728x90
Temporal-Difference Learning
TD 방식도 마찬가지로 직접적인 경험을 하면서 학습을 하는 알고리즘이다.
DP에서 사용하던 bootstrapping을 사용하고 MD에서 사용하던 Model-free 방식의 장점을 두루 갖추고 있는 것이 특징이다.

MC에서의 value function이 업데이트 되는 과정을 위 왼쪽의 그림과 같이 설명을 하고 있다. 에피소드가 전체적으로 끝나서야 그 보상을 나누어 단계별로 업데이트가 된다.
하지만 TD에서는 각 단계별로 업데이트가 되는 과정을 위 오른쪽 그림과 같이 보여주고 있다.
특히 각 단계별로 얻게 되는 값들이 2~3번 단계에서 MC와 TD에서 달라지는 것을 알수 있다.
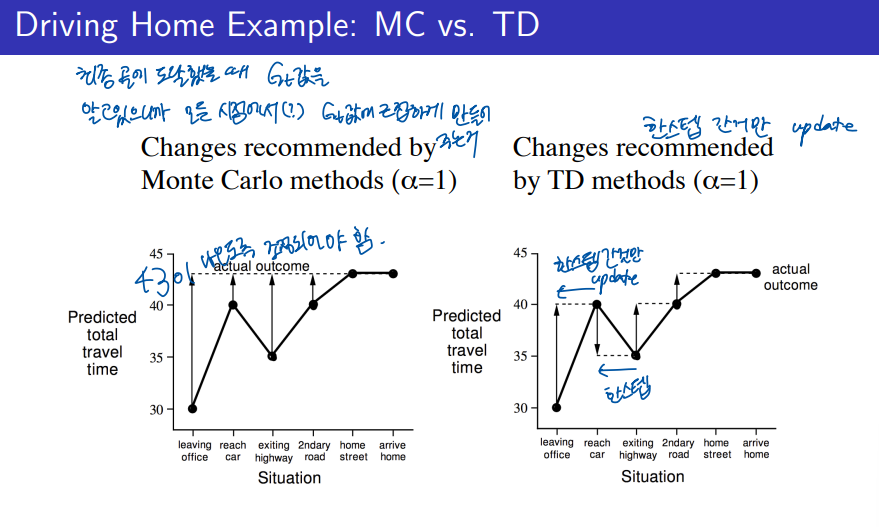
Monte Carlo 방법 (왼쪽 그림)
- MC는 전체 에피소드가 끝난 후 업데이트를 한다.
- 집에 도착한 후에 실제 걸린 총 여행 시간(여기서는 약 43분)이 알려있으니까 그 정보를 기반으로 각 상황에서의 예측된 시간을 수정한다. -> 43분이 나오도록 조정
- 모든 상황에서의 예측을 한 번에 조정한다.
- 예를 들어, "자동차에 도착"한 상황, "고속도로를 나옴" 상황 등에서 예측된 시간을 모두 한꺼번에 실제 결과를 반영해 조정한다.
- 즉, 집에 도착한 후에만 업데이트가 이루어지므로, 에피소드가 끝날 때까지 기다려야 한다.
Temporal Difference 방법 (오른쪽 그림)
- TD는 각 단계마다 업데이트를 한다.
- 매 시점마다 실제 관찰된 시간을 기준으로 예측을 수정해 나간다.
- 예를 들어, "자동차에 도착"했을 때 예측이 잘못되었다면, 그 시점에서 바로 수정하고, 그다음 시점(예: "고속도로를 나옴")에서 또 다시 업데이트한다.
- 이러한 방식은 매 단계마다 실시간으로 업데이트할 수 있어, 즉각적인 피드백을 반영할 수 있다.
Advantages and Disadvantages of MC vs. TD


MC의 특성:
- 높은 분산, 편향 없음: MC 방법은 전체 에피소드를 기반으로 학습하기 때문에, 학습하는 동안의 결과가 여러 요인에 의해 크게 변동할 수 있다. 하지만 평균적으로는 실제 기대 보상과 일치하므로 편향이 없다.
