ABSTRACT
연속 추천(Sequential Recommendation, SR)과 다중 행동 연속 추천(Multi-Behavior Sequential Recommendation, MBSR)은 모두 현실 세계의 시나리오에서 비롯된 개념이다.
1. 연속 추천 (Sequential Recommendation, SR)
SR은 단일 행동 유형에 초점을 맞춘 추천 방식이다. 예를 들어, 전통적인 SR 모델에서는 주로 사용자의 '구매 이력'이나 '조회 이력'을 순차적으로 분석하여 다음에 추천할 아이템을 예측한다. SR은 사용자가 시간순으로 어떤 아이템과 상호작용했는지를 바탕으로, 다음에 어떤 아이템을 선호할 가능성이 높은지 예측한다. 여기서 단일 행동 유형(예: 조회, 클릭, 구매 등)에 대해서만 고려하기 때문에, 다양한 행동 유형 간의 상호작용은 분석하지 않는다.
2. 다중 행동 연속 추천 (Multi-Behavior Sequential Recommendation, MBSR)
MBSR은 SR의 한계를 극복하기 위해 등장한 개념으로, 다양한 행동 유형을 동시에 고려하여 추천의 정확도를 높이는 방식이다. 예를 들어, 사용자 A가 어떤 아이템을 클릭하고, 장바구니에 담고, 최종적으로 구매하는 등의 여러 행동 유형을 다루게 된다. MBSR은 이러한 다양한 행동 유형의 의존성을 학습하여, 단일 행동 데이터만으로는 놓칠 수 있는 추가적인 사용자 의도를 파악하고, 더 정교한 추천을 가능하게 한다. 이를 통해 데이터의 부족 문제를 보완하거나, 단일 행동 데이터만으로 얻기 어려운 심화된 패턴을 파악할 수 있다.
SR과 비교했을 때, MBSR은 다양한 행동의 의존성을 고려한다. 대부분의 기존 연구들이 전자상거래(e-commerce) 시나리오를 중심으로 MBSR을 연구하고 있음을 확인하였다. 행동 유형의 데이터 형식 관점에서 보면, 기존의 라벨 형태 데이터는 제한된 정보를 가지고 있으며, 소셜 미디어와 같은 시나리오에는 적합하지 않다. 이러한 점을 바탕으로, 우리는 행동 세트(Behavior Set)를 도입하고, MBSR을 행동 세트 기반 연속 추천(Behavior Set-informed Sequential Recommendation, BSSR)으로 확장하였다.
- BSR에서는 행동 데이터를 라벨 형태(예: 클릭 = 1, 구매 = 2)로 표현하는 경우가 많았는데, 이 방법은 행동 간의 복잡한 관계나 사용자의 다양한 행동 패턴을 충분히 표현하기 어렵다.
- 그래서 BSSR (Behavior Set-informed Sequential Recommendation)이 등장하게 된다. BSSR에서는 단일 행동 라벨이 아니라, 여러 행동을 동시에 포함하는 "행동 세트"로 데이터를 표현한다. 예를 들어, 어떤 사용자가 특정 아이템을 "클릭"하고 "좋아요"를 누른 경우, 이를 하나의 세트로 보고 분석하는 것이다.
BSSR에서는 행동 간의 의존성이 더욱 복잡하고 개인화되며, 사용자 관심의 유발이 명확한 맥락적 연관성을 갖지 않을 수 있다. 우리는 행동 세트 내에 내재된 동역학을 탐구하고, 변화하는 행동 세트에 따라 맞춤형 추천 목록을 적응적으로 생성하기 위해, 행동 세트 기반 연속 추천(BSSR)을 위한 명시적 및 암시적 모델링을 Dual-Path Transformer로 수행하는 새로운 해결책을 제안하였다.
우리의 EIDP(Explicit and Implicit modeling via Dual-Path Transformer)는 명시적 모델링 경로(Explicit Modeling Path, EMP)와 암시적 모델링 경로(Implicit Modeling Path, IMP)를 통해 두 가지 경로로 구성되며, 행동 표현을 직접적으로 통합할지 여부에 따라 구분된다. EMP의 핵심 구성 요소는 개인화된 행동 세트 전이 패턴 추출기(Personalized Behavior Set-wise Transition Pattern Extractor, PBS-TPE)로, 행동 표현을 아이템과 위치와 결합하여 행동 세트 내에서 세밀한 수준에서의 행동 동역학을 탐구한다. IMP는 특정 행동 유형에 따라 경량 멀티 헤드 자기 주의 블록(Light Multi-head Self-Attention Blocks, L-MSAB)을 인코더로 사용하며, 얻어진 다중 시점(multi-view) 표현들을 교차 행동 주의 융합(Cross-Behavior Attention Fusion, CBAF)으로 결합한다. 다음 시간 단계의 행동 세트를 이용해 행동 수준에서 협력적 의미를 추출한다. 두 개의 실제 데이터셋에 대한 광범위한 실험을 통해 우리의 EIDP의 효과성을 입증하였다.
1 INTRODUCTION
온라인 추천 시스템은 전자상거래(e-commerce), 소셜 미디어, 뉴스와 같은 다양한 시나리오에서 널리 사용되고 있다. 추천 문제의 진화는 점차 현실 세계의 시나리오와 일치하게 변해가고 있으며, 사용자와 아이템의 상호작용은 자연스럽게 시간 순서대로 펼쳐진다. 이는 연속 추천(Sequential Recommendation, SR) 문제로 이어진다. 전통적인 SR 알고리즘은 단일 유형의 행동 시퀀스(예: 구매 시퀀스)만을 모델링한다. 하지만 이러한 알고리즘은 사용자가 다양한 유형의 상호작용을 할 수 있는 현실 세계의 시나리오에 적응하지 못하는 경우가 많다. 이러한 문제를 해결하기 위해 다중 행동 연속 추천(Multi-Behavior Sequential Recommendation, MBSR)이 등장하였다. MBSR은 클릭과 같은 보조 행동 데이터를 활용하여 목표 행동 데이터(예: 구매)의 희소성을 완화하고, 이를 통해 목표 행동에 대한 성능을 향상시키는 것을 목표로 한다.
