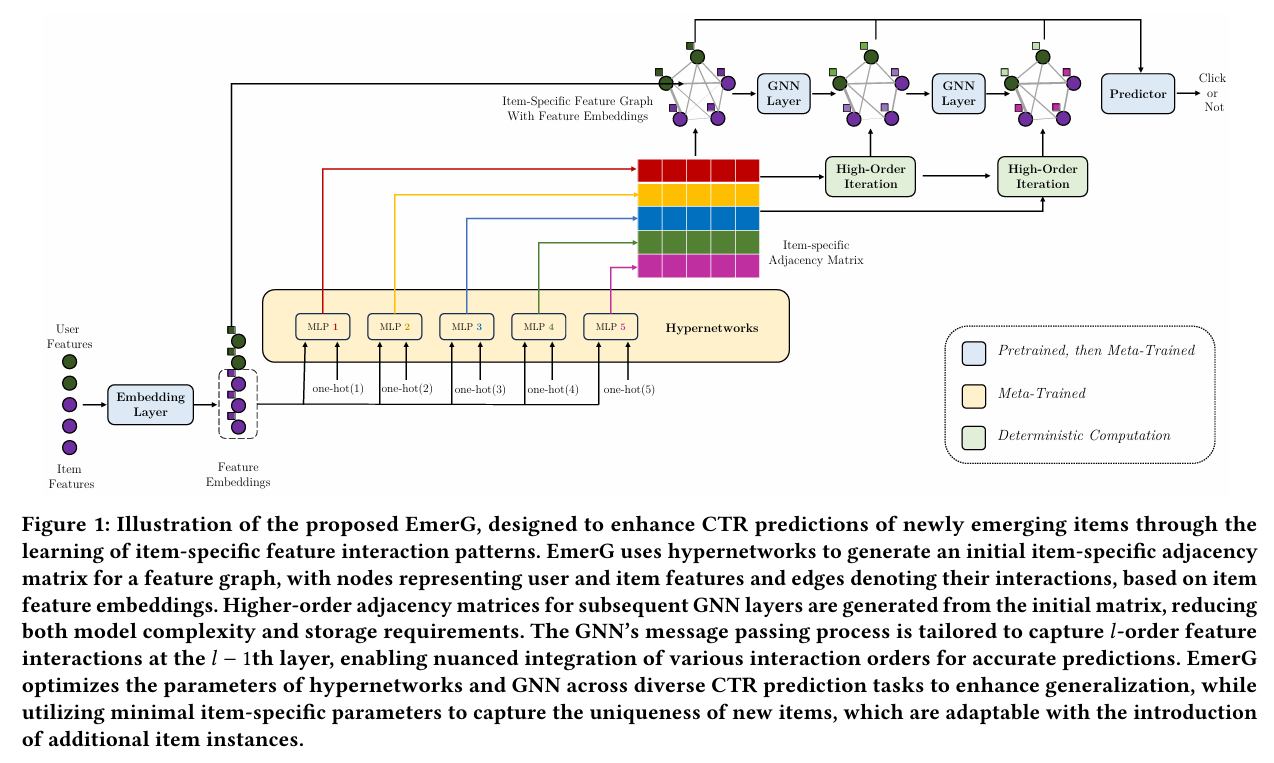
4 THE PROPOSED EMERG
특징 상호작용이 중요하다는 기존 이해에 따라, 우리는 각 아이템과 연관된 특징 상호작용 패턴을 통해 아이템의 독특성을 포착하는 EmerG(Figure 1)를 제안한다. EmerG에는 두 가지 주요 구성 요소가 있다: (i) 특징 그래프를 인코딩하는 아이템별 인접 행렬을 생성하는 다양한 작업에서 공유되는 하이퍼네트워크와, (ii) 생성된 아이템별 특징 그래프에서 작동하며 임의 차수의 특징 상호작용을 포착할 수 있도록 특별히 설계된 메시지 전달 메커니즘을 가진 GNN. 콜드 스타트와 웜업 단계를 고려하여, 우리는 다양한 아이템 CTR 예측 작업에서 하이퍼네트워크와 GNN의 매개변수를 최적화하면서 각 작업 내에서 최소한의 아이템별 매개변수만 조정하는 메타 학습 전략을 추가로 설계한다. 이 전략은 제한된 데이터로 인한 과적합 위험을 효과적으로 줄인다.
4.1 Embedding Layer
주어진 인스턴스 (𝑢,𝑣) 에서 임베딩 레이어는 사용자 특징 𝑢와 아이템 특징 𝑣를 밀집 벡터로 매핑한다. 𝑚번째 특징 𝑓𝑚, 𝑚 in [1,𝑁𝑣 +𝑁𝑢]의 특징 임베딩 e𝑚은 다음과 같이 얻어진다:
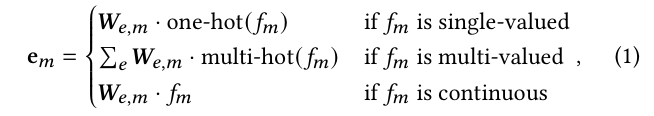
여기서 𝑾𝑒,𝑚은 𝑚번째 특징에 해당하는 임베딩 행렬을 나타내고, one-hot(𝑓𝑚)은 단일 값 특징 𝑓𝑚의 원-핫 벡터, multi-hot (𝑓𝑚)은 다중값 특징 𝑓𝑚의 멀티-핫 벡터를 나타낸다.
4.2 Item-Specific Feature Graph Generation
우리는 Ha et al. [10]의 전략을 따라 하이퍼네트워크를 활용하여 아이템별 특징 그래프를 생성한다. 하이퍼네트워크는 작은 신경망으로, 더 큰 메인 네트워크의 파라미터를 생성하도록 학습되며, 이들의 통합은 문제에 따라 매우 특화된 도전 과제를 제시한다. EmerG에서는 하이퍼네트워크를 사용하여 첫 번째 GNN 레이어를 위한 아이템별 특징 그래프를 인코딩하는 초기 인접 행렬 A(1)_{𝑖} 을 생성한다. 우리는 후속 GNN 레이어들이 초기 A(1)_{𝑖}에서 인접 행렬을 유도하게 함으로써 저장 효율성을 최적화하면서도 각 아이템에 대한 모델의 특화성을 유지한다.
아이템 𝑣𝑖와 연관된 작업 T𝑖를 고려한다. 아이템 특징 \( 𝑓1, \ldots, 𝑓𝑁𝑣 \)에 대해, 아이템 특징 임베딩은 각각 \( e1,𝑖, \ldots, e𝑁𝑣,𝑖 \)로 표시된다. 특징 그래프 [17, 39]는 각 노드가 특징 𝑓𝑚에 대응하고, 두 노드 간의 엣지가 그들의 상호작용을 기록하는 그래프이다. 하이퍼네트워크는 \( 𝑁𝑣 + 𝑁𝑢 \)개의 서브 네트워크로 구성되며, 첫 번째 GNN 레이어에서 사용될 특징 그래프를 인코딩하는 밀집 아이템별 행렬 \( \bar{A}(1)_{𝑖} \in \mathbb{R}^{(𝑁𝑣+𝑁𝑢) \times (𝑁𝑣+𝑁𝑢)} \)을 생성한다. \( \bar{A}(1)_{𝑖} \)의 \( 𝑚 \)번째 행을 \( [\bar{A}(1)_{𝑖}]_{𝑚:} \)라 하고, 이는 다음과 같이 계산된다:
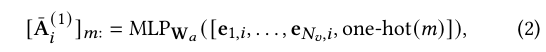
여기서 \( \text{MLP}_{W𝑎} \)는 파라미터 \( W𝑎 \)를 가진 다층 퍼셉트론(MLP)을 나타낸다. 그 다음 \( \bar{A}(𝑙)_{𝑖} \)를 다음과 같이 생성한다:
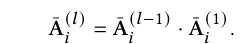
이는 \( \bar{A}(𝑙)_{𝑖} \)를 \( \bar{A}(1)_{𝑖} \)의 \( 𝑙 \)번의 행렬 곱셈으로 반환한다. 따라서, \( [\bar{A}(𝑙)_{𝑖}]_{𝑚𝑛} \)은 노드 \( 𝑚 \)에서 노드 \( 𝑛 \)으로의 \( 𝑙 \)-홉 경로의 수를 기록한다. 이러한 방식으로 우리는 몇 개의 GNN 레이어가 사용되든 각 아이템 \( 𝑣𝑖 \)에 대해 하나의 인접 행렬(\( \bar{A}(1)_{𝑖} \))만 유지하면 되므로 파라미터 크기를 줄일 수 있다.
추가로, 인접 행렬을 다음 단계로 정제한다:
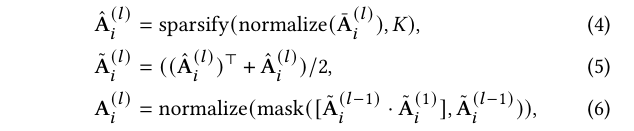
여기서 \( \text{normalize}(·) \)는 행렬의 모든 요소를 [0, 1] 범위로 스케일링하고, 행렬의 대각 요소를 직접 1로 설정하는 최소-최대 정규화를 적용한다. \( \text{sparsify}(·, 𝐾) \)는 가장 큰 𝐾개의 요소를 유지하고 나머지를 0으로 설정하며, \( \text{mask}(·, \tilde{A}(𝑙-1)_{𝑖}) \)는 \( \tilde{A}(𝑙-1)_{𝑖} \)에서 0인 모든 요소를 \( \tilde{A}(𝑙)_{𝑖} \)에서도 0으로 설정한다. (4)에서 (6)까지 우리는 (4)를 통해 밀집된 \( \bar{A}(𝑙)_{𝑖} \)를 희소화하여 밀접하게 관련된 특징들만 연결되도록 한다. 또한 \( ⊙ \)의 교환 법칙 덕분에 (5)를 통해 \( \hat{A}(𝑙)_{𝑖} \)를 대칭 행렬로 변환한다.
위에서 언급한 고려 사항 외에도, 저차 특징 그래프에서 연결되지 않은 노드가 고차 특징 그래프에서도 연결되지 않기를 기대한다. 예를 들어, \( 𝑙 \)번째 GNN 레이어에서 노드 \( 𝑛2 \)에서 노드 \( 𝑛1 \)로 메시지가 전달되지 않으면, \( 𝑛2 \)의 메시지는 더 높은 GNN 레이어에서도 \( 𝑛1 \)로 전달되지 않을 것이다. 따라서 (6)를 적용하여 최종 \( A(𝑙)_{𝑖} \)를 얻는다.
