Object Detection
Object Detection에는 여러가지 기법이 있다.
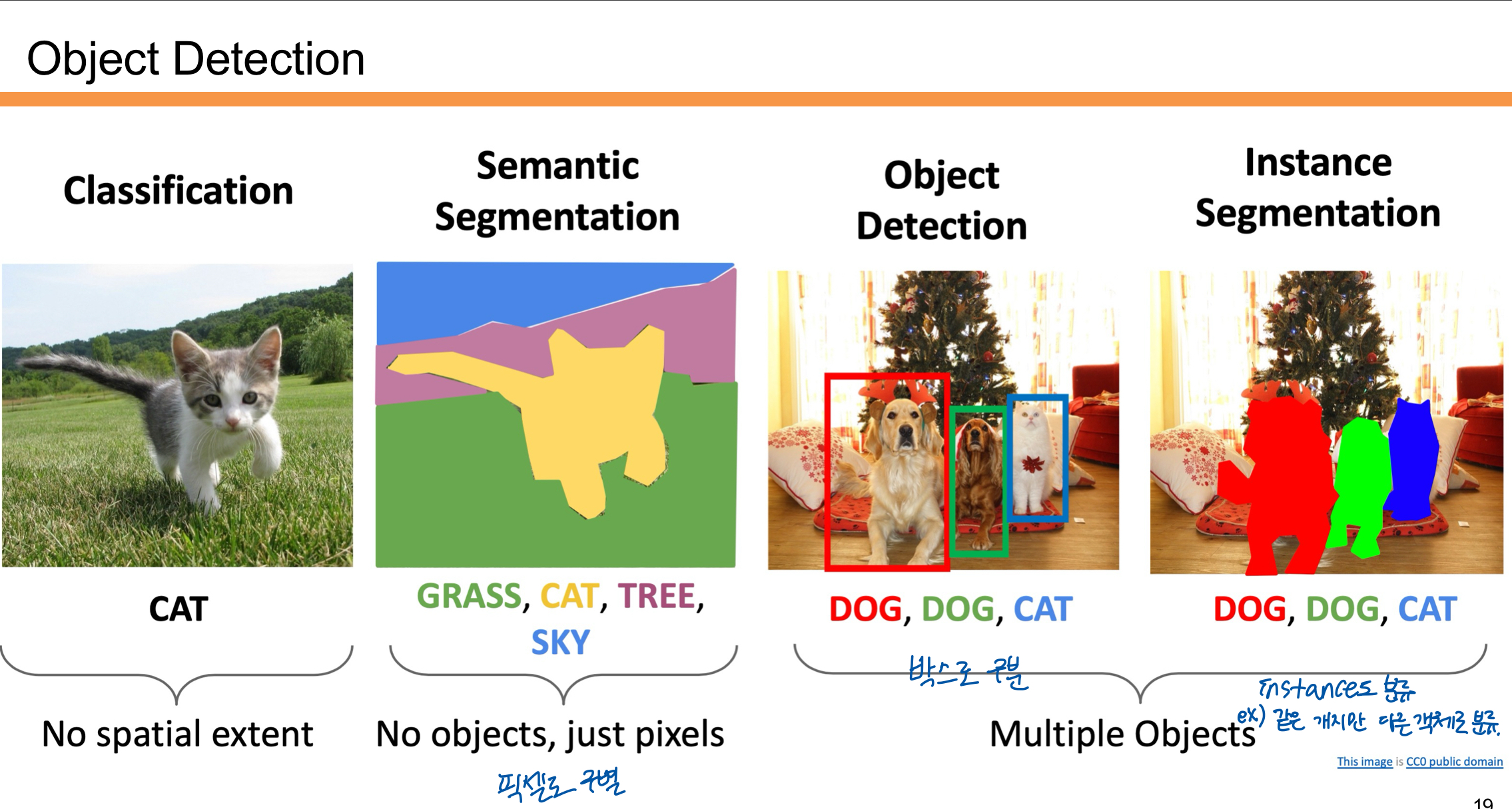
- Classification:
이미지를 보고 무엇이 있는지를 예측함. 예를 들어 "고양이"라는 클래스만 반환함. 위치 정보는 제공하지 않음. - Semantic Segmentation:
이미지를 픽셀 단위로 분류하여 각 픽셀이 어떤 클래스에 속하는지를 나타냄. 객체의 개수는 구분하지 않고 모든 픽셀을 분할함. - Object Detection:
이미지에서 객체의 종류와 위치를 찾아냄. 바운딩 박스(박스로 감싸는 형태)를 통해 객체를 구분함. - Instance Segmentation:
객체의 종류와 위치를 찾는 것에 더해, 각 객체를 픽셀 단위로 세밀하게 분할함. 같은 클래스라도 서로 다른 객체로 인식함.