일부 선구적인 연구들은 다양한 모델링 관점과 기본 네트워크 아키텍처를 통해 SR 모델의 성능을 능가하는 결과를 얻었으며, MBSR 문제 설정의 유효성을 확인하였다. 그러나 이러한 연구들은 대부분 전자상거래 시나리오에서 MBSR에 초점을 맞추고 있다. 그러나 MBSR은 비즈니스 시나리오마다 상호작용 패턴에 차이가 존재한다. 예를 들어, 소셜 미디어 시나리오의 상호작용 데이터는 짧은 기간 동안 높은 빈도로 발생하는 특성을 보일 수 있다. 기존의 라벨 형태의 행동 표현은 MBSR에서 이러한 특성에 충분히 대응하지 못할 수 있다.
데이터 증강을 위해 항목의 순서를 변경하는 '재정렬(reordering)'과 같은 몇 가지 작업은 대조 학습(contrastive learning)에서 널리 사용된다. 이는 원래 시퀀스에서 시간 순서가 반드시 엄격하게 유지될 필요는 없음을 시사한다. 또한, 일부 연구에 따르면, 균일하게 정렬된 시퀀스가 비균일 시퀀스에 비해 모델 성능을 크게 향상시킨다는 것이 밝혀졌다. 이러한 발견에 영감을 받아, 우리는 기존의 라벨 형태의 행동 유형을 멀티-핫 벡터(multi-hot vector) 형식으로 확장할 수 있음을 인식하였다. 이를 '행동 세트(behavior set)'라 명명하며, 이는 상호작용 항목에 포함된 정보를 집합의 관점에서 풍부하게 하는 것을 목표로 한다. 구체적으로, 짧은 시간 동안 발생한 모든 행동 유형의 집합을 멀티-핫 벡터로 표현한다. 이렇게 지역적 관심사(local interests)를 집계함으로써 행동 상호작용 데이터를 더 고르게 분포시켜, 모델이 더 나은 표현을 학습할 수 있도록 돕는다. 행동 세트와 함께 구성된 상호작용 시퀀스는 소셜 미디어와 전자상거래 시나리오 모두에 적용 가능하다. 우리는 MBSR을 일반화하여 행동 세트 기반 연속 추천(Behavior Set-informed Sequential Recommendation, BSSR)이라는 새로운 문제를 정의하였다.
- 멀티-핫 벡터(multi-hot vector): 벡터에서 여러 값이 '1'이 될 수 있는 벡터. 여러 속성이나 여러 행동이 동시에 발생할 때 나타내기 좋음.
이 논문에서는 BSSR 문제를 해결하기 위해 명시적 및 암시적 모델링을 Dual-Path Transformer로 수행하는 새로운 솔루션인 EIDP(Explicit and Implicit modeling via Dual-Path Transformer)를 제안한다. 이 논문의 주요 기여는 다음과 같다.
- 우리는 BSSR이라는 새로운 중요한 문제를 정의하고 연구하였으며, 이를 MBSR과 SR로 환원할 수 있음을 밝혔다.
- 개인화된 행동 세트 표현을 위한 새로운 인코딩 방식을 설계하였다.
- 명시적 및 암시적 관점에서 행동 세트 정보를 주입하여 행동 내 및 행동 간 이질적 의존성을 포착하는 이중 경로 구조(Dual-Path Architecture)를 가진 새로운 솔루션(EIDP)을 제안하였다.
- 두 개의 실제 데이터셋에 대한 광범위한 실험을 수행하였으며, 그 결과 EIDP가 열 개의 최첨단 SR 및 MBSR 방법보다 효과적임을 확인하였다. 또한, 이중 경로 구조의 시너지 효과를 확인하는 소거 연구(ablation study)를 통해 이를 입증하였다.
- SR (Sequential Recommendation): SR은 단일 행동(예: '구매' 같은 특정 행동)만을 고려하는 추천 모델이다. 예를 들어, 사용자 A가 제품 X, Y, Z를 순서대로 구매했다면 SR 모델은 이 구매 행동의 시간 순서만을 바탕으로 다음 추천을 진행한다. 다양한 행동이 아닌, 구매와 같은 단일한 행동만 다루고 있다는 점에서 간단하다는 장점이 있다.
- MBSR (Multi-Behavior Sequential Recommendation): MBSR은 SR에서 한 걸음 더 나아가 여러 행동(예: '클릭', '좋아요', '장바구니에 담기' 등)을 시간 순서에 따라 함께 고려한다. 예를 들어, 사용자 A가 제품 X에 클릭을 하고, Y에 좋아요를 누르고, Z를 장바구니에 담았다면, MBSR 모델은 이 일련의 행동들을 따로따로 나열하며 시간 순으로 인식하고, 다른 행동이 다음 행동에 미치는 영향을 파악하려고 한다. 그러나 여전히 이 행동들은 시간 순서대로 처리된다는 점에서 SR과 유사한 면이 있다.
- BSSR (Behavior Set-informed Sequential Recommendation): BSSR은 시간 순서보다는 사용자가 짧은 시간 동안 특정 행동 세트(behavior set)를 동시에 실행했을 때 이를 하나의 묶음으로 보고 학습하려고 한다. 예를 들어, A 사용자가 X 제품에 대해 '클릭'과 '좋아요'를 동시에 한 경우, 이 두 행동을 시간 순서가 아니라 하나의 '세트'로 취급해 정보 손실을 줄이려 한다. 이러한 접근은 특히 소셜 미디어나 쇼핑에서 더 높은 행동 빈도가 짧은 시간 동안 발생하는 경우(예: 짧은 시간에 여러 행동이 일어나는 경우)에 유리하다.
즉, SR은 단일 행동을 시간 순서대로, MBSR은 여러 행동을 시간 순서대로, BSSR은 여러 행동을 묶어서 세트로 사용하는 차이가 있다.
2 BEHAVIOR SET-INFORMED SEQUENTIAL RECOMMENDATION
이 절에서는 BSSR 문제 정의를 공식적으로 제시하고, 이 문제에 내재된 몇 가지 고유한 도전 과제를 나열한 후, 제안된 솔루션의 개요를 설명한다.
2.1 Problem Definition
사용자 집합 U={u}
아이템 집합 V={v}
사용자 행동 집합
여기서 ∣U∣, ∣V∣, ∣B∣는 각각 사용자, 아이템, 행동 유형의 수를 의미한다. 특정 사용자 u∈U에 대한 행동 세트가 포함된 상호작용 시퀀스는 다음과 같이 나타낼 수 있다:


2.2 Challenges
BSSR은 MBSR과 비교했을 때, 행동 세트와 행동 시퀀스와 관련하여 고유한 몇 가지 도전 과제를 내포하고 있다.

- Ch.1 개인화된 행동 의존성의 복잡성: 사용자는 개인화된 특성으로 인해 서로 다른 행동 패턴을 보인다. 예를 들어, 소셜 미디어 시나리오에서는 전자상거래 시나리오와 달리 시간 의존성이 짧은 기간에 완료된 개별 상호작용으로 전환될 수 있다. 이러한 상호작용은 각기 독립적인 관심 이벤트로 작용하여 포함된 정보를 더욱 복잡하게 만든다. 또한, 행동 세트 내 또는 행동 세트 간의 전환 의존성도 개인화되어 있다.
- Ch.2 사용자 관심 유발의 불확실성: 행동 세트 내의 다양한 행동 조합에서 반영되는 사용자 선호 강도는 사용자와 행동 유형에 따라 달라진다. 따라서 가상의 사용자 관심 진화 곡선을 대략적으로 시각화할 수 있다. 이는 MBSR에서의 명확한 맥락 정보(예: 장바구니에 담기는 행동이 이후 구매 행동의 확률을 높이는 경우)와 달리, 행동 세트 내에서의 맥락은 매우 불확실하다.
- Ch.3 행동 세트 내재된 역동성: MBSR에서의 행동 전환은 라벨 간의 1:1 관계를 다루지만, BSSR에서는 행동 내의 역동성이 1:다수 혹은 다수:다수의 관계로 변하게 된다.
- Ch.4 목표 행동 세트의 변동성: MBSR이 구매 예측에 중점을 두는 것과 달리, BSSR의 목표 행동 세트는 단일 예측 목표가 아니라 여러 가지를 포함할 수 있다. 이는 모델이 사용자의 선호 강도의 변화를 감지하고, 이를 기반으로 사용자 맞춤형 추천 목록을 제공할 수 있어야 함을 요구한다.
2.3 Overview of Our Solution

본 논문에서는 위의 도전 과제를 해결하기 위해, 행동 표현을 직접적으로 포함할 것인지 여부에 따라 모델링 관점을 구분하였다. 그림 2에서 보이는 것처럼, EIDP는 두 개의 경로로 이루어진 아키텍처를 가지고 있으며, 각 경로는 다른 모델링 목적에 맞게 설계되었다.
- 명시적 모델링 경로(EMP): EMP는 명시적 행동 정보 주입을 통해 행동 간 전환 관계를 추출한다. 이는 두 가지 주요 단계로 이루어진다.
- a) 명시적 인코딩 임베딩 레이어(EEL)는 행동 세트 임베딩을 아이템 및 위치 측면에 주입한다.
- b) 개인화된 행동 세트 전환 패턴 추출기(PBS-TPE)는 행동 정보를 아이템과 위치 측면과 밀접하게 결합한다.
- 암시적 모델링 경로(IMP): IMP는 행동 유형별 다양한 관점에서 행동 간 협력을 추출한다. 이는 세 가지 주요 구성 요소로 이루어진다.
- a) 사용자 행동 선호 요소 강화 임베딩 레이어(UB-FEEL)는 강화 마스크에 기반하여 시퀀스 표현을 조정한다.
- b) 가벼운 다중-헤드 자기 주의 블록(L-MSAB)은 행동 유형별로 인코더 역할을 하여 행동별 표현을 얻는다.
- c) 행동 간 주의 결합(CBAF)은 교차 주의를 사용하여 결합 과정을 촉진한다.
- 이중 경로 기반 다음 항목 예측: EIDP는 두 경로에서 얻은 표현을 결합하여 다음 항목을 예측한다.
3 PROPOSED METHODOLOGY
이 섹션에서는 EIDP의 기술적인 세부 사항을 다룬다. 일부 표기법과 그 설명은 부록 A.1에 나와 있다.
3.1 Entity Encoding

3.2 Explicit Modeling Path
EMP(Explicit Modeling Path)에서는 행동 세트 임베딩을 직접적으로 통합하여 행동 세트 내의 역학을 명시적으로 캡처하고 세부 정보를 활용하여 개인화된 행동 동태를 추출한다.
3.2.1 명시적으로 인코딩된 임베딩 레이어 (Explicitly Encoded Embedding Layer)

3.2.2 개인화된 행동 세트 전환 패턴 추출기 (Personalized Behavior Set-wise Transition Pattern Extractor)
행동 정보는 사용자의 영향을 받는 서로 다른 항목에 대한 영향뿐만 아니라, 서로 다른 행동의 발생 순서에도 명확한 시간 순서를 보여줍니다. [39]의 분리 아이디어를 바탕으로, 우리는 개인화된 행동 세트 전환 패턴 추출기(PBS-TPE)를 제안하며, 이 추출기는 Dual-Coupled Behavior set-aware Attention (DCBA) 메커니즘을 사용합니다.