4.3 아이템별 특징 그래프에서의 맞춤형 메시지 전달 프로세스 학습된 아이템별 특징 그래프를 사용하여, 임의 차수의 특징 상호작용을 포착할 수 있도록 설계된 맞춤형 메시지 전달 프로세스를 갖춘 GNN을 사용하며, 이를 최종 CTR 예측에 명시적으로 결합한다.
메시지 전달의 일반적인 메커니즘을 먼저 설명한다. 𝑙번째 GNN 레이어에서 특징 𝑓𝑚의 노드 임베딩 h(𝑙)_𝑚 는 다음과 같이 업데이트된다:
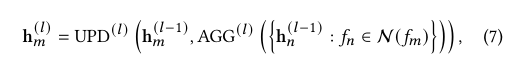
여기서 UPD(𝑙)는 𝑓_{𝑚}의 노드 임베딩을 h(𝑙)_𝑚 로 업데이트하고, AGG{(𝑙)}(·)는 인접 노드들의 임베딩을 집계하며, N(𝑓_{𝑚})는 특징 𝑓_{𝑚}에 대응하는 노드의 인접 노드들을 포함한다. 초기 노드 임베딩 h^{(0)}_{𝑚}는 e_{𝑚}이다. 𝑁_𝑙개의 레이어가 지난 후, 노드 임베딩 h_{𝑚} = h^{(𝑁_𝑙)}_{𝑚}이 최종 특징 표현으로 반환된다.
EmerG에서는 (7)을 다음과 같이 실현한다:
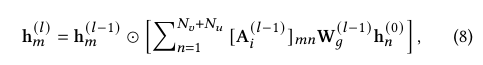
여기서 ⊙ 는 요소별 곱셈을 나타내며, A(𝑙−1)_i는 (6)에 의해 얻어진 아이템별 최종 인접 행렬이고, W^{(𝑙-1)}_{𝑔}는 학습 가능한 파라미터이다. 기존의 GNN [15, 17, 39]과 달리, 우리는 h^{(𝑙-1)}_{𝑚}을 h^{(0)}_{𝑛}와 집계하여, Proposition 4.1이 보여주듯이 𝑙−1번째 GNN 레이어의 출력이 𝑙차 특징 상호작용을 포착하게 한다. 이를 통해 EmerG는 임의 차수의 특징 상호작용을 명시적으로 모델링할 수 있다.
Proposition 4.1 (EmerG의 유효성):
(8)에서 정의된 맞춤형 메시지 전달 프로세스로 (𝑙−1)번째 GNN 레이어는 𝑙 차 특징 상호작용을 포착한다.
증명은 Appendix A.1에 있다. 잔차 연결을 GNN에 통합하여 임의 차수의 특징 상호작용을 모델링할 수 있지만, Appendix A.2에서 분석한 바와 같이 잔차 연결을 도입하면 최대 특징 상호작용 차수가 크게 증가한다.
다양한 차수의 특징 상호작용과 함께, 각 노드 𝑓_{𝑚}의 모든 노드 임베딩을 다중 헤드 주의 메커니즘을 통해 명시적으로 결합하여 업데이트된 노드 임베딩 hat{H}_{𝑚}을 생성한다:

여기서 H_{𝑚} = [h^{(0)}_{𝑚}; ldots; h^{(𝑁_𝑙)}_{𝑚}] \)은 길이 𝑁_𝑑 \)의 𝑁_𝑙 개의 행 벡터를 포함하며, 𝑁_ℎ는 주의 헤드의 수이다. 그 다음, \( 𝑁_𝑣 + 𝑁_𝑢 \)개의 특징 각각에 대해 기여 요인을 다음과 같이 추정한다:
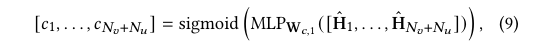
여기서 {MLP}_{𝑊_𝑐,1}은 𝑊_𝑐,1로 매개변수화된 다층 퍼셉트론이다. 마지막으로 아이템 𝑣와 사용자 𝑢가 상호작용할지를 예측한다:
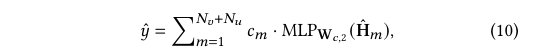
여기서 \( 𝑊_𝑐,2 \)는 학습 가능한 파라미터이다.
4.4 학습 및 추론




5 EXPERIMENTS
5.1 Experimental Settings
데이터셋
두 가지 벤치마크 데이터셋을 사용한다: (i) MovieLens [11]: MovieLens에서 100만 개의 상호작용 기록을 포함하는 데이터셋으로, 아이템 특징에는 영화 ID, 제목, 출시 연도, 장르가 포함되며, 사용자 특징에는 사용자 ID, 나이, 성별, 직업, 우편번호가 포함된다. (ii) Taobao [29]: Taobao에서 2600만 개의 광고 클릭 기록을 포함하는 데이터셋으로, 아이템 특징에는 광고 ID, 위치 ID, 카테고리 ID, 캠페인 ID, 광고주 ID, 브랜드, 가격이 포함되며, 사용자 특징에는 사용자 ID, 마이크로 그룹 ID, cms_group_id, 성별, 나이, 소비 등급, 쇼핑 깊이, 직업, 도시 수준이 포함된다. 기존 연구 [24, 42]를 따라 MovieLens의 평점을 이진화하여, 평점이 4 미만인 경우 0으로, 나머지는 1로 설정한다.
데이터 분할
공개된 데이터 분할 방식을 사용하며 [24, 42, 45], 아이템을 등장 빈도에 따라 그룹화한다: (i) 과거 아이템, 즉 MovieLens에서는 200회 이상, Taobao에서는 2000회 이상 상호작용이 발생한 아이템들, (ii) 새로운 아이템, 즉 상호작용 횟수가 N 이하이고 3𝐾보다 큰 아이템들로, 여기서 K는 MovieLens에서는 20, Taobao에서는 500으로 설정된다. 새로운 아이템이 점차 더 많은 사용자에게 클릭되는 동적 과정을 모방하기 위해, 새로운 아이템과 관련된 상호작용 기록을 타임스탬프 순서대로 정렬한다. 세 번의 연속적인 웜업 단계를 고려하며, 각각 A, B, C로 레이블을 붙인다. 각 단계에서는 각 아이템에 대해 K개의 새로운 상호작용 기록 세트를 도입하며, 나머지 상호작용 기록은 평가를 위한 테스트 데이터로 구성된다.
실험 파이프라인
기존 연구의 파이프라인을 채택하여 [24, 42, 45], 모델이 시간이 지남에 따라 새로운 아이템에 어떻게 적응하는지 평가한다. 먼저 과거 아이템 인스턴스를 사용해 모델을 사전 학습하고, 새로운 아이템의 테스트 데이터에서 모델 성능을 직접 평가하여 콜드 스타트 단계의 성능을 확인한다. 이후, 연속적인 웜업 단계에서 일부 훈련 데이터를 학습하면서 모델 성능을 측정한다. 특히 웜업 단계 A, B, C의 훈련 데이터를 사용하여 순차적으로 모델을 업데이트하고, 업데이트된 모델의 테스트 데이터 성능을 평가한다.
평가 지표
기존 연구 [42]를 따라 성능은 다음 두 가지 지표로 평가한다: (i) 곡선 아래 면적(AUC) [19], 이는 분리 가능성의 정도를 나타내며, (ii) F1 점수 [13], 이는 정밀도와 재현율의 조화 평균이다. AUC와 F1 모두 0(최악)에서 1(최상) 사이의 값을 가진다.
5.2 Performance Comparison
제안된 EmerG를 다음 네 그룹의 기준 방법들과 비교한다:
- A. 일반 CTR 백본: 과거 아이템 인스턴스를 사용해 사전 학습하고, 새로운 아이템 인스턴스로 미세 조정하는 방식으로, DeepFM [9], Wide&Deep [5], AutoInt [40], AFN [6], Fi-GNN [17], 최근의 FinalMLP [21] 및 FINAL [44]이 포함된다.
- B. 상호작용 기록이 없는 새로운 아이템을 위한 방법: DropoutNet [31]과 ALDI [12]가 포함된다.
- C. 일부 상호작용 기록이 있는 새로운 아이템을 위한 방법: MeLU [16], MAMO [7], TaNP [18], ColdNAS [37]이 포함된다. 이러한 방법들은 새로운 아이템 인스턴스를 동적으로 통합하지 못하므로, 웜업 단계 A, B, C에서 제공된 훈련 상호작용 기록을 수용하기 위해 단계적 접근을 채택한다. 먼저, A 단계에서 \( K \)개의 상호작용 기록을 지원 세트로 사용하여 테스트 성능을 평가한다. 이후 A와 B 단계의 \( 2K \) 기록을 결합하여 두 번째 평가를 수행하고, 마지막으로 세 웜업 단계(A, B, C)의 \( 3K \) 기록을 포함하여 세 번째 평가를 진행한다.
- D. 점진적으로 상호작용 기록이 증가하는 새로운 아이템을 위한 방법: 이 방법들은 우리의 방법과 가장 관련성이 높으며, 기존 연구들은 일반 CTR 백본에 새 아이템의 ID 임베딩을 생성하고 웜업하는 기능을 추가하여 MetaE [24], MWUF [45], GME [23], CVAR [42] 등이 포함된다. 우리는 DeepFM을 CTR 백본으로 사용한다. 이러한 방법을 다른 백본과 결합한 결과는 부록 C.1에 보고된다.
각 비교 방법은 해당 저자의 공개 코드를 사용해 구현되었다. 더 자세한 구현 사항은 부록 B에 제공된다.