여기서 우리는 Object Detection의 기법을 살펴 볼 것이다. 박스로 객체를 구분하는 것이다. 자세한 기법을 살펴보기전에 우선 알아보아야 할 개념인 IoU에 대해 살펴보자.
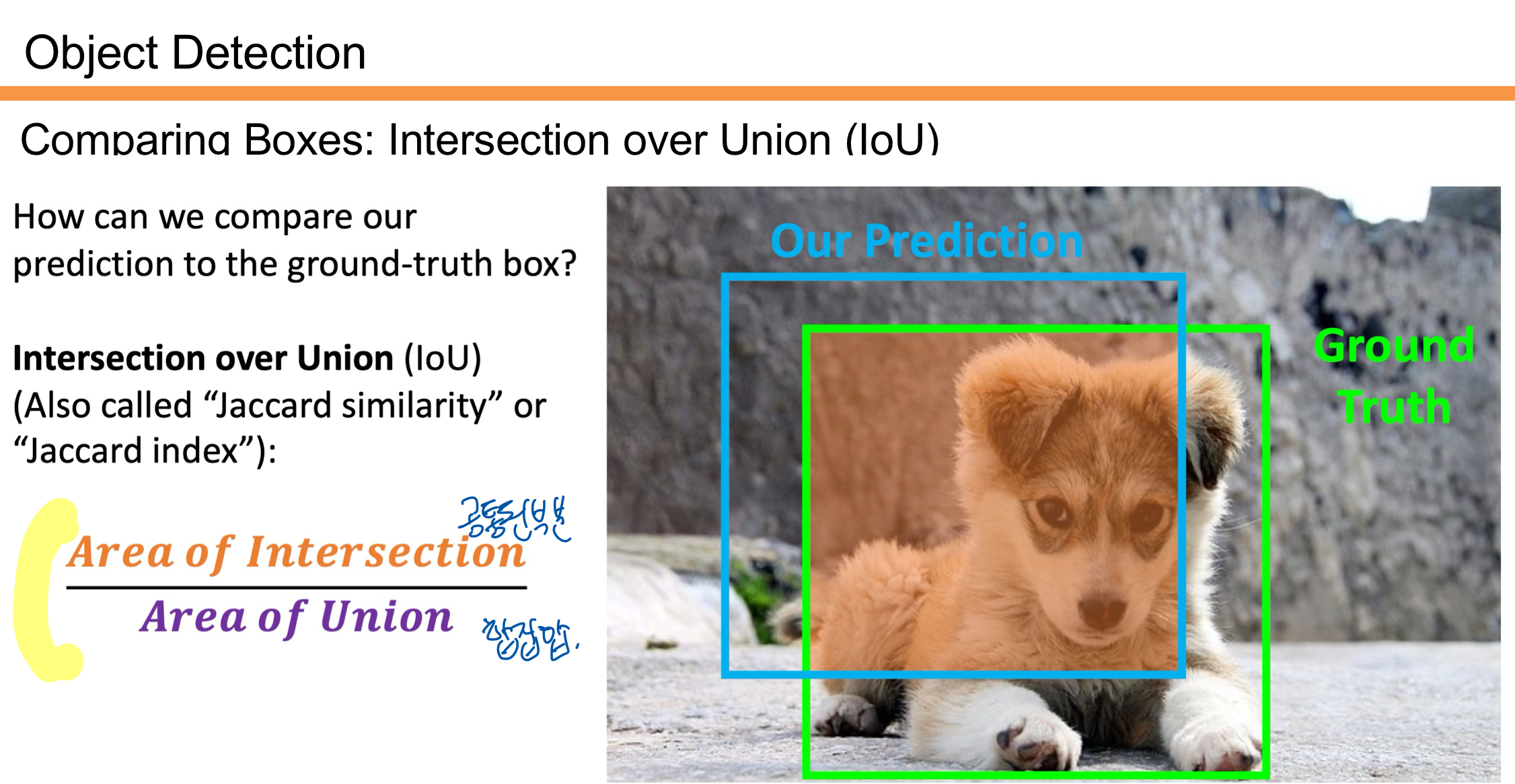
IoU는 객체 탐지에서 예측한 박스(Our Prediction)와 실제 정답 박스(Ground Truth)가 얼마나 겹치는지를 평가하는 지표이다. 공식은 겹친 영역(Area of Intersection)을 전체 영역(Area of Union)으로 나눈 값으로 표현한다.