- Self-Attention (SA)는 사용자의 행동 임베딩 간의 관계를 학습하기 위한 과정이다. 이를 통해 시퀀스 내에서 각 행동 간의 의존성을 파악한다. 특히 SA는 query와 key 임베딩을 투영하여 인과 관계를 마스킹하고, 사용자가 행동하는 시퀀스에서 특정 행동이 이전 행동과 어떻게 연결되는지 학습하는 데 도움을 준다.
- Hamming Distance Attention (HDA)는 각 행동 세트 간의 유사성과 차이를 측정하는 방법이다. 멀티-핫 벡터의 Hamming 거리를 계산하여 각 행동 세트가 얼마나 유사하거나 차이가 나는지 확인한다. 이를 통해 사용자 시퀀스 내에서 유사한 행동 세트는 높은 관련성을 가지며, 차이가 큰 행동 세트는 낮은 관련성을 가짐을 나타낸다.

DCBA (Dual-Coupled Behavior set-aware Attention)
- DCBA는 self-attention과 Hamming distance attention (HDA)를 결합하여, 아이템 및 위치 측면에서 개인화된 행동 표현을 통합합니다.
- 이를 통해 사용자 시퀀스에서 각 행동 세트 간의 전환 패턴을 정확히 파악하고 모델이 학습할 수 있도록 돕습니다.

- 명시적 인코딩 임베딩 레이어 (EEL):
- 행동 세트의 임베딩을 직접적으로 아이템과 위치 정보에 주입합니다.
- 예를 들어, 사용자가 특정 시간에 어떤 행동을 했는지를 직접 임베딩에 반영하여 명확한 행동의 표현을 생성합니다.
- 개인화된 행동 세트 전환 패턴 추출기 (PBS-TPE):
- EEL을 통해 얻은 행동 임베딩을 이용해, 사용자마다 다른 행동 전환 패턴을 학습합니다.
- 아이템과 위치에 결합된 행동 정보를 통해 행동 간 전환 관계를 더욱 깊게 탐구합니다.
즉, EMP는 각 시간에서의 행동 정보를 명시적으로 주입해 행동 간의 전환 관계를 추출하는 데 강점이 있습니다. 이를 통해 행동이 아이템과 위치에 따라 어떻게 변화하는지, 그리고 이 변화가 다음 행동을 어떻게 예측하는지 학습합니다.
3.3 Implicit Modeling Path
암묵적 모델링 관점에서, IMP(암묵적 모델링 경로)에서는 행동 유형별로 행태적 선호 요소를 사용하여 임베딩을 강화합니다. 인코더로 입력된 후, 우리는 여러 행동-특화 뷰에서 시퀀스 표현을 얻습니다. 이러한 행동 뷰 사이의 협업 관계를 추출하여, 행동 수준에서 이질적인 의존성을 포착할 수 있습니다.
3.3.1 User Behavioral Preference Factor Enhanced Embedding Layer

EEL(명시적 인코딩 임베딩 레이어)과 다르게, 우리는 단순히 항목 임베딩과 위치 임베딩을 합산하여 얻은 표현을 사용합니다. 이로써, 얻은 표현의 행렬 형식을 표현할 수 있습니다.
따라서 IMP(Implicit Modeling Path)에서는, 아이템이 시퀀스에서 언제 나타났는지에 대한 시간적 순서만을 참고하고, 그 아이템에 대해 어떤 행동(예: 클릭, 좋아요, 장바구니 추가)이 발생했는지는 알 수 없습니다.
전통적인 MBSR(다중 행동 순차 추천) 접근법은 다양한 방법으로 다중 행동별 모델링 접근 방식을 사용하여, 행동 간 종속성을 캡처합니다. 그러나 시퀀스의 시맨틱 연속성을 보존하기 위해 UB-FEEL은 특정 행동 유형에 따라 파티션된 시퀀스를 설계합니다. 이를 위해 우리는 다음과 같은 크기 조정 마스크를 정의합니다:

- 행동이 발생했을 때는 가중치가 더 주어집니다. 이때 Muℓ,k[i,k] = ∣B∣가 되어, 해당 행동에 대해 더 큰 가중치를 반영하게 됩니다.
- 행동이 발생하지 않았을 때는 가중치가 덜 주어집니다. 이때 Muℓ,k[i,k]=1이 되며, 해당 행동이 발생하지 않은 경우는 기본 가중치만 반영됩니다.
즉, 특정 행동이 발생했을 때 해당 행동의 임베딩에 더 많은 비중을 두어 모델이 해당 행동에 대한 정보를 더 잘 학습할 수 있도록 설계된 것입니다.
3.3.2 Light Multi-head Self-Attention Blocks
UB-FEEL의 IMP에서는 행동-특화 뷰에서 상호작용 표현을 선택적으로 강화합니다. 이어서, ProbSparse 멀티-헤드 자기어텐션(PSA)을 사용해, 인코더의 일부로 L-MSAB(경량 멀티-헤드 자기어텐션 블록)를 구축합니다. PSA는 다음과 같이 정의됩니다:
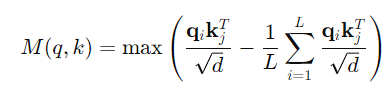
PSA는 (15)와 같이 두 쿼리 간의 중요도를 평가하여, 주요 쿼리들을 기준으로 우선순위를 부여합니다.
ProbSparse Multi-head Self-Attention (PSA): PSA는 쿼리 Q의 상위-값을 기반으로 주어진 행동별 뷰에서 중요도가 높은 쿼리들만을 선택적으로 평가합니다. PSA는 아래와 같이 정의됩니다:

PSA의 수행 과정 및 동작 원리
- 쿼리, 키, 값(query, key, value) 계산:
- PSA에서는 먼저 쿼리 , 키 K, 값 V를 계산합니다.
- 쿼리 , 키 K, 값 V는 입력 시퀀스에서 특정 특징 벡터를 추출한 것으로, 각 요소가 서로 다른 벡터 공간에 투영된 후 연산에 사용됩니다.
- 쿼리(Q): 특정 행동(예: 좋아요, 댓글 등)에 대한 사용자의 관심도 벡터 (사용자 행동 임베딩)
- 키(K): 시퀀스 내의 각 항목에 대한 고유한 특성 벡터 (항목 임베딩)
- 값(V): 각 항목의 최종 정보 벡터 (항목 임베딩과 관련된 정보)
- 여기서 쿼리는 사용자가 특정 시간 단계에서 어떤 항목에 대해 관심이 있는지를 나타내는 값이고, 키는 모든 항목에 대한 고유 정보를 나타내며, 값은 각 항목의 실제 정보를 담고 있습니다.
- 중요한 쿼리 선택 (ProbSparse 적용):
- PSA는 모든 쿼리를 사용하지 않고, 가장 중요한 몇 개의 쿼리만 선택해 연산합니다.
- 이를 위해 M(Qi,Kj)를 사용하여 쿼리와 키 간의 내적 값이 큰 상위 uu개의 쿼리를 선택합니다. 이 uu개의 쿼리는 해당 사용자의 가장 중요한 행동이나 관심도를 반영하는 쿼리로 간주됩니다.
- 예를 들어, "좋아요", "댓글" 등 특정 행동에 대한 쿼리가 높은 관심도로 선정될 수 있습니다.
- 중요한 쿼리에 대한 Self-Attention 수행:
- 선택된 중요한 쿼리에 대해 Self-Attention 연산을 수행합니다.
- 이 때, 선택된 쿼리와 해당 쿼리의 키 값 사이의 유사도를 계산하여 softmax 연산으로 가중치를 할당합니다.
- 이렇게 계산된 가중치는 중요한 항목이 얼마나 강한 상관성을 가지는지 나타내며, 해당 항목에 집중하도록 합니다.
- 값 V에 대한 결합 및 출력 계산:
- 상위 u개의 중요한 쿼리에 대한 Self-Attention 가중치를 값 V와 결합하여 최종 출력을 계산합니다.
- PSA에서는 중요하지 않은 쿼리에 대해서는 대체적으로 평균값을 사용하는데, 이는 선택되지 않은 쿼리 간의 중요도를 고려하지 않고 단순히 대체하는 방식입니다.
- 이를 통해 PSA는 계산량을 줄이면서도 중요한 정보에 집중할 수 있습니다.
- 출력 병합 및 최종 결합:
- 마지막으로, PSA는 각 헤드에서 계산된 출력을 병합하고, 선형 변환을 거쳐 최종 출력을 생성합니다.
PSA의 역할
PSA는 모든 쿼리와 키를 일괄적으로 연산하는 대신, 가장 중요한 몇 개의 쿼리와 관련된 정보만을 선택적으로 사용하여 효율성을 높입니다. 특히, 대규모 시퀀스 데이터에서 이 방법을 사용하면 연산 효율성을 크게 향상시킬 수 있습니다. 이를 통해 모델이 사용자의 주요 행동(예: 좋아요, 클릭 등)에 집중할 수 있게 되어 중요한 정보에만 더 높은 가중치를 부여합니다.
3.3.3 Cross-Behavior Attention Fusion(CBAF)
CBAF 개요
CBAF는 여러 행동별 관점(behavior-specific views) 간의 결합 모듈로, 크로스-행동 어텐션(fusion)과 FFN(Fully Connected Feed-Forward Network) 레이어로 구성된다.
-> 여기서 실제로 행동 간 협력적 패턴을 학습한다. CBAF는 행동 시퀀스와 행동 간의 관계를 학습하는 데 있어 각 행동의 상관관계를 유도하는 핵심 모듈로, 각 행동을 구분하는 정보를 반영할 수 있다.
- 크로스-행동 어텐션(CBA)
이 모듈은 다음 시점에 있는 행동 세트를 다음 단계로 가이드하기 위해 사용된다. 이 모듈은 현재 시점에서 행동 세트를 이용해 다양한 행동별 관점에서 정보를 결합한다. CBA는 다음과 같은 수식으로 표현된다:


CBA 모듈은 행동 의미(contextual semantics)와 행동 간의 상호작용을 추출하여, 이를 바탕으로 행동 예측을 더욱 정교하게 한다.
- 크로스-행동 어텐션 결합 모듈(CBAF)
이를 통해 다중 관점 통합이 이루어지며, 최종적으로는 다음과 같은 수식으로 표현된다:

3.4 Prediction and Model Training
Dual-Path Next-Item Prediction
EMP와 IMP에서 나온 정보는 다른 관점에서 행동과 아이템 간의 상호작용을 표현한다. 이 두 가지 경로에서 나온 임베딩을 통합하여 다음 시점에 예측되는 아이템을 추정한다.