- 수렴 특성이 좋다: 충분히 많은 에피소드가 지나면 정확한 가치 함수로 수렴한다.
- 초기값에 덜 민감하다: 초기 가치 함수의 설정에 크게 영향을 받지 않으며, 장기적으로 평균값에 수렴한다.
- 이해하고 사용하기 쉬움: 개념적으로 직관적이고 간단하다.
TD의 특성:
- 낮은 분산, 일부 편향 있음: TD 방법은 매 시간 스텝마다 학습하므로 분산이 낮다. 하지만 학습 과정에서 추정치에 의존하기 때문에 약간의 편향이 존재할 수 있다.
- 보통 MC보다 더 효율적임: 실시간으로 학습할 수 있어 에피소드가 길지 않더라도 빠르게 수렴할 수 있다.
- TD(0)은 vπ(s)로 수렴: 무한한 업데이트 후에는 정확한 상태 가치 함수로 수렴한다.
- 초기값에 더 민감하다: 초기 설정에 따라 학습 속도와 경로가 달라질 수 있다.
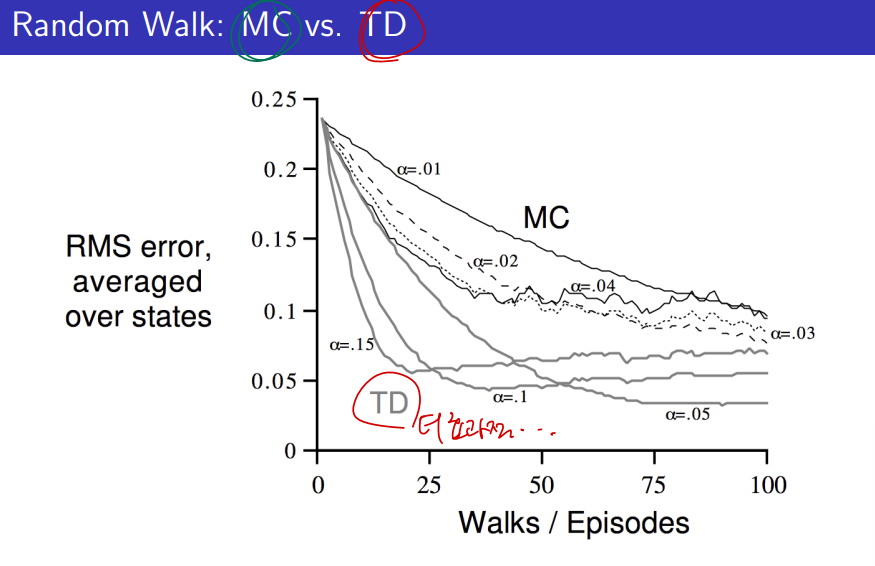

MC, TD 방식 모두 에피소드를 무한하게 반복하게 되면 결국 실제 value 에 수렴하게 된다.
그런데 배치 방식으로 에피소드를 일부만 가지고 계속적으로 학습을 시킨다고 하면 어떻게 될까?




- TD는 Markov 특성을 잘 활용하여 Markov 환경에서 더 효율적이다. 즉, 현재 상태와 다음 상태의 관계만으로 학습을 진행한다.
- MC는 Markov 특성을 활용하지 않으며, 비-마코프 환경에서 유리할 수 있다. 전체 에피소드의 정보를 활용하여 학습하기 때문이다.
MC, TD, DP Backup 비교
1. Monte-Carlo Backup
- 전체 에피소드가 끝난 후에 업데이트를 수행한다.
- 에피소드가 종료된 후, 에피소드 동안의 모든 보상을 합산한 총 보상(Return)을 이용해 상태의 가치를 갱신한다.
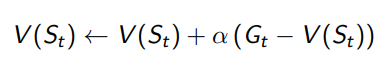
- 한 번의 에피소드에 대한 경험을 바탕으로 백업을 수행한다.