- 값이 1에 가까울수록 예측 박스와 정답 박스가 잘 일치한다는 의미임.
- 0에 가까울수록 예측이 부정확하다는 의미임.
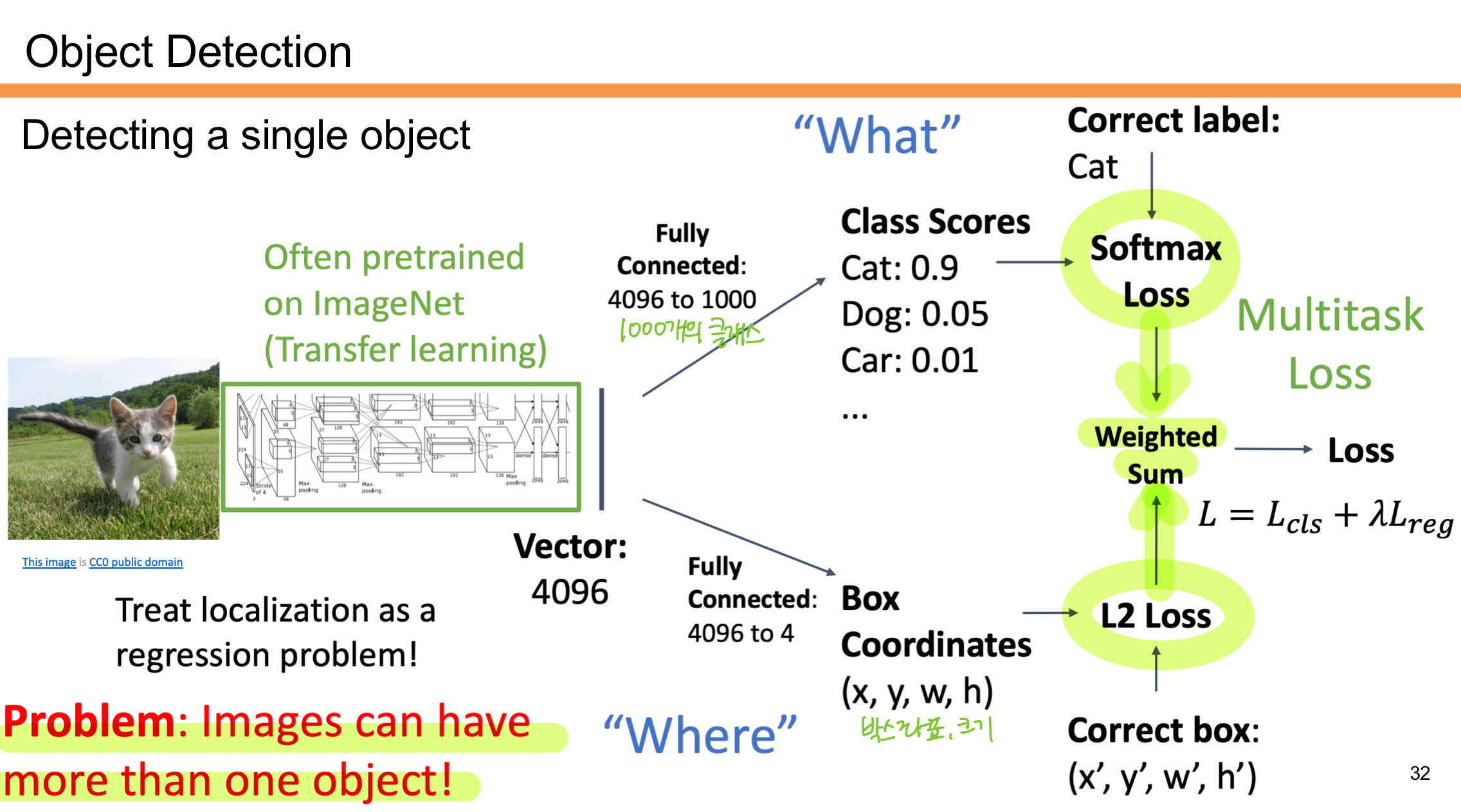
위의 사진은 Object Detectio에서 단일 객체를 탐지하는 초기 방법을 설명한다.