Training and Optimization

4 EXPERIMENTS
이 섹션에서는 BSSR 시나리오와 관련된 두 개의 공개 산업 데이터셋을 사용하여 실험을 수행하고, 다음 연구 질문에 답하기 위해 분석한다:
(1) RQ1: EIDP는 최신 SR(Sequential Recommendation) 및 MBSR(Multi-Behavior Sequential Recommendation) 방법들과 비교했을 때 성능이 어떤가?
(2) RQ2: 명시적(explicit) 및 암시적(implicit) 모델링을 위한 이중 경로 구조가 서로 다른 시나리오에서 시너지 효과를 보이는가?
(3) RQ3: EIDP의 모듈들이 다른 대체 설계들과 비교했을 때 성능은 어떠한가?
(4) RQ4: 추가적인 행동 정보의 통합이 EIDP의 추천 성능을 향상시키는가?
(5) RQ5: EMP가 추출한 개인화된 intra-behavior dynamics와 IMP가 포착한 inter-behavior 협력 공통성을 어떻게 해석할 수 있는가?
4.1 Experimental Settings
4.1.1 Datasets
실험은 Tencent의 몇 가지 추천 플랫폼에서 수집된 Tenrec [43] 데이터셋에서 수행된다. Tenrec는 서로 다른 시나리오에서의 사용자 피드백을 포함한다:
- QK-Video: 상호작용된 아이템은 짧은 비디오이며, 특정 사용자 행동에 따른 긍정적 피드백과 노출되었으나 사용자 행동이 없는 부정적 피드백을 포함한다. 클릭을 보조 행동으로, 좋아요, 공유 및 팔로우를 목표 행동으로 간주한다.
- QK-Article: 상호작용된 아이템은 기사이며, 읽기를 보조 행동으로, 좋아요, 공유, 즐겨찾기 및 팔로우를 목표 행동으로 간주한다. 데이터 전처리 및 통계 정보는 재현 가능성을 위해 부록 A.3에 제공된다.
4.1.2 Evaluation Protocols.
두 가지 널리 사용되는 순위 기반 평가 지표인 hit ratio (HR@𝑘)와 normalized discounted cumulative gain (NDCG@𝑘)를 사용하며, 여기서 𝑘는 {5, 10, 20} 범위 내에 있다. 평가 시 전체 순위 설정(full-ranking setting)을 채택한다 [20].
4.1.3 Baselines.
EIDP는 다음과 같은 최신 기준선 모델들과 비교된다:
- (1) Sequential Recommendation: SASRec [19], ICLRec [6], DuoRec [27]
- (2) Multi-Behavior Sequential Recommendation: MGNN-SPred [34], MBHT [41], MB-STR [42], NextIP [26], DyMuS [7]
모든 기준선에 대한 설명은 부록 A.4에 제공되며, 대부분의 MBSR 방법은 BSSR에 사용하기 위해 일부 조정이 필요하다. 이러한 조정 사항의 세부 사항은 부록 A.5에 제시된다.
4.1.4 Implementation Details.
EIDP는 PyTorch 1.13을 사용하여 구현되었다. 보다 완전한 재현 세부 사항은 부록 A.6에 기록되었다. 공정한 비교를 위해, 모든 모델의 임베딩 차원 𝑑을 64로 고정하고 시퀀스 길이 𝐿을 50으로 설정하였다. 모든 모델을 동일한 잘린 사용자 시퀀스를 사용하여 학습시키고, 통일된 평가 프레임워크 하에 최적화한다. EIDP에서는 L-MSAB에 있는 쌓인 블록의 개수 𝐶를 {2, 3} 범위에서, PSA의 헤드 개수 𝐻를 {1, 2, 4} 범위에서 조정한다. 각 dropout 레이어의 dropout 비율은 {0.3, 0.4, 0.5, 0.6, 0.7, 0.8} 범위에서 검색한다. QK-Video와 QK-Article의 경우, PSA 메커니즘에 대해 각각 𝛼 = 8 및 12로 설정한다.
4.2 Performance Comparison (RQ1)
우리는 모든 기준선 모델과 EIDP에 대해 목표 행동 세트에서의 다음 아이템 예측 성능을 평가했다. 서로 다른 시나리오의 두 데이터셋에서의 결과는 Table 1에 보고되었으며, 이를 통해 다음과 같은 관찰을 요약할 수 있다:

- 대부분의 MBSR 방법이 SR 방법보다 우수한 성능을 보이는 이유는 주로 크로스 엔트로피 손실 함수의 최적화 과정 덕분이며, 행동 정보 자체에서 비롯된 것은 아니다. SR 방법과 최적화 함수를 일치시킬 경우, 대부분의 MBSR 방법은 일부 고급 SR 방법과 경쟁할 수 없다. 이는 이러한 MBSR 방법의 모델링 기술이 높은 차원의 이질적인 종속성을 지닌 행동 세트에 잘 적용되지 않는다는 것을 부분적으로 나타낸다.
- MBHT와 MB-STR 모델은 각각 QK-Video와 QK-Article 데이터셋에서 좋은 성능을 보이지 못했으며, 이는 클로즈 태스크(cloze task)용으로 설계된 모델이 다음 아이템 예측에는 잘 맞지 않기 때문일 수 있다 .
- Transformer 기반 모델은 BSSR의 문맥에서 GNN 기반 모델보다 더 나은 성능을 보이는 경향이 있다. SASRec, ICLRec, NextIP의 성능은 두 데이터셋에서 모두 MGNN-SPred보다 우수하다. 이는 셀프 어텐션 메커니즘이 전체 순위 설정 하에서 GNN보다 다음 아이템 예측에 더 적합하다는 것을 반영한다 .
- 우리의 EIDP는 모든 메트릭에서 모든 기준선보다 우수한 성능을 보였으며, QK-Video에서 평균적으로 35.94%, QK-Article에서 3.87%의 유의미한 성능 향상을 나타냈다. 이는 BSSR에 대해 명시적 및 암시적 관점에서 행동 정보를 모델링에 통합하는 것이 실효성 있음을 반영한다.
- 기준선 모델들의 성능은 두 데이터셋에서 큰 변동성을 보였다(예: DuoRec은 QK-Article에서 더 나은 성능을 보이지만 QK-Video에서는 성능이 낮으며, ICLRec은 그 반대의 경향을 보인다). 이는 시나리오 간의 차이를 강조한다.
4.3 Ablation Study (RQ2)
명시적 및 암시적 모델링의 시너지 효과를 입증하기 위해, 두 모델링 관점의 기여 차이를 조사하는 ablation study를 수행하였다. 구체적으로, 우리는 네 가지 구조적 변형을 만들었다:
- EIDP에서 EEL의 아이템 측 입력을 제거한 경우 (w/o (ib) side로 표기),
- 위치 측 입력을 제거한 경우 (w/o (pb) side로 표기),
- EMP를 제거한 경우 (w/o EMP로 표기),
- IMP를 제거한 경우 (w/o IMP로 표기).