- 장점: 에피소드가 끝나야만 업데이트하기 때문에, 전체 보상의 평균으로 업데이트되며 편향이 없다(Unbiased).
- 단점: 에피소드가 길어질 경우, 업데이트까지 시간이 오래 걸리며, 실시간 학습에 적합하지 않다.
2. Temporal Difference (TD) Backup
- 하나의 시간 단계마다 업데이트를 수행한다.
- 현재 상태의 가치 V(St)를 다음 상태의 예측된 가치 V(St+1)와 현재 보상 Rt+1을 기반으로 갱신한다.
- 업데이트 식:
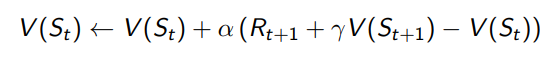
- 즉각적인 업데이트를 통해, 에피소드가 끝나기 전에 학습을 진행할 수 있다.
- 장점: 실시간으로 학습할 수 있어, 빠른 업데이트가 가능하고, Markov 환경에서 더 효율적이다.
- 단점: 샘플 하나에 의존하므로 **편향(Biased)이 있을 수 있지만, 계산이 덜 복잡하고 빠르다.
3. Dynamic Programming (DP) Backup
- 모델 기반의 방법으로, 환경의 전이 확률과 보상 함수가 주어진다고 가정한다.
- 모든 상태에 대해 반복적으로 벨만 방정식을 이용하여 가치 함수를 업데이트한다.
- 업데이트 식:
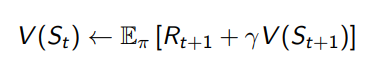
- 정책 평가와 정책 개선을 반복하며 최적의 정책을 찾는다 (즉, Generalized Policy Iteration 방식).
- 장점: 환경에 대한 정확한 모델 정보가 있을 때, 빠르고 안정적으로 수렴한다.
- 단점: 환경의 모델이 필요하며, 상태 공간이 크면 계산이 매우 복잡할 수 있다.
요약 비교
- Monte-Carlo Backup: 에피소드가 끝난 후에 전체 보상을 기반으로 백업. Unbiased, 실시간 학습 어려움.
- TD Backup: 시간 단계마다 즉각적으로 백업. Biased, 실시간 학습 가능.
- DP Backup: 모델 기반 방식으로 전이 확률과 보상 함수를 이용해 반복적으로 백업. 환경의 모델 필요, 정확하지만 계산 복잡.
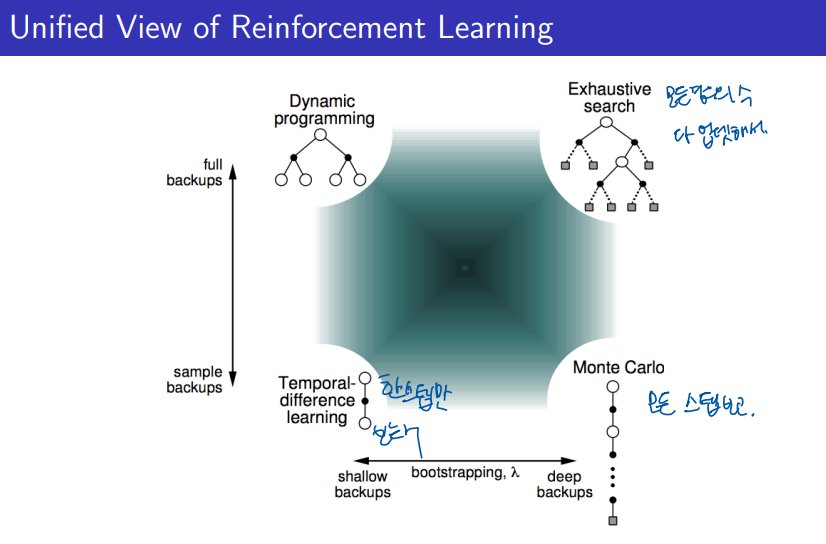
Bootstrapping and Sampling

Bootstrapping
- Bootstrapping이란, 업데이트 과정에서 현재의 추정값을 사용해 업데이트를 수행하는 것을 의미한다.