콜드 스타트 및 웜업 단계 성능
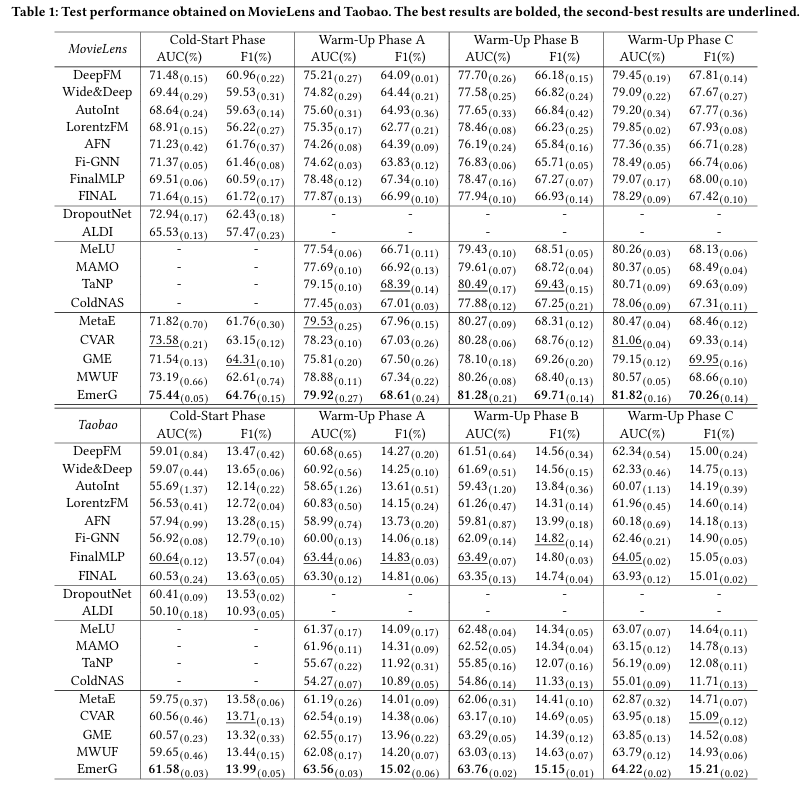
Table 1은 결과를 보여준다. 콜드 스타트 및 웜업 단계에 맞춰 설계된 콜드 스타트 방법들이 대체로 더 나은 성능을 보인다. EmerG는 모든 네 단계에서 일관되게 최고의 성능을 발휘하며, 하이퍼네트워크가 아이템별 특징 상호작용을 포착하는 효과를 검증한다. N-way K-shot 설정의 few-shot 방법들은 웜업 단계 A에서 좋은 성능을 얻지만, 샘플 수가 증가함에 따라 완전한 재훈련 없이 더 높은 성능을 달성하지 못한다. 훈련 세트를 사용해 미세 조정하는 일반 CTR 백본들은 상대적으로 낮은 성능을 보이며, 이 중 FinalMLP가 가장 잘 수행된다. 이 방법들은 새 아이템에 대한 아이템별 파라미터를 무작위로 초기화하므로, 사전 학습된 모델을 소수의 새 아이템 인스턴스만으로 미세 조정하는 것은 좋은 성능을 얻기에 충분하지 않다. 특히, 아이템-사용자별 특징 상호작용 그래프를 사용하는 GNN 기반 CTR 모델 Fi-GNN은 성능이 낮은데, 이는 자유도가 너무 높아 콜드 스타트 및 웜업 단계에서 특징 상호작용 패턴을 포착하는 데 불리함을 나타낸다. EmerG에서는 하이퍼네트워크를 사용하여 아이템별 특징 그래프를 생성하고, 이를 임의 차수의 특징 상호작용을 포착할 수 있는 맞춤형 메시지 전달 메커니즘을 가진 GNN이 처리하며, 메타 학습 전략을 통해 파라미터를 최적화한다. 이러한 설계 고려 사항들은 EmerG의 최고의 성능에 기여한다. 계산 오버헤드 측면에서도 EmerG는 시간과 자원 면에서 상대적으로 효율적이다. 자세한 비교는 부록 C.2에 있다.
충분한 훈련 샘플이 주어진 경우 성능
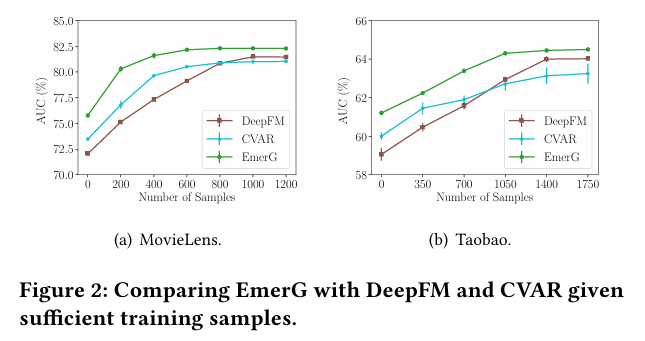
EmerG가 새로운 아이템에 대해 충분한 훈련 샘플이 있을 때 어떻게 수행하는지, 특히 전통적인 CTR 백본과 비교하여 확인한다. 여기서 우리는 새로운 아이템의 원래 테스트 샘플 중 일부를 사용하여 실험 파이프라인에 더 많은 훈련 샘플을 추가하고, 더 작은 테스트 세트에서 성능을 평가한다. Table 1에서 CTR 백본과 few-shot 방법 중 가장 잘 수행하는 기준들과 EmerG를 비교한다. Figure 2는 훈련 샘플 수에 따른 테스트 AUC(%)를 보여주며, 테스트 F1(%)로 측정된 실험 결과도 유사하다. 모든 방법이 더 많은 훈련 샘플을 사용할수록 성능이 향상되며, 전통적인 CTR 백본인 DeepFM이 새 아이템 ID 임베딩을 생성하기 위한 추가 모듈을 갖춘 CVAR보다 점진적으로 우수한 성능을 보인다. 반면 EmerG는 모든 경우에서 일관되게 최고의 성능을 발휘하며, 다른 방법들보다 더 나은 성능으로 수렴한다. 이는 EmerG가 아이템별 특징 상호작용을 다양한 차수로 효과적으로 포착할 수 있음을 검증한다.
5.3 ModelAnalysis
5.3.1 제거 연구. 제안된 EmerG를 다음과 같은 변형들과 비교한다: (i) **w/random graph**는 (8)에서 인접 행렬 \( A^{(1)} \)을 무작위로 생성한다; (ii) **w/o sparsification**은 (4)를 적용하여 인접 행렬을 희소화하지 않는다; (iii) **w/o mask**는 (6)를 적용하여 저차 특징 그래프에서 연결되지 않은 노드들이 고차 특징 그래프에서도 연결되지 않도록 강제하지 않는다; (iv) **w/shared graph**는 모든 아이템에 대해 글로벌 공유 인접 행렬을 사용하는 반면, EmerG는 아이템별 인접 행렬을 사용한다; (v) **w/o meta**는 과거 아이템에서 GNN과 하이퍼네트워크를 학습하지만, 작업을 구성하거나 메타 학습 전략을 사용하지 않는다; (vi) **w/o inner**는 \( \phi_{𝑖} \)를 직접 사용하고 각 작업 내에서 이를 \( \phi'_{𝑖} \)로 업데이트하지 않는다.
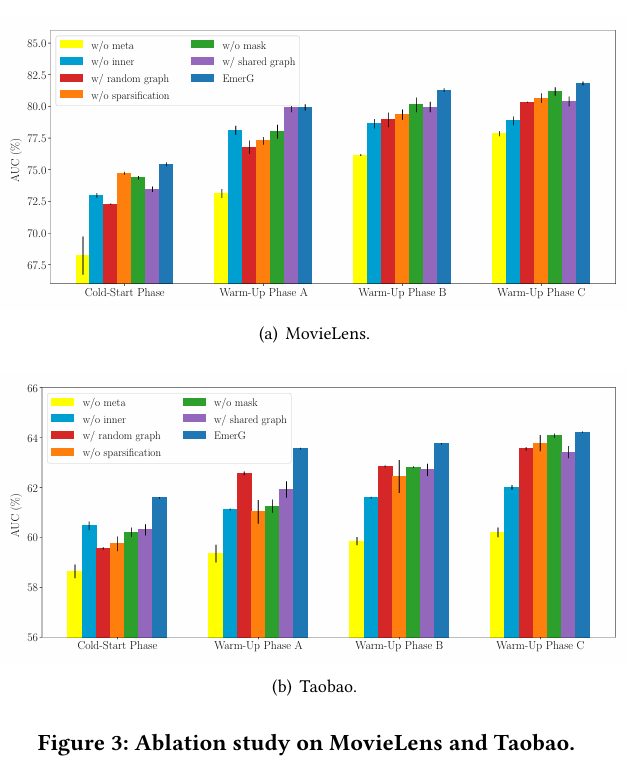
Figure 3은 결과를 보여준다. "w/random graph"는 EmerG보다 낮은 성능을 보여주며, 하이퍼네트워크에 의해 생성된 아이템별 특징 그래프가 의미가 있음을 나타낸다. EmerG가 "w/o sparsification"보다 성능이 더 좋은 것은 밀접하게 관련된 노드들만 연결된 희소 특징 그래프가 GNN 모델이 유용한 메시지에 집중하도록 할 수 있음을 보여준다. "w/o mask"와 EmerG를 비교했을 때, 성능 저하는 (6)에서의 가정이 유효함을 검증하며, mask 연산은 인접 행렬이 지나치게 밀집되는 것을 방지하여 불필요한 특징 상호작용을 가지치기하고 더 나은 설명 가능성을 제공하는 데 도움이 된다. "w/shared graph"가 EmerG보다 낮은 성능을 보이는 것도 관찰할 수 있다. 이는 글로벌 공유 인접 행렬을 사용해서는 다양한 사용자와 아이템 간의 상호작용 패턴을 포착할 수 없음을 입증한다. 마지막으로, EmerG가 "w/o meta"와 "w/o inner"를 능가하며, 이는 작업 간의 메타 학습과 각 작업 내의 업데이트가 필요함을 강조한다.
5.3.2 GNN 레이어 수의 영향. Proposition 4.1에서 설명한 바와 같이, GNN의 메시지 전달 프로세스를 맞춤화하여 \( 𝑙 \)번째 레이어가 \( 𝑙 \)차 특징 상호작용을 포괄하도록 했다. 또한, 하이퍼네트워크가 제공한 초기 행렬에서 후속 GNN 레이어의 인접 행렬을 직접 생성함으로써 이 과정을 최적화했다. 이 접근 방식은 아키텍처를 간소화할 뿐 아니라 추가 레이어로 확장이 용이하며, 이를 통해 고차 특징 상호작용을 쉽게 포착할 수 있다. 이와 같은 맥락에서, 다양한 데이터셋에서 GNN 레이어 수가 성능에 미치는 영향을 조사한다.