Table 2에 결과가 보고되었으며, 다음과 같은 관찰을 할 수 있었다:
- w/o EMP와 w/o IMP의 기여도는 데이터셋에 따라 다르며, 둘 다 EIDP보다 열등한 성능을 보인다. 이는 명시적 및 암시적 모델링 관점의 시너지 효과를 입증한다. w/o EMP는 QK-Video에서 좋은 성능을 보이는 반면, w/o IMP는 QK-Article에서 더 나은 성능을 보인다. 이는 시나리오마다 행동 정보를 효과적으로 모델링하기 위해 서로 다른 접근 방식이 필요함을 나타낸다. 행동 정보를 암시적으로 도입하는 것은 QK-Video와 같이 다음 아이템 예측에서 신호가 덜 명확하고 불확실성이 높은 경우에 더 적합한 반면, QK-Article은 사용자 행동 선호도가 더 장기적인 특성을 가지므로 명시적으로 행동 정보를 통합하는 것이 더 유리하다.
- w/o (pb) side는 두 데이터셋 모두에서 w/o (ib) side보다 일관되게 더 나은 성능을 보인다. 이는 아이템 정보를 제거한 입력으로 어텐션 레이어에 입력하는 것이 성능을 향상시키지 않으며 오히려 해가 될 수 있음을 시사한다.
- EIDP는 w/o (pb) side보다 일관되게 우수한 성능을 보이며, 이는 행동 정보와 위치 정보를 결합하는 것이 유익함을 나타낸다.
- EIDP는 w/o EMP와 w/o IMP보다 일관되게 우수한 성능을 보이며, 명시적 및 암시적 관점을 통합하는 것이 우수하다는 것을 반영한다.
4.4 Exploratory Study (RQ3 & RQ4)
4.4.1 Fusion Module (CBAF)


Figure 3에서 볼 수 있듯이, CBA는 두 데이터셋 모두에서 다른 모든 변형들보다 우수한 성능을 보였다. 이는 CBA의 유효성을 입증한다. IP_CA 융합 방법은 두 데이터셋 모두에서 저조한 성능을 보였고, 반면 가중 평균 기반 방법들은 QK-Article에서 우수한 성능을 나타내어, 시나리오마다 다른 적응형 융합 메커니즘이 필요함을 나타낸다. CBA가 PBS_CA보다 우수한 성능을 보인 것은 사용자별 표현을 지침으로 사용하여 IMP에서 행동 세트 임베딩을 명시적으로 주입하지 않으면 적합하지 않을 수 있음을 보여준다. 여러 관점에서의 협업을 추출하는 것이 더 적절한 접근 방식일 수 있다.
4.4.2 Pattern Extractor (PBS-TPE)
EMP의 핵심 구성 요소인 PBS-TPE가 행동 세트 임베딩을 효과적으로 사용하여 개인화된 행동 패턴을 추출하고 성능을 향상시키는지 조사하기 위해, 우리는 EEL에서의 입력을 제거하고 DCBA에서 HDA를 제거하여 PBS-TPE를 단순한 TPE 구성 요소로 축소시켰다. Figure 4 (왼쪽)에서 PBS-TPE와 TPE의 비교를 통해 PBS-TPE가 명시적으로 주입된 행동 정보와 행동 내 동적 관계를 효과적으로 활용할 수 있음을 확인할 수 있다.
4.4.3 BSSR Reduces to MBSR
EIDP가 행동 세트 내 보조 행동 정보를 충분히 탐색하는지 추가로 검증하기 위해, 우리는 행동 세트에서 가장 높은 선호도 강도를 가진 행동만 유지하여 BSSR을 MBSR로 축소시켰다. 이를 통해 다중-핫 벡터 bℓ을 단일-핫 벡터로 변환하였다.

Figure 4 (오른쪽)에서 결과를 보면, EIDP가 행동 세트 내의 내재적 역학 관계로부터 이점을 얻고 있음을 알 수 있다. 다중-핫 행동 세트 벡터는 한편으로 사용자 요인을 보완하여 개인화된 행동 임베딩을 더 잘 획득할 수 있도록 하며, 다른 한편으로는 해밍 거리 행렬 H의 값 범위를 확장할 수 있다.
4.5 Case Study (RQ5)
우리는 EIDP의 해석 가능성을 위해 일부 샘플 사용자와 함께 사례 연구를 수행하였다. 먼저, 두 사용자인 u2014와 u2900(QK-Article)을 선정하여 HDA에서 학습된 Hu 주의 가중치를 시각화하였다. 이를 통해 EMP가 학습한 개인화된 행동 내 동적 관계를 연구하였다. 주의 점수의 위치 지수에 대응하는 행동 세트의 선호도 강도를 왼쪽과 상단에 막대 차트로 추가하여 제시하였다.
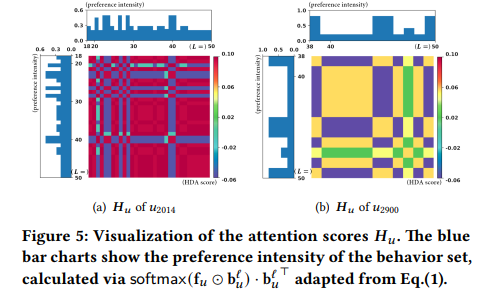
Figure 5에서 볼 수 있듯이:
- Hu가 학습한 점수는 행동 세트의 변화 단계에 민감하다. 주의 점수의 변화는 종종 선호도 강도의 변화를 반영한다.
- HDA는 강도 피크 사이의 가중치에 집중하여 행동 내 동적 관계를 포착한다. 더 높은 선호도 강도에 대응하는 점수는 상대적으로 높은 경우가 많다. 시나리오의 변동성은 사용자 간 주의 점수 범위의 차이로 반영될 수 있다.
두 번째로, IMP에서 추출된 행동 간 협업 공통성을 조사하기 위해, u458와 u260 (QK-Article) 사용자를 선정하여 행동 간 의미적 상관 관계를 반영하는 주의 행렬을 시각화하였다. 또한, 원래 행동 세트 시퀀스에 대한 정보도 제공하였다.

