Planning 의 대표적인 Dynamic programming 에서는 MDP를 이미 알고 있는 것을 Bellman 방정식으로 풀어내는 것이였습니다.
Model-free 는 MDP를 모르는 상황에서 환경과 직접적으로 상호작용을 하면서 경험을 통해서 학습을 하게되는 방식을 말합니다.
Prediction 은 value를 estimate 하는 것을 말하는데 여기서는 model-free 에서 prediction이므로 MDP를 모르는 상태에서 (환경에 대한 사전지식이 없는 상태에서) 환경과 상호 작용을 하며 value function을 추정해 가는 방식을 말합니다.
control 은 이렇게 찾은 value function을 최적화하여 최적의 poilcy를 찾는 것을 말합니다.
대표적인 Model-free 방식에 Monte-Carlo Learning과 Temporal-Difference Learning이 있다.
Monte-Carlo Learning

MC는 에피소드에서 경험을 하면서 직접 환경에 대해서 학습하는 방법이다.
MDP에 대한 사전 지식이 없고 모델이 없어서 알려주는 이도 없으므로 trasition / reward 에 대한 정보를 전혀 모르는 상태에서 시작한다.
항상 에피소드가 완료가 되어 최종적으로 받게 되는 보상을 통해서 평균적으로 학습을 하게 되므로 bootstrapping이 아니다.
MC에서는 간단하게 에피소드가 종료된 후에 받게 되는 보상의 평균값들이 value로 사용이 된다.
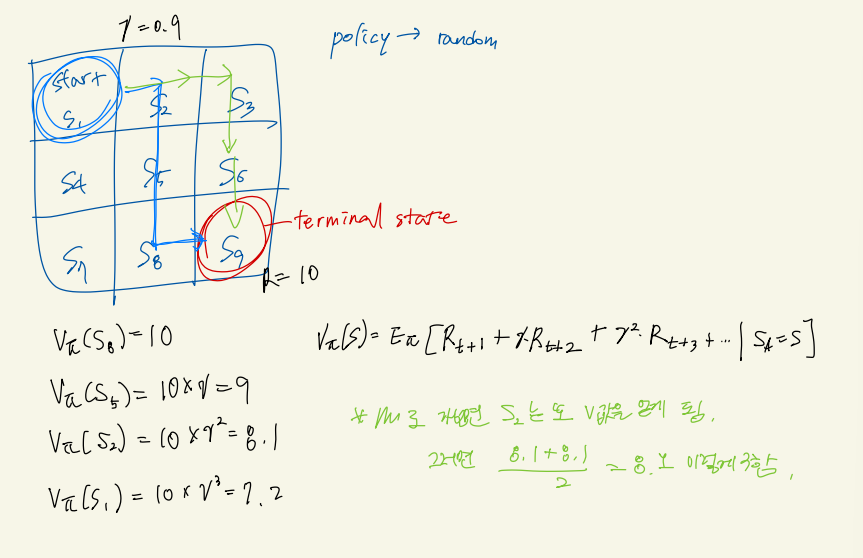
state를 evaluate하기 위해서는 크게 2가지 방법이 있다.

하나는 first visit MC 방식이다. 에피소드에서 하나의 state를 여러번 지나갈 수 있을 것입니다. 이때 해당 state에 첫번째 방문 했을때의 value만을 사용하는 방식이다. 에피소드가 여러번 진행이 되므로 각 에피소드에 대한 평균으로 value를 추정한다.
에피소드가 충분히 무한대로 진행이 되게 되면 이렇게 평균값으로 추정한 value가 최적화된 실제 value와 같게 되고 이를 통해서 policy를 업데이트 하면 우리가 원하는 최적의 정책을 찾을 수 있게 된다.