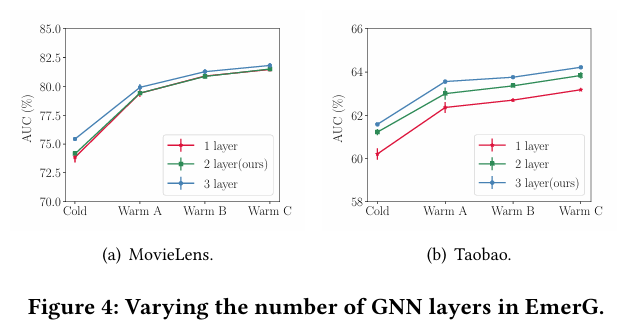
Figure 4는 결과를 보여준다. EmerG는 데이터셋에 따라 다른 레이어 수에서 최상의 성능을 얻는다: MovieLens에서는 GNN 레이어 2개를 사용한 EmerG가 최고의 성능을 보이며, Taobao에서는 GNN 레이어 3개를 사용한 EmerG가 최고의 성능을 보인다. 이는 데이터셋에 따라 필요한 GNN 레이어 수가 다르며, Taobao와 같은 대규모 데이터셋은 MovieLens와 같은 소규모 데이터셋보다 더 고차 특징이 필요할 수 있음을 보여준다. EmerG는 이러한 요구 사항을 쉽게 충족할 수 있도록 설계되었다.
5.3.3 다양한 특징 상호작용 함수. 다양한 특징 상호작용 함수를 사용하는 것을 고려한다. Table 2는 결과를 보여준다. 보시다시피, 요소별 곱셈(element-wise product)을 사용하는 것이 가장 좋은 성능을 내며, 이는 EmerG에서 채택된 방식이다.
5.4 CaseStudy
마지막으로, MovieLens에서 영화 *Lawnmower Man 2: Beyond Cyberspace*와 영화 *Waiting to Exhale*를 새로운 아이템으로 선택하여, 아이템별 특징 그래프를 기록하는 인접 행렬을 Figure 5에 시각화한다.
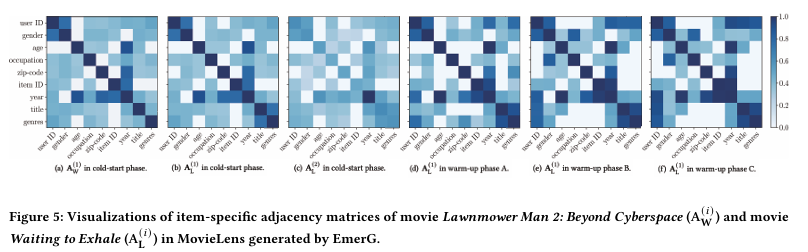
보시다시피, EmerG는 서로 다른 아이템에 대해 서로 다른 작업별 특징 그래프를 학습한다. Figure 5(a)와 Figure 5(b)를 비교하면, *Lawnmower Man 2: Beyond Cyberspace*에는 특히 중요한 2차 특징 상호작용 ⟨장르, 제목⟩이 있음을 알 수 있다. *Lawnmower Man 2: Beyond Cyberspace*의 장르는 공상 과학이며, *Waiting to Exhale*의 장르는 코미디이다. 공상 과학 장르의 경우, 제목이 종종 세계관이나 주제를 반영하여 사람들이 흥미를 느낄지 판단하는 데 중요한 역할을 한다. 반면, 코미디 작품의 경우 제목이 재미와 무관할 때가 많다.
또한 EmerG는 의미 있는 고차 특징 상호작용도 포착할 수 있다. 예를 들어, ⟨연도, 나이⟩와 ⟨연도, 우편번호⟩는 중요한 2차 특징 상호작용으로서, 3차 특징 상호작용인 ⟨연도, 나이, 우편번호⟩를 발견하는 데 기여한다. Figure 5(c)에서 연도, 나이, 우편번호 노드 간의 관계는 모두 상대적으로 중요해졌으며, 특히 Figure 5(b)에서는 중요하지 않았던 ⟨나이, 우편번호⟩가 중요한 상호작용으로 떠오른다. 이는 영화의 연도가 그 영화를 볼 가능성이 높은 사람들의 나이를 결정한다는 점에서 이해할 수 있다. 예를 들어, 노년층은 일반적으로 오래된 영화를 선호한다. 이와 별개로, 우편번호로 나타내는 지역 위치도 중요한 역할을 한다. 예를 들어, 개발된 지역의 사람들은 새로운 것에 더 개방적일 가능성이 크다. 따라서 지역이 바뀌면 같은 영화를 좋아하는 사람들의 나이대가 달라질 수 있으며, 이는 학습된 3차 특징 상호작용의 유효성을 검증해준다.
우리는 또한 하이퍼네트워크가 생성한 아이템별 특징 그래프가 새로운 아이템의 학습 샘플을 보지 않아도 특징 간의 상호작용을 대략적으로 포착할 수 있음을 관찰할 수 있다. 웜업 단계에서의 학습 세트를 사용하여 지속적으로 최적화되지만, 변화는 급격하지 않다. 예를 들어, Figure 5(b)와 Figure 5(d)에서 Figure 5(f)까지의 2차 특징 상호작용 패턴은 유사하며, 학습 샘플에 맞게 약간의 변화만 보인다. 종합적으로, EmerG는 다양한 차수에서 아이템별 특징 상호작용을 포착할 수 있는 합리적인 인접 행렬을 학습할 수 있음을 결론지었다.
6 CONCLUSION
본 연구에서는 특징 상호작용의 중요성을 강조하며, EmerG라는 새로운 솔루션을 제안하여, 아이템별 고유의 상호작용 패턴을 포착함으로써 점진적으로 상호작용 기록이 축적되는 새로운 아이템에 대한 CTR 예측을 효과적으로 수행할 수 있도록 했다. 우리의 접근 방식은 하이퍼네트워크를 활용하여 아이템별 특징 그래프를 구축하며, 여기서 노드는 특징을 나타내고 엣지는 그들의 상호작용을 나타내어, 각 아이템의 복잡한 상호작용 패턴을 모델이 인식할 수 있도록 한다. 우리는 모든 차수의 특징 상호작용을 포착할 수 있도록 설계된 메시지 전달 과정을 갖춘 그래프 신경망(GNN)을 결합하여 정확한 CTR 예측을 가능하게 한다. 데이터가 부족한 상황에서 과적합을 방지하기 위해, 다양한 아이템 CTR 예측 작업에 대해 하이퍼네트워크와 GNN의 파라미터를 세밀하게 조정하는 메타 학습 전략을 도입하였으며, 각 작업에서 아이템별 파라미터에 최소한의 수정만 필요하도록 했다. 실제 데이터셋에 대한 실험 결과, EmerG는 상호작용 기록이 전혀 없거나 일부 있는 경우, 혹은 상당한 양의 상호작용이 있는 경우에도 CTR 예측에서 최첨단 성능을 달성하는 것으로 나타났다. 우리는 이러한 접근 방식이 향후 의약품 추천과 같은 다른 애플리케이션에서도 콜드 스타트 문제를 완화하는 데 사용될 수 있을 것으로 기대한다.
'AI' 카테고리의 다른 글
ABSTRACT
추천 시스템에서는 새로운 아이템이 지속적으로 도입되며, 초기에는 상호작용 기록이 부족하지만 시간이 지남에 따라 점차 쌓이게 된다. 이러한 아이템의 클릭률(CTR)을 정확하게 예측하는 것은 수익과 사용자 경험을 향상하는 데 중요하다. 기존 방법들은 일반적인 CTR 모델 내에서 새로운 아이템의 ID 임베딩을 향상하는 데 중점을 두지만, 전역적인 특징 상호작용 접근 방식을 채택하는 경향이 있어 상호작용이 풍부한 아이템이 상호작용이 적은 새 아이템을 압도하는 경우가 많다. 이에 대응하여, 우리의 연구는 아이템별 특징 상호작용 패턴을 학습하여 콜드 스타트 CTR 예측을 강화하는 EmerG라는 새로운 접근 방식을 소개한다. EmerG는 하이퍼네트워크를 활용하여 아이템 특성에 기반한 아이템별 특징 그래프를 생성하며, 이 그래프는 그래프 신경망(GNN)에 의해 처리된다. 이 GNN은 특정 메시지 전달 메커니즘을 통해 모든 차수에서 특징 상호작용을 포착할 수 있도록 특별히 설계되었다. 우리는 하이퍼네트워크와 GNN의 매개변수를 다양한 아이템 CTR 예측 작업에서 최적화하는 메타 학습 전략을 설계하여 각 작업에서 최소한의 아이템별 매개변수만 조정한다. 이 전략은 제한된 데이터로 인한 과적합 위험을 효과적으로 줄인다. 벤치마크 데이터셋에 대한 광범위한 실험을 통해 EmerG가 새 아이템이 없거나, 적거나, 충분히 있는 경우에도 일관되게 최고의 성능을 보임을 확인하였다.
1 INTRODUCTION
콜드 스타트 문제는 추천 시스템에서 중요한 도전 과제로 나타나며, 특히 새로운 아이템이 사용자 상호작용이 없는 상태(콜드 스타트 단계)에서 몇 번의 초기 클릭을 얻는 상태(웜업 단계)로 전환할 때 두드러진다. 복잡한 특징 상호작용을 포착할 수 있는 딥러닝 모델은 클릭률(CTR) 예측을 개선하는 데 유망한 것으로 입증되었으며, 이는 다양한 아이템(예: 영화, 상품, 음악)에 대한 사용자 참여 가능성을 평가하는 중요한 지표이다. 그러나 이러한 모델은 최적의 성능을 달성하기 위해 방대한 데이터셋에 의존하는 경향이 있으며, 이는 콜드 스타트와 웜업 단계에서 제약이 된다. 모델의 상당한 매개변수 크기는 상호작용 기록이 제한된 이러한 단계에 효과적으로 적응하는 데 어려움을 초래하여 CTR 예측의 정확도를 높이고 비용을 들이지 않고 모델을 업데이트하는 데 어려움이 된다.