Figure 6을 통해 다음을 관찰할 수 있다:
- 다음 시간 단계의 행동 세트에서 유발된 행동들은 현재 주의 점수에서 강조되는 경우가 많으며, 이는 두 사용자 모두에서 관찰된다.
- 서로 다른 행동들 간의 의미적 수준의 협업은 두 데이터셋 간에 크게 다르다. QK-Video에서는 행동 세트 내에 내재된 선호 신호가 주로 follow 행동에 의해 지배되는 반면, QK-Article에서는 더 다양한 협업 패턴을 나타낸다.
5 RELATED WORK
Single-Behavior Sequential Recommendation (SR)
초기 연구들 [15, 28]은 마코프 체인을 사용하여 아이템 간 전이를 특징화하였다. 딥러닝 모델이 발전하면서, 다양한 네트워크 아키텍처에 기반한 일련의 모델들이 등장하였다. 예를 들어, RNN 기반 모델 [16, 17]과 CNN 기반 모델 [32]이 있다. [19]는 주의 메커니즘을 SR에 도입하여 안정적인 성능을 얻었다. 이후 많은 연구들 [10, 24, 30, 36]이 이를 기반으로 성능 향상을 목표로 하였다. GNN의 구조적 데이터에 대한 적응력은 SR 분야에서도 인기를 끌었으며 [12], GNN 기반 모델의 성공 [2, 3, 21, 45]은 고차원 연결을 효과적으로 포착하는 능력 덕분이다 [12]. 또한, 대조 학습 [6, 27, 33, 38, 40] 및 다양한 DNN 변형 [44, 49]과 같은 최신 기술을 SR에 도입하려는 노력도 있었다. 그러나 이러한 방법들은 주로 사용자 시퀀스에서 한 가지 유형의 행동 (예: 클릭)만 고려하여 사용자-아이템 상호작용의 이질성을 간과하기 때문에, 실제 추천 시나리오에 잘 적응하지 못할 수 있다.
Multi-Behavior Sequential Recommendation (MBSR)
대부분의 MBSR 연구는 딥러닝 기반 알고리즘에 속하며, 이를 기반으로 한 RNN 기반 모델 [7, 22, 23], GNN 기반 모델 [4, 34], Transformer 기반 모델 [13, 14, 26, 29, 42], 및 하이브리드 기술 기반 모델 [37, 41]로 더 세분화할 수 있다 [5]. 최근 제안된 RNN 기반 모델인 DyMuS [7]는 각 행동 유형에 대해 별도의 GRU를 할당하고, 동적 라우팅 알고리즘을 사용하여 인코딩된 표현을 통합한다. MGNN-SPred [34]는 모든 행동 시퀀스로부터 다중 관계 아이템 그래프를 구축하여 전반적인 아이템 간 관계를 학습하는 데 앞장선다. MB-STR [42]는 고전적인 다중 헤드 주의층의 가중치를 행동에 따라 설정하고, 상대적 위치 인코딩 함수와 MMoE를 사용하여 통합한다. STOSA [10]를 따라, PBAT [29]는 분포 임베딩을 사용하여 상호작용 엔티티를 인코딩하고 Wasserstein 거리를 사용하여 상호작용 간의 개인화된 패턴을 측정한다. MBHT [41]는 멀티 스케일 Transformer와 하이퍼그래프를 통해 사용자의 단기 및 장기 선호를 모델링한다.
이 연구들에서 행동 정보를 활용하는 방법을 자세히 살펴보면, 주로 두 가지 주요 관점으로 나눌 수 있다. 하나의 관점은 행동 유형의 라벨을 ID 패러다임 하에 인코딩 엔티티로 취급하는 것이다. 이 접근 방식에서는 모델이 해당 행동 유형에 따라 전역적으로 공유되는 학습 가능한 파라미터를 할당한다 [22, 23, 29, 42]. 다른 관점은 시퀀스를 행동 유형에 따라 분할하고, 각 행동에 특화된 하위 시퀀스를 해당 인코더에 입력하여 다양한 행동 관점에서 표현을 얻는 것이다 [7, 13, 34]. 나머지 방법들 [4, 14, 26, 37, 41] 및 우리의 EIDP는 이 두 가지 측면 모두를 포괄한다.
6 CONCLUSIONS AND FUTURE WORK
이 논문에서는 Behavior Set-Informed Sequential Recommendation (BSSR)이라는 새로운 문제를 정의하고 연구하였으며, 이를 해결하기 위해 Explicit and Implicit modeling via Dual-Path Transformer (EIDP)라는 새로운 솔루션을 제안하였다. 우리는 EIDP의 이중 경로 구조를 소개하며, EMP(Explicit Modeling Path)와 IMP(Implicit Modeling Path)로 구성되어 있다. EMP에서는 개인화된 행동 내 동적 관계를 추출하기 위해 행동 정보와 아이템 및 위치 측면을 밀접하게 결합하는 개인화된 행동 세트 전이 패턴 추출기 (PBS-TPE)를 설계하였다. IMP에서는 경량화된 다중 헤드 자가 주의 블록 (L-MSAB)을 인코더로 사용하여 다양한 행동 특화 관점에서 표현을 추출하였다. 우리는 행동 의미론에서의 행동 간 협업을 포착하고, 이를 Cross-Behavior Attention Fusion (CBAF)을 통해 통합하였다. 두 개의 실제 데이터셋을 사용한 광범위한 실험, 10개의 경쟁력 있는 방법과의 비교, 절단 연구, 탐색적 연구 및 사례 연구를 통해 EIDP의 효과를 입증하였다.