다른 하나는 every visit MC 방식입니다. 하나의 states를 두번이상 지나갔다면 이때의 모든 value를 각각 사용하여 평균내어 추정하는 방식이다.
ex)
출발점이 (0,0)이고 도착점이 (2,2)인 경우를 생각해보자. 예를 들어 에이전트가 다음과 같은 경로로 이동했다고 하자:
(0,0)→(0,1)→(1,1)→(2,1)→(1,1)→(2,2)
이 경로에서 상태 (1,1)을 두 번 방문했다. 이때 First-Visit Monte Carlo와 Every-Visit Monte Carlo가 어떻게 계산하는지 비교해보자.
1. First-Visit Monte Carlo
- 첫 번째 방문만 고려하여 가치 함수를 업데이트한다.
- 경로에서 (1,1)(1,1)을 처음 방문한 시점은 세 번째 상태였다. 따라서, (1,1)(1,1)의 가치 함수 업데이트는 첫 번째 방문에서의 보상만 사용하여 계산된다.
- 예를 들어, 목표지점 (2,2)(2,2)에서 얻은 보상이 +1이라면, (1,1)(1,1)의 가치는 첫 번째 방문 시점부터 계산된 보상의 총합을 바탕으로 업데이트된다.
2. Every-Visit Monte Carlo
- 모든 방문을 고려하여 가치 함수를 업데이트한다.
- 경로에서 (1,1)(1,1)을 두 번 방문했기 때문에, 두 번 방문한 시점의 보상 평균을 사용해 가치 함수를 계산한다.
- 예를 들어, 첫 번째 방문 시점과 두 번째 방문 시점 모두 +1의 보상을 받았다면, 두 방문의 보상을 평균하여 가치 함수를 업데이트한다.
차이점 정리
- First-Visit Monte Carlo는 에피소드 중에 각 상태를 처음 방문한 시점만 고려하므로, (1,1)(1,1)의 첫 방문만 반영해 업데이트한다.
- Every-Visit Monte Carlo는 에피소드에서 방문한 모든 시점의 정보를 사용하므로, (1,1)(1,1)의 두 번의 방문 모두 반영하여 평균을 구해 업데이트한다.
Unbiased Vs biased ?
First-Visit Monte Carlo가 Unbiased이고 Every-Visit Monte Carlo가 Biased인 이유는, 두 방법이 에피소드에서 같은 상태를 여러 번 방문했을 때의 처리 방식이 다르기 때문이다.
1. First-Visit Monte Carlo (Unbiased)
- Unbiased라는 것은 추정값이 장기적으로 실제 기대값과 일치하는 것을 의미한다.
- First-Visit Monte Carlo는 각 상태를 처음 방문한 시점의 보상만 사용해 추정하기 때문에, 중복된 방문으로 인한 왜곡이 발생하지 않는다.
- 따라서, 여러 에피소드에 걸쳐 충분히 많은 데이터를 모았을 때, 상태의 가치 함수는 실제 기대 보상과 일치하게 된다. 이는 편향되지 않은(Unbiased) 추정이 된다.
2. Every-Visit Monte Carlo (Biased)
- Every-Visit Monte Carlo는 에피소드 중에 같은 상태를 여러 번 방문했을 때, 그 모든 방문의 보상을 사용해 평균을 구한다.
- 하지만 이런 방식은 상태가 자주 방문될수록 더 많은 업데이트를 하게 되어, 추정이 중복 방문 횟수에 의해 편향될 수 있다.
- 특히 상태가 여러 번 방문되는 특정 패턴을 가진 경우, 그 상태의 가치가 과대평가되거나 과소평가될 가능성이 있어, Biased 추정으로 이어질 수 있다.
요약하자면:
- First-Visit Monte Carlo는 각 상태의 첫 방문만 고려하므로, Unbiased 추정을 제공한다.
- Every-Visit Monte Carlo는 모든 방문을 고려하여, 특정 상태를 자주 방문하면 보상이 편향될 수 있어 Biased 추정이 된다.

증분 평균(incremental mean)은 데이터가 순차적으로 들어올 때, 모든 데이터를 다시 계산하지 않고도 평균을 갱신할 수 있는 방법이다. 이 방법은 새로운 값이 추가될 때마다 이전 평균을 이용해 효율적으로 새로운 평균을 계산한다.