- What
객체가 무엇인지 예측한다.- Softmax Loss를 통해 객체의 클래스 점수(ex: 고양이 0.9, 강아지 0.05)를 계산함.
- 클래스 분류는 ImageNet 데이터로 사전 학습된 네트워크를 사용하여 진행함.
- Where
객체의 위치를 찾는다.- 바운딩 박스 좌표 (x, y, w, h)를 회귀 문제로 다룸.
- L2 Loss를 사용해 예측된 박스와 실제 박스(정답)의 차이를 최소화함.
- Multitask Loss:
클래스 분류와 위치 예측의 손실을 함께 최적화함.- 최종 Loss는 두 손실의 가중합으로 계산됨. (L = Lcls + λLreg)
문제는 이미지에 여러 객체가 존재할 수 있다는 것이다. 예를 들어 콘서트장에 사람을 일일히 바운딩 박스를 친다고 하면.. 시간이 엄청 오래 걸릴 것이다. 이를 해결하기 위해 이후 고도화된 Object Detection 모델들이 등장하게 된다.
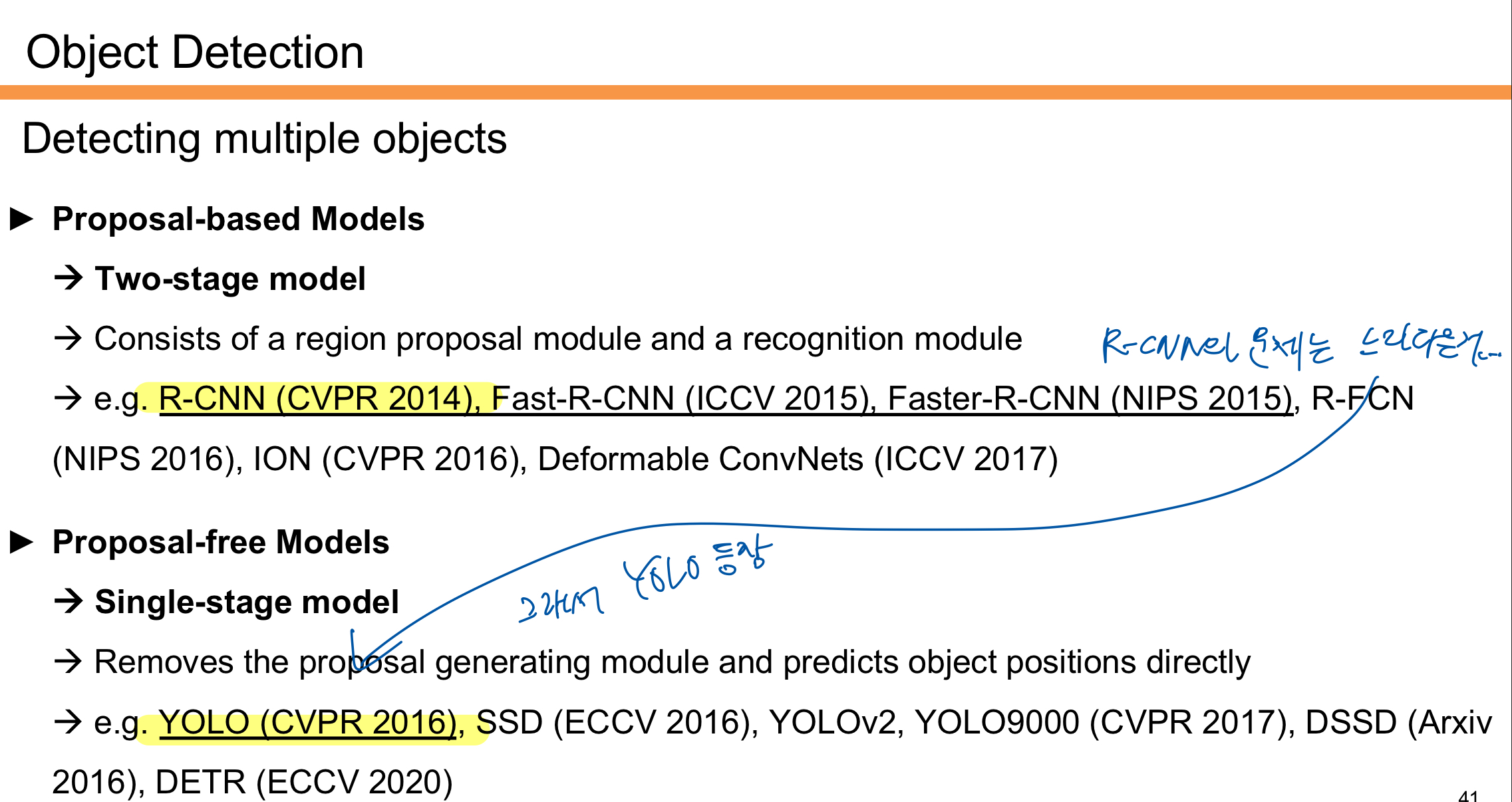
Proposal-based Models는 Two-stage 모델로, 먼저 후보 영역(Region Proposal)을 생성한 후 객체를 분류하고 위치를 예측한다. 대표적으로 R-CNN(2014), Fast R-CNN(2015), Faster R-CNN(2015) 등이 있다. 이 모델들은 정확도가 높지만 처리 속도가 느리다는 단점이 있다. 그래서 RP를 생략하는 모델인 YOLO가 등장하게 된다.
Proposal-free Models는 Single-stage 모델로, 후보 영역 생성 과정을 생략하고 객체 위치를 직접 예측한다. 대표적으로 YOLO(2016), SSD(2016)가 있다. 이 모델들은 속도가 빠르고 실시간 탐지가 가능하지만 상대적으로 정확도가 낮을 수 있다.