최근 연구들은 추천 시스템에서 아이템 콜드 스타트 문제를 완화하기 위한 전략으로 아이템 ID 임베딩의 초기화를 개선하는 데 중점을 두었으며, 웜업 단계에서 상호작용 기록이 제공되면 이를 통해 후속 업데이트를 수행한다. 이후 일반적인 CTR 백본을 활용하여 추가 처리를 수행한다. 그러나 이들은 중요한 측면을 간과하고 있다: 사용자와 아이템 간의 특징 상호작용 패턴의 독특함이다. 이러한 간과는 사용자-아이템 상호작용의 미묘한 역학을 완전히 포착하는 능력을 제한하며, 개인화된 추천이 중요한 시나리오에서 CTR 예측의 정확성과 효율성에 잠재적인 영향을 미칠 수 있다. 예를 들어, 고가의 럭셔리 아이템과 저가의 일상 필수품을 비교할 때 상호작용 패턴이 뚜렷하게 다르다. 고가의 럭셔리 아이템의 경우, 아이템의 가격과 사용자의 소득 수준 간의 상호작용이 결정적이다. 특히, 가격과 소득이라는 2차 특징 상호작용은 사용자가 해당 아이템을 구매할 의사를 결정하는 데 중요한 요소가 될 수 있다. 반면, 저가의 일상 필수품의 경우 소득 수준이 구매 결정에 미치는 영향은 줄어든다. 이러한 경우에는 사용자 나이와 아이템 카테고리 간의 상호작용과 같은 다른 특징 상호작용이 상대적으로 더 중요해진다. 이와 같은 차이는 아이템별 특징 상호작용 패턴을 모델링하는 필요성을 강조한다. 기존 연구들은 모두 사용자와 아이템 간의 전역적인 특징 상호작용 패턴을 학습하며, 이는 제한된 상호작용 기록을 가진 새 아이템을 풍부한 상호작용 기록을 가진 기존 아이템이 압도하게 한다.
특징 상호작용의 중요한 역할을 인식하여, 우리는 EmerG를 통해 새롭게 등장하는 아이템의 CTR 예측 문제를 해결하고자 하며, 상호작용 데이터가 점차적으로 증가하는 과정(상호작용 기록이 없는 단계에서 일부 기록이 있는 단계, 그리고 풍부한 기록을 가지는 단계로 발전)을 아이템별 특징 그래프 학습을 통해 다룬다. 우리의 기여는 다음과 같이 요약된다:
- 우리는 아이템별 특징 상호작용을 강조하는 독창적인 방법을 제안하여, 방대한 데이터를 가진 기존 아이템이 새로운 아이템을 압도하는 문제를 해결하며, CTR 예측의 문제를 해결한다. 하이퍼네트워크를 활용하여 특징을 노드로 하고 상호작용을 엣지로 하는 아이템별 특징 그래프를 구성하여 각 아이템에 고유한 복잡한 상호작용 패턴을 포착한다. 우리는 사용자 정의된 메시지 전달 과정을 갖춘 그래프 신경망(GNN)을 사용하여 모든 차수의 특징 상호작용을 포착할 수 있도록 설계하여, 이를 복잡하고 정확한 예측에 결합할 수 있게 한다.
- 제한된 데이터로 인해 발생하는 과적합을 완화하기 위해, 하이퍼네트워크와 GNN의 매개변수를 다양한 아이템 CTR 예측 작업에서 최적화하는 메타 학습 전략을 채택하며, 각 작업 내에서 최소한의 아이템별 매개변수만을 조정한다. 또한, 이러한 방식으로 학습된 하이퍼네트워크와 GNN은 각 작업에 쉽게 일반화될 수 있다.
- 우리는 벤치마크 데이터셋에 대한 광범위한 실험을 수행하여 EmerG가 새롭게 등장하는 아이템의 CTR 예측에서 최고의 성능을 발휘함을 확인하였다. 더 많은 학습 데이터를 제공한 경우에도 EmerG는 일관되게 최고의 성능을 나타냈다. 아이템별 특징 그래프를 기록하는 인접 행렬의 시각화는 EmerG가 아이템별 특징 상호작용을 올바르게 학습할 수 있음을 보여준다.
2 RELATED WORKS
CTR 예측에서 새로 등장한 아이템과 관련된 네 가지 방법군을 간략히 검토한다.
A. General CTR Models.
일반 CTR 모델은 저평가된 아이템을 우선시하지 않고 보편적으로 적용된다. 이 모델들은 CTR 예측 정확도를 높이는 데 중요한 복잡한 특징 상호작용을 모델링하는 데 주로 중점을 둔다 [3]. 이 분야의 발전은 로지스틱 회귀와 같은 선형 모델이 1차 상호작용을 포착하는 것에서 시작하여 [27], Factorization Machines(FM)이 2차 상호작용을 모델링하고 [26], 고차 FM(HOFM)이 고차 상호작용을 다루는 방향으로 진행되었다 [2]. 다양한 딥러닝 모델들은 이러한 복잡한 패턴을 자동으로 학습한다. Wide&Deep [5]와 DeepFM [9]은 2차 및 고차 상호작용을 다루기 위해 하이브리드 아키텍처를 채택한다. DIN [43]은 주의 메커니즘을 통해 사용자 관심사를 동적으로 포착하여 변화하는 광고 특징에 적응한다. AutoInt [28]는 멀티 헤드 셀프 어텐션 메커니즘 [30]을 도입하여 고차 특징 상호작용을 모델링한다. LorentzFM [40]은 파라미터 크기를 줄이기 위해 하이퍼볼릭 공간에서 특징 상호작용을 탐색한다. AFN [6]은 학습될 계수로 각 특징의 세기를 변환한다. FinalMLP [21]는 병렬로 구성된 두 개의 MLP 네트워크를 사용하여 특징 선택과 상호작용 집계 레이어를 갖추고 있다. FINAL [44]은 특징 상호작용 학습의 기하급수적 성장을 위한 분해된 상호작용 레이어를 도입한다. 특징 상호작용을 사용자 및 아이템 특징을 나타내는 노드로 구성된 그래프로 개념화할 수 있다는 점을 고려하여 그래프 신경망(GNN)이 사용된다 [15]. Fi-GNN [17]은 특징 임베딩 간의 유사성을 기준으로 엣지를 설정하여 특징 그래프 생성을 학습한다. FIVES [39]는 대규모 CTR 데이터셋에서 차별화된 검색을 통해 엣지를 설정하여 글로벌 특징 그래프를 학습하며, 이는 제한된 데이터로 인해 새 아이템이 저평가될 수 있다. GMT [22]는 아이템, 사용자 및 그 특징 간의 상호작용을 대규모 이종 그래프로 모델링한 후, 예측을 위해 타겟 사용자-아이템 쌍의 로컬 이웃을 제공한다. 그러나 이러한 일반적인 CTR 모델들은 대규모 데이터셋을 위해 설계되었기 때문에 콜드 스타트 및 웜업 단계에서 과적합 문제가 발생할 수 있다. EmerG는 다양한 CTR 작업에서 학습된 하이퍼네트워크를 통해 생성된 아이템별 특징 그래프를 사용하는 특화된 GNN을 도입하여 새로운 아이템에 대해 최소한의 매개변수 조정을 통해 특징 상호작용을 정확하게 모델링할 수 있다.
B. Methods for New Items without Interaction Records.
몇몇 방법들은 새로운 아이템이 상호작용 기록이 없는 콜드 스타트 단계에서 기존 아이템의 모델 성능을 유지하면서도 이러한 아이템에 중점을 두어 다룬다. DropoutNet [31]은 입력 샘플에 드롭아웃 메커니즘을 적용하여 결측 데이터를 추론하는 신경망을 학습한다. Heater [46]는 다중 게이트 전문가 혼합 접근 방식을 사용하여 아이템 임베딩을 생성한다. GAR [4]는 생성자와 추천자 사이의 적대적 학습 전략을 사용하여 기존 임베딩 분포를 모방하는 새로운 아이템 임베딩을 생성하여 추천 시스템을 속인다. ALDI [12]는 기존 아이템의 행동 정보를 새로운 아이템으로 이전하는 것을 학습한다. 그러나 이러한 방법들은 새로운 아이템에 대한 상호작용 기록의 수용을 고려하지 않으며, 이러한 아이템의 진화하는 상호작용 기록에 맞추기 위해 재훈련이 필요하다.
C. Methods for New Items with A Few Interaction Records.
새 아이템이 몇 가지 인스턴스만을 가지는 웜업 단계에 해당하는 상황에서 few-shot 학습 [35]이 자연스러운 해결책을 제공한다. few-shot 학습은 몇 개의 레이블이 지정된 샘플로 새로운 작업에 일반화하는 것을 목표로 하며, 이미지 분류 [8], 쿼리 의도 인식 [34], 약물 발견 [33, 38, 41]에 적용되었다. CTR 예측의 경우, 기존 연구들은 일반적으로 이를 𝑁-way 𝐾-shot 작업으로 접근하여, 각 새로운 아이템이 𝐾개의 레이블이 지정된 인스턴스와 연관되며, 그 후 고전적인 그래디언트 기반 메타 학습 전략을 사용한다 [8]. MeLU [16]는 그래디언트 하강을 통해 새로운 아이템에 맞추어 모델 매개변수를 선택적으로 조정하는 이 전략을 활용한다. MAMO [7]는 외부 메모리 메커니즘을 통합하여 적응력을 강화한다. MetaHIN [20]은 이질적인 정보 네트워크를 사용하여 사용자와 아이템 간의 풍부한 의미적 관계를 활용한다. PAML [32]은 유사한 사용자들 간의 정보 공유를 촉진하기 위해 사회적 관계를 활용한다. 최근의 접근 방식은 그래디언트 하강을 통한 사용자별 미세 조정에서부터 암묵화된 방법으로 전환하였다. 이러한 방법들은 사용자 상호작용 이력을 사용자별 매개변수로 직접 매핑하여 주요 네트워크를 반복적인 조정 없이 조정한다. TaNP [18]는 아이템 상호작용 기록을 기반으로 아이템별 매개변수를 조정하는 것을 학습한다. ColdNAS [37]는 네트워크 내에서 조정 함수의 최적화를 위해 신경망 구조 검색을 사용한다. 그러나 이러한 방법들은 상호작용 기록이 없는 새로운 아이템을 다루기 어렵고, 추가적인 상호작용 기록이 추가될 때 이를 동적으로 통합하지 못한다.