위의 그림 예시를 계산해보자.


참고: https://daeson.tistory.com/327 [대소니:티스토리]
'AI > RL' 카테고리의 다른 글
| [RL] 3-1 Model-Free Prediction - (TD lambda) (2) | 2024.10.12 |
|---|---|
| [RL] 3-1 Model-Free Prediction - (TD) (0) | 2024.10.09 |
| [RL] 2-2 Planning by Dynamic Programming (0) | 2024.10.09 |
| [RL] 2-1 Markov Decision Processes (3) | 2024.09.29 |
| [RL] 1-1 Introduction to Reinforcement Learning (4) | 2024.09.27 |
Planning 의 대표적인 Dynamic programming 에서는 MDP를 이미 알고 있는 것을 Bellman 방정식으로 풀어내는 것이였습니다.
Model-free 는 MDP를 모르는 상황에서 환경과 직접적으로 상호작용을 하면서 경험을 통해서 학습을 하게되는 방식을 말합니다.
Prediction 은 value를 estimate 하는 것을 말하는데 여기서는 model-free 에서 prediction이므로 MDP를 모르는 상태에서 (환경에 대한 사전지식이 없는 상태에서) 환경과 상호 작용을 하며 value function을 추정해 가는 방식을 말합니다.
control 은 이렇게 찾은 value function을 최적화하여 최적의 poilcy를 찾는 것을 말합니다.
대표적인 Model-free 방식에 Monte-Carlo Learning과 Temporal-Difference Learning이 있다.
Monte-Carlo Learning
MC는 에피소드에서 경험을 하면서 직접 환경에 대해서 학습하는 방법이다.
MDP에 대한 사전 지식이 없고 모델이 없어서 알려주는 이도 없으므로 trasition / reward 에 대한 정보를 전혀 모르는 상태에서 시작한다.
항상 에피소드가 완료가 되어 최종적으로 받게 되는 보상을 통해서 평균적으로 학습을 하게 되므로 bootstrapping이 아니다.
MC에서는 간단하게 에피소드가 종료된 후에 받게 되는 보상의 평균값들이 value로 사용이 된다.
state를 evaluate하기 위해서는 크게 2가지 방법이 있다.
하나는 first visit MC 방식이다. 에피소드에서 하나의 state를 여러번 지나갈 수 있을 것입니다. 이때 해당 state에 첫번째 방문 했을때의 value만을 사용하는 방식이다. 에피소드가 여러번 진행이 되므로 각 에피소드에 대한 평균으로 value를 추정한다.
에피소드가 충분히 무한대로 진행이 되게 되면 이렇게 평균값으로 추정한 value가 최적화된 실제 value와 같게 되고 이를 통해서 policy를 업데이트 하면 우리가 원하는 최적의 정책을 찾을 수 있게 된다.
다른 하나는 every visit MC 방식입니다. 하나의 states를 두번이상 지나갔다면 이때의 모든 value를 각각 사용하여 평균내어 추정하는 방식이다.
ex)
출발점이 (0,0)이고 도착점이 (2,2)인 경우를 생각해보자. 예를 들어 에이전트가 다음과 같은 경로로 이동했다고 하자:
(0,0)→(0,1)→(1,1)→(2,1)→(1,1)→(2,2)
이 경로에서 상태 (1,1)을 두 번 방문했다. 이때 First-Visit Monte Carlo와 Every-Visit Monte Carlo가 어떻게 계산하는지 비교해보자.
1. First-Visit Monte Carlo
- 첫 번째 방문만 고려하여 가치 함수를 업데이트한다.
- 경로에서 (1,1)(1,1)을 처음 방문한 시점은 세 번째 상태였다. 따라서, (1,1)(1,1)의 가치 함수 업데이트는 첫 번째 방문에서의 보상만 사용하여 계산된다.