R-CNN
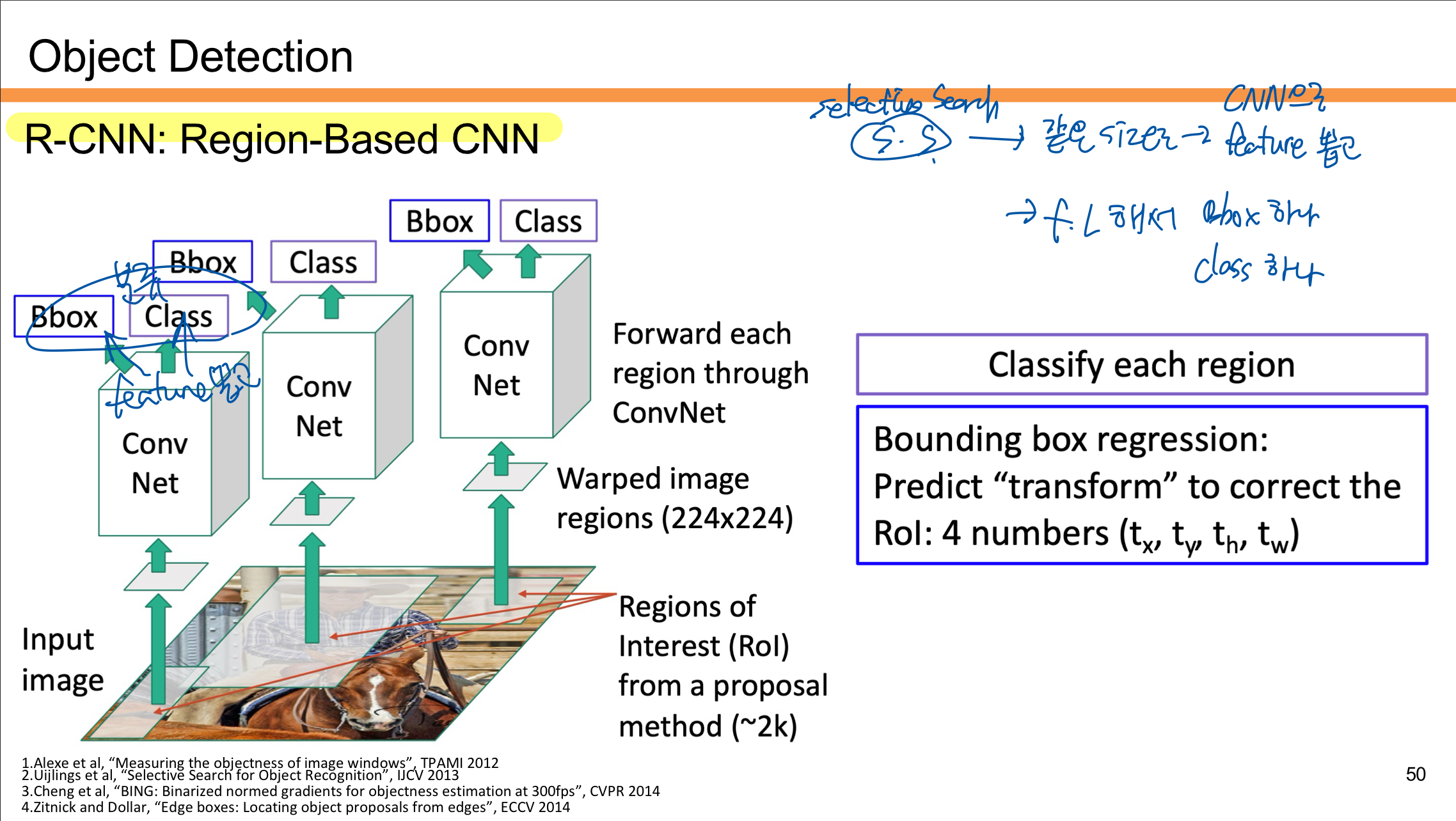
R-CNN 동작 과정
- Region Proposal 생성
입력 이미지를 바탕으로 Selective Search와 같은 방법을 사용해 Region of Interest (RoI)를 생성한다.- 약 2,000개의 후보 영역이 생성된다.
- Region Warping
각 후보 영역을 고정된 크기(224x224)로 변환하여 CNN이 처리할 수 있도록 한다. - Feature Extraction
변환된 각각의 영역을 Convolutional Neural Network(CNN)에 통과시켜 특징(feature)을 추출한다.- 이 단계에서 동일한 크기의 입력에서 각 후보 영역에 대한 특징 벡터가 생성된다.
- Classification and Bounding Box Regression
- Class 예측: 각 RoI의 특징을 Fully Connected Layer를 통해 분류하고, 객체의 클래스(예: 고양이, 개)를 예측한다.
- Bounding Box Regression: 후보 영역의 위치를 보정하기 위해 4개의 값을 예측한다. 이 값들은 바운딩 박스의 변환 정보(tx, ty, th, tw)를 나타낸다.
- 결과 출력
각 후보 영역에 대해 클래스와 보정된 바운딩 박스를 출력한다.
이렇게 R-CNN 방법을 이용했을 때 output box들이 overlapping되는 문제가 발생한다. 같은 객체에 박스가 여러개 쳐지는 것이다. 이런 문제를 해결하기 위해 NMS 개념이 등장한다.