D. Methods for Emerging Items with Incremental Interaction Records.
산업의 동적 진화를 반영하여 새로운 아이템이 상호작용 기록이 없는 단계에서 몇 개의 기록을 가진 단계, 그리고 풍부한 기록을 가지는 단계로 점진적으로 발전하는 과정을 원활하게 관리하기 위해 모델이 개발되었다. 기존의 노력은 일반 CTR 백본에 대해 아이템 ID 임베딩을 향상시키는 데 주로 초점을 맞추고 있다. MetaE [24]는 그래디언트 기반 메타 학습을 사용하여 임베딩 생성기를 학습한다. MWUF [45]는 불안정한 아이템 ID 임베딩을 메타 네트워크를 사용하여 안정적인 임베딩으로 변환한다. CVAR [42]는 아이템 측면 정보를 기반으로 새로운 아이템 ID 임베딩을 디코딩하여 추가 데이터 처리를 피한다. GME [23]는 기존 아이템의 정보를 활용하여 새로운 아이템 ID 임베딩 생성을 지원한다. 그러나 이러한 방법들은 일반적으로 초기 아이템 ID 임베딩을 최적화하면서 전역적인 특징 상호작용 패턴을 유지하여, 이러한 아이템의 고유한 특성과 상호작용 역학을 포착하는 데 한계가 있다. 반면, EmerG는 하이퍼네트워크의 도움으로 각 아이템에 맞춘 특징 상호작용을 조정함으로써 새로운 아이템의 CTR 예측을 다룬다. 아이템별 특징 상호작용을 학습하여, 방대한 데이터를 가진 기존 아이템이 새 아이템을 압도하는 위험을 줄이고 예측 정확도를 향상시킨다.
3 PROBLEM FOR MULATION
V = {𝑣𝑖}를 아이템 집합으로 두며, 각 아이템 𝑣𝑖는 아이템 ID, 유형, 가격과 같은 𝑁𝑣 개의 아이템 특징과 연관되어 있다. 마찬가지로 U = {𝑢𝑗}를 사용자 집합으로 두며, 각 사용자 𝑢𝑗는 사용자 ID, 나이, 고향과 같은 𝑁𝑢개의 사용자 특징과 연관되어 있다. 사용자가 아이템 𝑣𝑖를 클릭하면 레이블 𝑦𝑖,𝑗 = 1, 그렇지 않으면 𝑦𝑖,𝑗 = 0이 된다. 학습 동안, 예측자는 구 CTR 예측 작업 집합 T_old = 𝑇𝑖_𝑡=1{𝑁𝑡}에서 학습되어 훈련 중 보지 않은 새로운 아이템의 작업을 예측할 수 있도록 일반화된다. 각 작업 T𝑖는 과거 아이템 𝑣𝑖에 대응하며, 기존 상호작용 기록을 포함하는 훈련 세트 S𝑖 = {(𝑣𝑖,𝑢𝑗,𝑦𝑖,𝑗)\}_{𝑗=1}^{𝑁𝑠}와 예측할 상호작용을 포함하는 테스트 세트 Q𝑖 = {(𝑣𝑖,𝑢𝑗,𝑦𝑖,𝑗)\}_{𝑗=1}^{𝑁𝑞}로 구성된다. 𝑁𝑠와 𝑁𝑞는 각각 S𝑖와 Q𝑖에서의 상호작용 수를 나타낸다.
테스트 시에는 상호작용 기록이 없는 새로운 아이템에서 시작해 점차 몇 개의 기록을 모으고 결국 충분한 기록을 쌓게 되는 새로운 아이템의 CTR 예측을 고려한다. 훈련 중 고려되지 않은 새로운 아이템 𝑣𝑘와 연관된 작업 T𝑘에서 다음 세 가지 단계를 다룬다:
- 콜드 스타트 단계: 훈련 세트가 제공되지 않음.
- 웜업 단계: 𝑣𝑘의 일부 상호작용 기록을 포함하는 훈련 세트 S𝑘가 주어진다. 상호작용 기록이 점진적으로 축적되는 여러 웜업 단계를 가질 수 있다.
- 공통 단계: 𝑣𝑘의 훈련 상호작용 기록이 충분히 축적됨.
모든 단계에서 성능은 테스트 세트 Q𝑘에서 평가된다.
4 THE PROPOSED EMERG
특징 상호작용이 중요하다는 기존 이해에 따라, 우리는 각 아이템과 연관된 특징 상호작용 패턴을 통해 아이템의 독특성을 포착하는 EmerG(Figure 1)를 제안한다. EmerG에는 두 가지 주요 구성 요소가 있다: (i) 특징 그래프를 인코딩하는 아이템별 인접 행렬을 생성하는 다양한 작업에서 공유되는 하이퍼네트워크와, (ii) 생성된 아이템별 특징 그래프에서 작동하며 임의 차수의 특징 상호작용을 포착할 수 있도록 특별히 설계된 메시지 전달 메커니즘을 가진 GNN. 콜드 스타트와 웜업 단계를 고려하여, 우리는 다양한 아이템 CTR 예측 작업에서 하이퍼네트워크와 GNN의 매개변수를 최적화하면서 각 작업 내에서 최소한의 아이템별 매개변수만 조정하는 메타 학습 전략을 추가로 설계한다. 이 전략은 제한된 데이터로 인한 과적합 위험을 효과적으로 줄인다.
4.1 Embedding Layer
주어진 인스턴스 (𝑢,𝑣) 에서 임베딩 레이어는 사용자 특징 𝑢와 아이템 특징 𝑣를 밀집 벡터로 매핑한다. 𝑚번째 특징 𝑓𝑚, 𝑚 in [1,𝑁𝑣 +𝑁𝑢]의 특징 임베딩 e𝑚은 다음과 같이 얻어진다:
여기서 𝑾𝑒,𝑚은 𝑚번째 특징에 해당하는 임베딩 행렬을 나타내고, one-hot(𝑓𝑚)은 단일 값 특징 𝑓𝑚의 원-핫 벡터, multi-hot (𝑓𝑚)은 다중값 특징 𝑓𝑚의 멀티-핫 벡터를 나타낸다.
4.2 Item-Specific Feature Graph Generation
우리는 Ha et al. [10]의 전략을 따라 하이퍼네트워크를 활용하여 아이템별 특징 그래프를 생성한다. 하이퍼네트워크는 작은 신경망으로, 더 큰 메인 네트워크의 파라미터를 생성하도록 학습되며, 이들의 통합은 문제에 따라 매우 특화된 도전 과제를 제시한다. EmerG에서는 하이퍼네트워크를 사용하여 첫 번째 GNN 레이어를 위한 아이템별 특징 그래프를 인코딩하는 초기 인접 행렬 A(1)_{𝑖} 을 생성한다. 우리는 후속 GNN 레이어들이 초기 A(1)_{𝑖}에서 인접 행렬을 유도하게 함으로써 저장 효율성을 최적화하면서도 각 아이템에 대한 모델의 특화성을 유지한다.
아이템 𝑣𝑖와 연관된 작업 T𝑖를 고려한다. 아이템 특징 \( 𝑓1, \ldots, 𝑓𝑁𝑣 \)에 대해, 아이템 특징 임베딩은 각각 \( e1,𝑖, \ldots, e𝑁𝑣,𝑖 \)로 표시된다. 특징 그래프 [17, 39]는 각 노드가 특징 𝑓𝑚에 대응하고, 두 노드 간의 엣지가 그들의 상호작용을 기록하는 그래프이다. 하이퍼네트워크는 \( 𝑁𝑣 + 𝑁𝑢 \)개의 서브 네트워크로 구성되며, 첫 번째 GNN 레이어에서 사용될 특징 그래프를 인코딩하는 밀집 아이템별 행렬 \( \bar{A}(1)_{𝑖} \in \mathbb{R}^{(𝑁𝑣+𝑁𝑢) \times (𝑁𝑣+𝑁𝑢)} \)을 생성한다. \( \bar{A}(1)_{𝑖} \)의 \( 𝑚 \)번째 행을 \( [\bar{A}(1)_{𝑖}]_{𝑚:} \)라 하고, 이는 다음과 같이 계산된다:
여기서 \( \text{MLP}_{W𝑎} \)는 파라미터 \( W𝑎 \)를 가진 다층 퍼셉트론(MLP)을 나타낸다. 그 다음 \( \bar{A}(𝑙)_{𝑖} \)를 다음과 같이 생성한다:
이는 \( \bar{A}(𝑙)_{𝑖} \)를 \( \bar{A}(1)_{𝑖} \)의 \( 𝑙 \)번의 행렬 곱셈으로 반환한다. 따라서, \( [\bar{A}(𝑙)_{𝑖}]_{𝑚𝑛} \)은 노드 \( 𝑚 \)에서 노드 \( 𝑛 \)으로의 \( 𝑙 \)-홉 경로의 수를 기록한다. 이러한 방식으로 우리는 몇 개의 GNN 레이어가 사용되든 각 아이템 \( 𝑣𝑖 \)에 대해 하나의 인접 행렬(\( \bar{A}(1)_{𝑖} \))만 유지하면 되므로 파라미터 크기를 줄일 수 있다.
추가로, 인접 행렬을 다음 단계로 정제한다:
여기서 \( \text{normalize}(·) \)는 행렬의 모든 요소를 [0, 1] 범위로 스케일링하고, 행렬의 대각 요소를 직접 1로 설정하는 최소-최대 정규화를 적용한다. \( \text{sparsify}(·, 𝐾) \)는 가장 큰 𝐾개의 요소를 유지하고 나머지를 0으로 설정하며, \( \text{mask}(·, \tilde{A}(𝑙-1)_{𝑖}) \)는 \( \tilde{A}(𝑙-1)_{𝑖} \)에서 0인 모든 요소를 \( \tilde{A}(𝑙)_{𝑖} \)에서도 0으로 설정한다. (4)에서 (6)까지 우리는 (4)를 통해 밀집된 \( \bar{A}(𝑙)_{𝑖} \)를 희소화하여 밀접하게 관련된 특징들만 연결되도록 한다. 또한 \( ⊙ \)의 교환 법칙 덕분에 (5)를 통해 \( \hat{A}(𝑙)_{𝑖} \)를 대칭 행렬로 변환한다.
위에서 언급한 고려 사항 외에도, 저차 특징 그래프에서 연결되지 않은 노드가 고차 특징 그래프에서도 연결되지 않기를 기대한다. 예를 들어, \( 𝑙 \)번째 GNN 레이어에서 노드 \( 𝑛2 \)에서 노드 \( 𝑛1 \)로 메시지가 전달되지 않으면, \( 𝑛2 \)의 메시지는 더 높은 GNN 레이어에서도 \( 𝑛1 \)로 전달되지 않을 것이다. 따라서 (6)를 적용하여 최종 \( A(𝑙)_{𝑖} \)를 얻는다.
4.3 아이템별 특징 그래프에서의 맞춤형 메시지 전달 프로세스 학습된 아이템별 특징 그래프를 사용하여, 임의 차수의 특징 상호작용을 포착할 수 있도록 설계된 맞춤형 메시지 전달 프로세스를 갖춘 GNN을 사용하며, 이를 최종 CTR 예측에 명시적으로 결합한다.