- 즉, 미래의 보상을 예측할 때 실제 값을 사용하는 것이 아니라, 현재의 가치 함수 추정값을 활용한다.
Bootstrapping의 방법별 차이:
- Monte-Carlo (MC) 방법은 Bootstrapping을 하지 않는다.
- MC는 전체 에피소드가 끝난 후에 실제로 관찰된 총 보상(Return)을 사용하여 상태 가치를 업데이트하기 때문에, 추정값을 이용하지 않는다.
- Dynamic Programming (DP)와 Temporal Difference (TD)는 Bootstrapping을 한다.
- DP는 전이 확률과 보상 함수의 기대값을 사용하여 가치 함수를 업데이트하고, TD는 다음 상태의 추정된 가치 함수 V(St+1)를 사용하여 업데이트한다.
2. Sampling
- Sampling이란, 실제 데이터를 기반으로 기대값을 추정하여 업데이트하는 것을 의미한다.
- 즉, 경험을 통해 수집된 샘플 데이터를 사용하여 상태 가치나 행동 가치를 추정한다.
Sampling의 방법별 차이:
- Monte-Carlo (MC) 방법과 TD 방법은 Sampling을 한다.
- MC는 실제 에피소드 결과를 샘플로 사용하여 총 보상을 계산하고, TD는 시간 스텝마다 수집된 경험을 샘플로 사용해 업데이트한다.
- Dynamic Programming (DP)는 Sampling을 하지 않는다.
- DP는 전이 확률과 보상 함수가 주어진 모델 기반 방법으로, 실제 데이터 샘플을 사용하지 않고 수학적 기대값을 계산하여 업데이트한다.
Monte Carlo (MC) VS Temporal Difference (TD)
Monte Carlo (MC) 방법
- 전체 에피소드가 끝난 후에 업데이트를 한다.
- 즉, 하나의 에피소드(시작부터 종료까지)가 끝날 때까지 기다린 후, 그동안 얻은 총 보상(Return)을 사용해 상태의 가치 함수를 업데이트한다.
- 장점: 각 상태에서의 보상을 장기적으로 평가할 수 있기 때문에, 업데이트가 Unbiased하다.
- 단점: 에피소드가 종료될 때까지 기다려야 하기 때문에, 실시간 학습이나 연속적인 환경에서는 적용이 어렵다.
Temporal Difference (TD) 방법
- 하나의 단계마다(즉, 각 시간 스텝마다) 업데이트를 한다.
- 즉, 매 시간 스텝마다 얻은 보상과 다음 상태의 예측된 가치 함수를 이용해 현재 상태의 가치 함수를 업데이트한다.
- 장점: 에피소드가 종료되지 않아도 학습할 수 있어서 실시간 학습이 가능하다.
- 단점: 업데이트가 샘플 하나에 기반해 이루어지므로, 추정이 Biased일 수 있다.
차이점 요약
- 업데이트 시점:
- MC는 에피소드가 끝난 후 업데이트하고, TD는 매 시간 스텝마다 업데이트한다.
- 데이터 요구:
- MC는 에피소드 전체가 필요하고, TD는 한 번의 샘플만 있어도 업데이트할 수 있다.
- Bias와 Variance:
- MC는 Unbiased하지만 Variance가 클 수 있고, TD는 Biased하지만 Variance가 작다.
출처: https://daeson.tistory.com/328 [대소니:티스토리]
728x90
'AI > RL' 카테고리의 다른 글
| [RL] 3-2 Model-Free Control (1) | 2024.10.12 |
|---|---|
| [RL] 3-1 Model-Free Prediction - (TD lambda) (2) | 2024.10.12 |
| [RL] 3-1 Model-Free Prediction - (MC) (0) | 2024.10.09 |
| [RL] 2-2 Planning by Dynamic Programming (0) | 2024.10.09 |
| [RL] 2-1 Markov Decision Processes (3) | 2024.09.29 |