NMS (Non-Max Suppression)

R-CNN은 같은 객체에 대해 여러 개의 겹치는 바운딩 박스를 출력하는 문제가 있어 이를 해결하기 위해 NMS를 적용한다.
- 확률(Confidence Score)이 가장 높은 바운딩 박스를 먼저 선택한다.
- 선택된 박스와 겹치는 정도(Intersection over Union, IoU)가 특정 임계값(예: 0.7)을 넘는 다른 낮은 점수의 박스들은 제거한다.
- 남아 있는 바운딩 박스가 있으면 1단계를 반복한다.
위의 그림에서는 두마리의 "dog"에 대한 바운딩 박스가 보인다.
- 확률이 가장 높은 박스(각 강아지 개체마다)는 P(dog) = 0.9, 0.75이며, 이 박스가 우선 선택된다.
- 이후 다른 박스들(P(dog) = 0.8, 0.7)은 제거된다.
결과적으로 NMS는 겹치는 바운딩 박스 중 가장 신뢰도 높은 박스만 남기고 나머지를 제거해 최종 탐지 결과를 정리한다.
Fast R-CNN
등장 배경
R-CNN은 객체 탐지 과정에서 약 2,000개의 후보 영역(Region Proposal)을 생성하고, 각 영역을 개별적으로 CNN에 통과시켜 특징을 추출한다. 이 과정에서 CNN을 반복적으로 실행해야 하기 때문에 연산량이 매우 많고 시간이 오래 걸렸다.
Fast R-CNN은 이 문제를 해결하기 위해 이미지 전체에서 한 번만 CNN에 통과시킨 후, 생성된 특징 맵에서 후보 영역(Region Proposal)의 특징을 추출하는 방법을 도입했다. 이를 통해 연산량을 획기적으로 줄였다.
핵심 개선점
- CNN 연산을 한 번만 수행하여 속도를 크게 향상시켰다.
- 후보 영역의 특징을 RoI Pooling으로 효율적으로 추출한다.
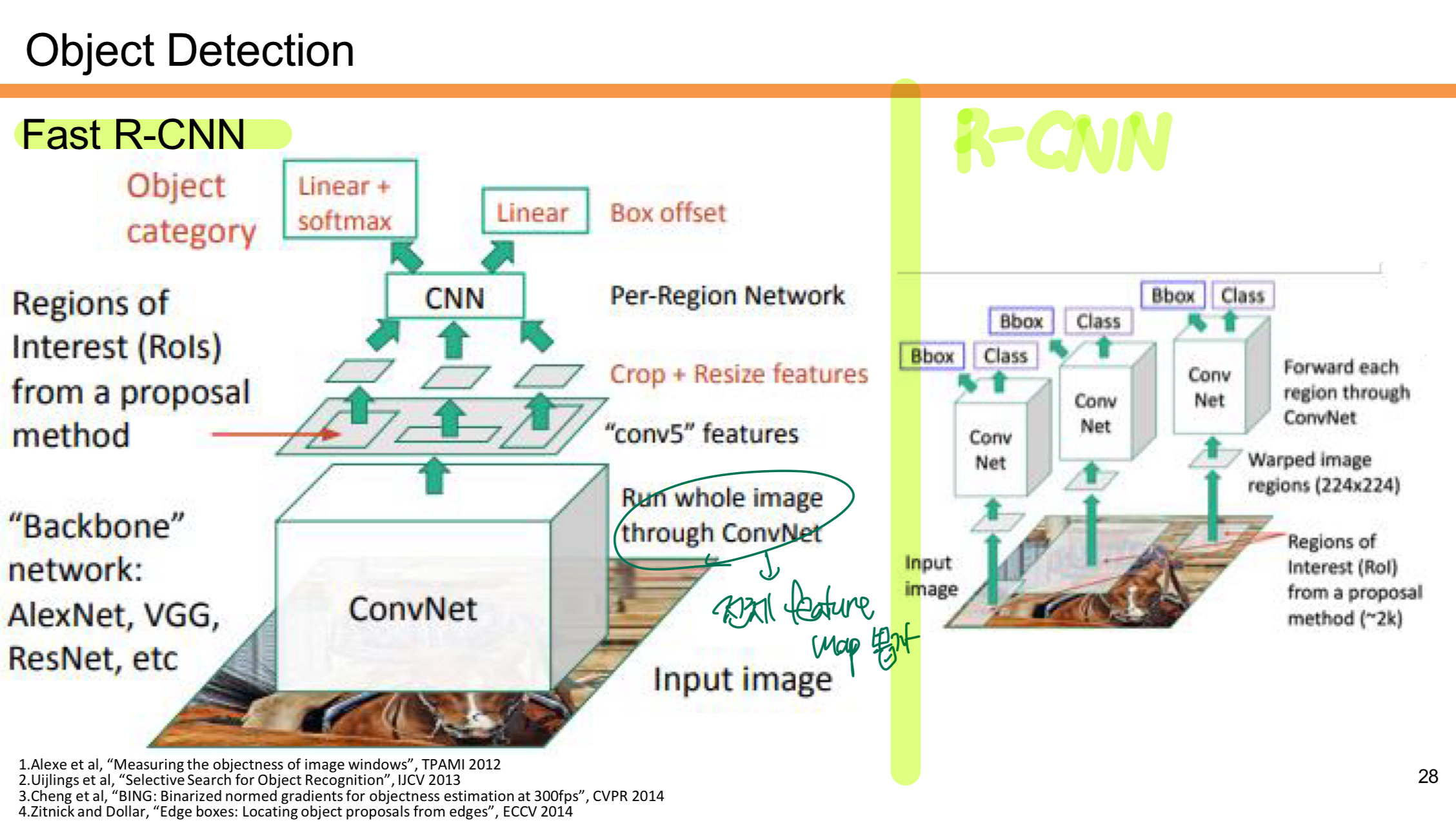
1. R-CNN 동작 과정
- 입력 이미지를 받아 Selective Search와 같은 방법으로 약 2,000개의 후보 영역(Region Proposals)을 생성한다.