- 예를 들어, 목표지점 (2,2)(2,2)에서 얻은 보상이 +1이라면, (1,1)(1,1)의 가치는 첫 번째 방문 시점부터 계산된 보상의 총합을 바탕으로 업데이트된다.
2. Every-Visit Monte Carlo
- 모든 방문을 고려하여 가치 함수를 업데이트한다.
- 경로에서 (1,1)(1,1)을 두 번 방문했기 때문에, 두 번 방문한 시점의 보상 평균을 사용해 가치 함수를 계산한다.
- 예를 들어, 첫 번째 방문 시점과 두 번째 방문 시점 모두 +1의 보상을 받았다면, 두 방문의 보상을 평균하여 가치 함수를 업데이트한다.
차이점 정리
- First-Visit Monte Carlo는 에피소드 중에 각 상태를 처음 방문한 시점만 고려하므로, (1,1)(1,1)의 첫 방문만 반영해 업데이트한다.
- Every-Visit Monte Carlo는 에피소드에서 방문한 모든 시점의 정보를 사용하므로, (1,1)(1,1)의 두 번의 방문 모두 반영하여 평균을 구해 업데이트한다.
Unbiased Vs biased ?
First-Visit Monte Carlo가 Unbiased이고 Every-Visit Monte Carlo가 Biased인 이유는, 두 방법이 에피소드에서 같은 상태를 여러 번 방문했을 때의 처리 방식이 다르기 때문이다.
1. First-Visit Monte Carlo (Unbiased)
- Unbiased라는 것은 추정값이 장기적으로 실제 기대값과 일치하는 것을 의미한다.
- First-Visit Monte Carlo는 각 상태를 처음 방문한 시점의 보상만 사용해 추정하기 때문에, 중복된 방문으로 인한 왜곡이 발생하지 않는다.
- 따라서, 여러 에피소드에 걸쳐 충분히 많은 데이터를 모았을 때, 상태의 가치 함수는 실제 기대 보상과 일치하게 된다. 이는 편향되지 않은(Unbiased) 추정이 된다.
2. Every-Visit Monte Carlo (Biased)
- Every-Visit Monte Carlo는 에피소드 중에 같은 상태를 여러 번 방문했을 때, 그 모든 방문의 보상을 사용해 평균을 구한다.
- 하지만 이런 방식은 상태가 자주 방문될수록 더 많은 업데이트를 하게 되어, 추정이 중복 방문 횟수에 의해 편향될 수 있다.
- 특히 상태가 여러 번 방문되는 특정 패턴을 가진 경우, 그 상태의 가치가 과대평가되거나 과소평가될 가능성이 있어, Biased 추정으로 이어질 수 있다.
요약하자면:
- First-Visit Monte Carlo는 각 상태의 첫 방문만 고려하므로, Unbiased 추정을 제공한다.
- Every-Visit Monte Carlo는 모든 방문을 고려하여, 특정 상태를 자주 방문하면 보상이 편향될 수 있어 Biased 추정이 된다.
증분 평균(incremental mean)은 데이터가 순차적으로 들어올 때, 모든 데이터를 다시 계산하지 않고도 평균을 갱신할 수 있는 방법이다. 이 방법은 새로운 값이 추가될 때마다 이전 평균을 이용해 효율적으로 새로운 평균을 계산한다.
위의 그림 예시를 계산해보자.
참고: https://daeson.tistory.com/327 [대소니:티스토리]
'AI > RL' 카테고리의 다른 글
| [RL] 3-1 Model-Free Prediction - (TD lambda) (2) | 2024.10.12 |
|---|---|
| [RL] 3-1 Model-Free Prediction - (TD) (0) | 2024.10.09 |
| [RL] 2-2 Planning by Dynamic Programming (0) | 2024.10.09 |
| [RL] 2-1 Markov Decision Processes (3) | 2024.09.29 |
| [RL] 1-1 Introduction to Reinforcement Learning (4) | 2024.09.27 |