메시지 전달의 일반적인 메커니즘을 먼저 설명한다. 𝑙번째 GNN 레이어에서 특징 𝑓𝑚의 노드 임베딩 h(𝑙)_𝑚 는 다음과 같이 업데이트된다:
여기서 UPD(𝑙)는 𝑓_{𝑚}의 노드 임베딩을 h(𝑙)_𝑚 로 업데이트하고, AGG{(𝑙)}(·)는 인접 노드들의 임베딩을 집계하며, N(𝑓_{𝑚})는 특징 𝑓_{𝑚}에 대응하는 노드의 인접 노드들을 포함한다. 초기 노드 임베딩 h^{(0)}_{𝑚}는 e_{𝑚}이다. 𝑁_𝑙개의 레이어가 지난 후, 노드 임베딩 h_{𝑚} = h^{(𝑁_𝑙)}_{𝑚}이 최종 특징 표현으로 반환된다.
EmerG에서는 (7)을 다음과 같이 실현한다:
여기서 ⊙ 는 요소별 곱셈을 나타내며, A(𝑙−1)_i는 (6)에 의해 얻어진 아이템별 최종 인접 행렬이고, W^{(𝑙-1)}_{𝑔}는 학습 가능한 파라미터이다. 기존의 GNN [15, 17, 39]과 달리, 우리는 h^{(𝑙-1)}_{𝑚}을 h^{(0)}_{𝑛}와 집계하여, Proposition 4.1이 보여주듯이 𝑙−1번째 GNN 레이어의 출력이 𝑙차 특징 상호작용을 포착하게 한다. 이를 통해 EmerG는 임의 차수의 특징 상호작용을 명시적으로 모델링할 수 있다.
Proposition 4.1 (EmerG의 유효성):
(8)에서 정의된 맞춤형 메시지 전달 프로세스로 (𝑙−1)번째 GNN 레이어는 𝑙 차 특징 상호작용을 포착한다.
증명은 Appendix A.1에 있다. 잔차 연결을 GNN에 통합하여 임의 차수의 특징 상호작용을 모델링할 수 있지만, Appendix A.2에서 분석한 바와 같이 잔차 연결을 도입하면 최대 특징 상호작용 차수가 크게 증가한다.
다양한 차수의 특징 상호작용과 함께, 각 노드 𝑓_{𝑚}의 모든 노드 임베딩을 다중 헤드 주의 메커니즘을 통해 명시적으로 결합하여 업데이트된 노드 임베딩 hat{H}_{𝑚}을 생성한다:
여기서 H_{𝑚} = [h^{(0)}_{𝑚}; ldots; h^{(𝑁_𝑙)}_{𝑚}] \)은 길이 𝑁_𝑑 \)의 𝑁_𝑙 개의 행 벡터를 포함하며, 𝑁_ℎ는 주의 헤드의 수이다. 그 다음, \( 𝑁_𝑣 + 𝑁_𝑢 \)개의 특징 각각에 대해 기여 요인을 다음과 같이 추정한다:
여기서 {MLP}_{𝑊_𝑐,1}은 𝑊_𝑐,1로 매개변수화된 다층 퍼셉트론이다. 마지막으로 아이템 𝑣와 사용자 𝑢가 상호작용할지를 예측한다:
여기서 \( 𝑊_𝑐,2 \)는 학습 가능한 파라미터이다.
4.4 학습 및 추론
5 EXPERIMENTS
5.1 Experimental Settings
데이터셋
두 가지 벤치마크 데이터셋을 사용한다: (i) MovieLens [11]: MovieLens에서 100만 개의 상호작용 기록을 포함하는 데이터셋으로, 아이템 특징에는 영화 ID, 제목, 출시 연도, 장르가 포함되며, 사용자 특징에는 사용자 ID, 나이, 성별, 직업, 우편번호가 포함된다. (ii) Taobao [29]: Taobao에서 2600만 개의 광고 클릭 기록을 포함하는 데이터셋으로, 아이템 특징에는 광고 ID, 위치 ID, 카테고리 ID, 캠페인 ID, 광고주 ID, 브랜드, 가격이 포함되며, 사용자 특징에는 사용자 ID, 마이크로 그룹 ID, cms_group_id, 성별, 나이, 소비 등급, 쇼핑 깊이, 직업, 도시 수준이 포함된다. 기존 연구 [24, 42]를 따라 MovieLens의 평점을 이진화하여, 평점이 4 미만인 경우 0으로, 나머지는 1로 설정한다.
데이터 분할
공개된 데이터 분할 방식을 사용하며 [24, 42, 45], 아이템을 등장 빈도에 따라 그룹화한다: (i) 과거 아이템, 즉 MovieLens에서는 200회 이상, Taobao에서는 2000회 이상 상호작용이 발생한 아이템들, (ii) 새로운 아이템, 즉 상호작용 횟수가 N 이하이고 3𝐾보다 큰 아이템들로, 여기서 K는 MovieLens에서는 20, Taobao에서는 500으로 설정된다. 새로운 아이템이 점차 더 많은 사용자에게 클릭되는 동적 과정을 모방하기 위해, 새로운 아이템과 관련된 상호작용 기록을 타임스탬프 순서대로 정렬한다. 세 번의 연속적인 웜업 단계를 고려하며, 각각 A, B, C로 레이블을 붙인다. 각 단계에서는 각 아이템에 대해 K개의 새로운 상호작용 기록 세트를 도입하며, 나머지 상호작용 기록은 평가를 위한 테스트 데이터로 구성된다.
실험 파이프라인
기존 연구의 파이프라인을 채택하여 [24, 42, 45], 모델이 시간이 지남에 따라 새로운 아이템에 어떻게 적응하는지 평가한다. 먼저 과거 아이템 인스턴스를 사용해 모델을 사전 학습하고, 새로운 아이템의 테스트 데이터에서 모델 성능을 직접 평가하여 콜드 스타트 단계의 성능을 확인한다. 이후, 연속적인 웜업 단계에서 일부 훈련 데이터를 학습하면서 모델 성능을 측정한다. 특히 웜업 단계 A, B, C의 훈련 데이터를 사용하여 순차적으로 모델을 업데이트하고, 업데이트된 모델의 테스트 데이터 성능을 평가한다.
평가 지표
기존 연구 [42]를 따라 성능은 다음 두 가지 지표로 평가한다: (i) 곡선 아래 면적(AUC) [19], 이는 분리 가능성의 정도를 나타내며, (ii) F1 점수 [13], 이는 정밀도와 재현율의 조화 평균이다. AUC와 F1 모두 0(최악)에서 1(최상) 사이의 값을 가진다.
5.2 Performance Comparison
제안된 EmerG를 다음 네 그룹의 기준 방법들과 비교한다:
- A. 일반 CTR 백본: 과거 아이템 인스턴스를 사용해 사전 학습하고, 새로운 아이템 인스턴스로 미세 조정하는 방식으로, DeepFM [9], Wide&Deep [5], AutoInt [40], AFN [6], Fi-GNN [17], 최근의 FinalMLP [21] 및 FINAL [44]이 포함된다.
- B. 상호작용 기록이 없는 새로운 아이템을 위한 방법: DropoutNet [31]과 ALDI [12]가 포함된다.
- C. 일부 상호작용 기록이 있는 새로운 아이템을 위한 방법: MeLU [16], MAMO [7], TaNP [18], ColdNAS [37]이 포함된다. 이러한 방법들은 새로운 아이템 인스턴스를 동적으로 통합하지 못하므로, 웜업 단계 A, B, C에서 제공된 훈련 상호작용 기록을 수용하기 위해 단계적 접근을 채택한다. 먼저, A 단계에서 \( K \)개의 상호작용 기록을 지원 세트로 사용하여 테스트 성능을 평가한다. 이후 A와 B 단계의 \( 2K \) 기록을 결합하여 두 번째 평가를 수행하고, 마지막으로 세 웜업 단계(A, B, C)의 \( 3K \) 기록을 포함하여 세 번째 평가를 진행한다.
- D. 점진적으로 상호작용 기록이 증가하는 새로운 아이템을 위한 방법: 이 방법들은 우리의 방법과 가장 관련성이 높으며, 기존 연구들은 일반 CTR 백본에 새 아이템의 ID 임베딩을 생성하고 웜업하는 기능을 추가하여 MetaE [24], MWUF [45], GME [23], CVAR [42] 등이 포함된다. 우리는 DeepFM을 CTR 백본으로 사용한다. 이러한 방법을 다른 백본과 결합한 결과는 부록 C.1에 보고된다.
각 비교 방법은 해당 저자의 공개 코드를 사용해 구현되었다. 더 자세한 구현 사항은 부록 B에 제공된다.
콜드 스타트 및 웜업 단계 성능
Table 1은 결과를 보여준다. 콜드 스타트 및 웜업 단계에 맞춰 설계된 콜드 스타트 방법들이 대체로 더 나은 성능을 보인다. EmerG는 모든 네 단계에서 일관되게 최고의 성능을 발휘하며, 하이퍼네트워크가 아이템별 특징 상호작용을 포착하는 효과를 검증한다. N-way K-shot 설정의 few-shot 방법들은 웜업 단계 A에서 좋은 성능을 얻지만, 샘플 수가 증가함에 따라 완전한 재훈련 없이 더 높은 성능을 달성하지 못한다. 훈련 세트를 사용해 미세 조정하는 일반 CTR 백본들은 상대적으로 낮은 성능을 보이며, 이 중 FinalMLP가 가장 잘 수행된다. 이 방법들은 새 아이템에 대한 아이템별 파라미터를 무작위로 초기화하므로, 사전 학습된 모델을 소수의 새 아이템 인스턴스만으로 미세 조정하는 것은 좋은 성능을 얻기에 충분하지 않다. 특히, 아이템-사용자별 특징 상호작용 그래프를 사용하는 GNN 기반 CTR 모델 Fi-GNN은 성능이 낮은데, 이는 자유도가 너무 높아 콜드 스타트 및 웜업 단계에서 특징 상호작용 패턴을 포착하는 데 불리함을 나타낸다. EmerG에서는 하이퍼네트워크를 사용하여 아이템별 특징 그래프를 생성하고, 이를 임의 차수의 특징 상호작용을 포착할 수 있는 맞춤형 메시지 전달 메커니즘을 가진 GNN이 처리하며, 메타 학습 전략을 통해 파라미터를 최적화한다. 이러한 설계 고려 사항들은 EmerG의 최고의 성능에 기여한다. 계산 오버헤드 측면에서도 EmerG는 시간과 자원 면에서 상대적으로 효율적이다. 자세한 비교는 부록 C.2에 있다.
충분한 훈련 샘플이 주어진 경우 성능
EmerG가 새로운 아이템에 대해 충분한 훈련 샘플이 있을 때 어떻게 수행하는지, 특히 전통적인 CTR 백본과 비교하여 확인한다. 여기서 우리는 새로운 아이템의 원래 테스트 샘플 중 일부를 사용하여 실험 파이프라인에 더 많은 훈련 샘플을 추가하고, 더 작은 테스트 세트에서 성능을 평가한다. Table 1에서 CTR 백본과 few-shot 방법 중 가장 잘 수행하는 기준들과 EmerG를 비교한다. Figure 2는 훈련 샘플 수에 따른 테스트 AUC(%)를 보여주며, 테스트 F1(%)로 측정된 실험 결과도 유사하다. 모든 방법이 더 많은 훈련 샘플을 사용할수록 성능이 향상되며, 전통적인 CTR 백본인 DeepFM이 새 아이템 ID 임베딩을 생성하기 위한 추가 모듈을 갖춘 CVAR보다 점진적으로 우수한 성능을 보인다. 반면 EmerG는 모든 경우에서 일관되게 최고의 성능을 발휘하며, 다른 방법들보다 더 나은 성능으로 수렴한다. 이는 EmerG가 아이템별 특징 상호작용을 다양한 차수로 효과적으로 포착할 수 있음을 검증한다.
5.3 ModelAnalysis
5.3.1 제거 연구. 제안된 EmerG를 다음과 같은 변형들과 비교한다: (i) **w/random graph**는 (8)에서 인접 행렬 \( A^{(1)} \)을 무작위로 생성한다; (ii) **w/o sparsification**은 (4)를 적용하여 인접 행렬을 희소화하지 않는다; (iii) **w/o mask**는 (6)를 적용하여 저차 특징 그래프에서 연결되지 않은 노드들이 고차 특징 그래프에서도 연결되지 않도록 강제하지 않는다; (iv) **w/shared graph**는 모든 아이템에 대해 글로벌 공유 인접 행렬을 사용하는 반면, EmerG는 아이템별 인접 행렬을 사용한다; (v) **w/o meta**는 과거 아이템에서 GNN과 하이퍼네트워크를 학습하지만, 작업을 구성하거나 메타 학습 전략을 사용하지 않는다; (vi) **w/o inner**는 \( \phi_{𝑖} \)를 직접 사용하고 각 작업 내에서 이를 \( \phi'_{𝑖} \)로 업데이트하지 않는다.
Figure 3은 결과를 보여준다. "w/random graph"는 EmerG보다 낮은 성능을 보여주며, 하이퍼네트워크에 의해 생성된 아이템별 특징 그래프가 의미가 있음을 나타낸다. EmerG가 "w/o sparsification"보다 성능이 더 좋은 것은 밀접하게 관련된 노드들만 연결된 희소 특징 그래프가 GNN 모델이 유용한 메시지에 집중하도록 할 수 있음을 보여준다. "w/o mask"와 EmerG를 비교했을 때, 성능 저하는 (6)에서의 가정이 유효함을 검증하며, mask 연산은 인접 행렬이 지나치게 밀집되는 것을 방지하여 불필요한 특징 상호작용을 가지치기하고 더 나은 설명 가능성을 제공하는 데 도움이 된다. "w/shared graph"가 EmerG보다 낮은 성능을 보이는 것도 관찰할 수 있다. 이는 글로벌 공유 인접 행렬을 사용해서는 다양한 사용자와 아이템 간의 상호작용 패턴을 포착할 수 없음을 입증한다. 마지막으로, EmerG가 "w/o meta"와 "w/o inner"를 능가하며, 이는 작업 간의 메타 학습과 각 작업 내의 업데이트가 필요함을 강조한다.
5.3.2 GNN 레이어 수의 영향. Proposition 4.1에서 설명한 바와 같이, GNN의 메시지 전달 프로세스를 맞춤화하여 \( 𝑙 \)번째 레이어가 \( 𝑙 \)차 특징 상호작용을 포괄하도록 했다. 또한, 하이퍼네트워크가 제공한 초기 행렬에서 후속 GNN 레이어의 인접 행렬을 직접 생성함으로써 이 과정을 최적화했다. 이 접근 방식은 아키텍처를 간소화할 뿐 아니라 추가 레이어로 확장이 용이하며, 이를 통해 고차 특징 상호작용을 쉽게 포착할 수 있다. 이와 같은 맥락에서, 다양한 데이터셋에서 GNN 레이어 수가 성능에 미치는 영향을 조사한다.
Figure 4는 결과를 보여준다. EmerG는 데이터셋에 따라 다른 레이어 수에서 최상의 성능을 얻는다: MovieLens에서는 GNN 레이어 2개를 사용한 EmerG가 최고의 성능을 보이며, Taobao에서는 GNN 레이어 3개를 사용한 EmerG가 최고의 성능을 보인다. 이는 데이터셋에 따라 필요한 GNN 레이어 수가 다르며, Taobao와 같은 대규모 데이터셋은 MovieLens와 같은 소규모 데이터셋보다 더 고차 특징이 필요할 수 있음을 보여준다. EmerG는 이러한 요구 사항을 쉽게 충족할 수 있도록 설계되었다.
5.3.3 다양한 특징 상호작용 함수. 다양한 특징 상호작용 함수를 사용하는 것을 고려한다. Table 2는 결과를 보여준다. 보시다시피, 요소별 곱셈(element-wise product)을 사용하는 것이 가장 좋은 성능을 내며, 이는 EmerG에서 채택된 방식이다.
5.4 CaseStudy
마지막으로, MovieLens에서 영화 *Lawnmower Man 2: Beyond Cyberspace*와 영화 *Waiting to Exhale*를 새로운 아이템으로 선택하여, 아이템별 특징 그래프를 기록하는 인접 행렬을 Figure 5에 시각화한다.
보시다시피, EmerG는 서로 다른 아이템에 대해 서로 다른 작업별 특징 그래프를 학습한다. Figure 5(a)와 Figure 5(b)를 비교하면, *Lawnmower Man 2: Beyond Cyberspace*에는 특히 중요한 2차 특징 상호작용 ⟨장르, 제목⟩이 있음을 알 수 있다. *Lawnmower Man 2: Beyond Cyberspace*의 장르는 공상 과학이며, *Waiting to Exhale*의 장르는 코미디이다. 공상 과학 장르의 경우, 제목이 종종 세계관이나 주제를 반영하여 사람들이 흥미를 느낄지 판단하는 데 중요한 역할을 한다. 반면, 코미디 작품의 경우 제목이 재미와 무관할 때가 많다.
또한 EmerG는 의미 있는 고차 특징 상호작용도 포착할 수 있다. 예를 들어, ⟨연도, 나이⟩와 ⟨연도, 우편번호⟩는 중요한 2차 특징 상호작용으로서, 3차 특징 상호작용인 ⟨연도, 나이, 우편번호⟩를 발견하는 데 기여한다. Figure 5(c)에서 연도, 나이, 우편번호 노드 간의 관계는 모두 상대적으로 중요해졌으며, 특히 Figure 5(b)에서는 중요하지 않았던 ⟨나이, 우편번호⟩가 중요한 상호작용으로 떠오른다. 이는 영화의 연도가 그 영화를 볼 가능성이 높은 사람들의 나이를 결정한다는 점에서 이해할 수 있다. 예를 들어, 노년층은 일반적으로 오래된 영화를 선호한다. 이와 별개로, 우편번호로 나타내는 지역 위치도 중요한 역할을 한다. 예를 들어, 개발된 지역의 사람들은 새로운 것에 더 개방적일 가능성이 크다. 따라서 지역이 바뀌면 같은 영화를 좋아하는 사람들의 나이대가 달라질 수 있으며, 이는 학습된 3차 특징 상호작용의 유효성을 검증해준다.
우리는 또한 하이퍼네트워크가 생성한 아이템별 특징 그래프가 새로운 아이템의 학습 샘플을 보지 않아도 특징 간의 상호작용을 대략적으로 포착할 수 있음을 관찰할 수 있다. 웜업 단계에서의 학습 세트를 사용하여 지속적으로 최적화되지만, 변화는 급격하지 않다. 예를 들어, Figure 5(b)와 Figure 5(d)에서 Figure 5(f)까지의 2차 특징 상호작용 패턴은 유사하며, 학습 샘플에 맞게 약간의 변화만 보인다. 종합적으로, EmerG는 다양한 차수에서 아이템별 특징 상호작용을 포착할 수 있는 합리적인 인접 행렬을 학습할 수 있음을 결론지었다.
6 CONCLUSION
본 연구에서는 특징 상호작용의 중요성을 강조하며, EmerG라는 새로운 솔루션을 제안하여, 아이템별 고유의 상호작용 패턴을 포착함으로써 점진적으로 상호작용 기록이 축적되는 새로운 아이템에 대한 CTR 예측을 효과적으로 수행할 수 있도록 했다. 우리의 접근 방식은 하이퍼네트워크를 활용하여 아이템별 특징 그래프를 구축하며, 여기서 노드는 특징을 나타내고 엣지는 그들의 상호작용을 나타내어, 각 아이템의 복잡한 상호작용 패턴을 모델이 인식할 수 있도록 한다. 우리는 모든 차수의 특징 상호작용을 포착할 수 있도록 설계된 메시지 전달 과정을 갖춘 그래프 신경망(GNN)을 결합하여 정확한 CTR 예측을 가능하게 한다. 데이터가 부족한 상황에서 과적합을 방지하기 위해, 다양한 아이템 CTR 예측 작업에 대해 하이퍼네트워크와 GNN의 파라미터를 세밀하게 조정하는 메타 학습 전략을 도입하였으며, 각 작업에서 아이템별 파라미터에 최소한의 수정만 필요하도록 했다. 실제 데이터셋에 대한 실험 결과, EmerG는 상호작용 기록이 전혀 없거나 일부 있는 경우, 혹은 상당한 양의 상호작용이 있는 경우에도 CTR 예측에서 최첨단 성능을 달성하는 것으로 나타났다. 우리는 이러한 접근 방식이 향후 의약품 추천과 같은 다른 애플리케이션에서도 콜드 스타트 문제를 완화하는 데 사용될 수 있을 것으로 기대한다.