- 각 후보 영역을 고정된 크기(224x224)로 변환한 후 CNN에 개별적으로 통과시켜 특징을 추출한다.
- 즉, 2,000번의 CNN Forward Pass가 필요하므로 매우 비효율적이다.
- 추출된 특징은 SVM으로 분류되고, Bounding Box Regression을 통해 위치를 보정한다.
2. Fast R-CNN 동작 과정
- 입력 이미지 전체를 한 번만 CNN에 통과시켜 Feature Map을 생성한다.
- 이미지 전체에서 공통된 특징 맵을 추출하기 때문에 CNN 연산이 한 번만 수행된다.
- Region Proposal은 여전히 Selective Search를 통해 생성되지만,
- 이 후보 영역들은 Feature Map에서 해당 영역을 Crop(잘라내고) Resize한다.
- 이를 통해 각 Region Proposal에 대한 특징을 Feature Map에서 효율적으로 추출한다.
- 추출된 특징을 RoI Pooling을 통해 고정된 크기로 변환한다.
- 각 Region의 특징은 Fully Connected Layer를 통과하여 객체의 클래스를 예측하고, 동시에 Bounding Box Regression을 통해 바운딩 박스의 위치를 보정한다.
R-CNN vs Fast R-CNN 비교
| 비교 항목 | R-CNN | Fast R-CNN |
| CNN 연산 횟수 | 후보 영역(약 2,000개)마다 CNN을 수행 (비효율적) | 이미지 전체를 CNN에 한 번만 통과 (효율적) |
| Feature Extraction | 개별 후보 영역에서 특징 추출 | 전체 Feature Map에서 후보 영역의 특징 추출 |
| Region Proposal | Selective Search 사용 | Selective Search 사용 |
| 속도 | 느림 (2,000번 Forward Pass) | 빠름 (1번의 Forward Pass) |
| RoI Pooling | 없음 | 후보 영역을 Feature Map에서 고정된 크기로 변환 |
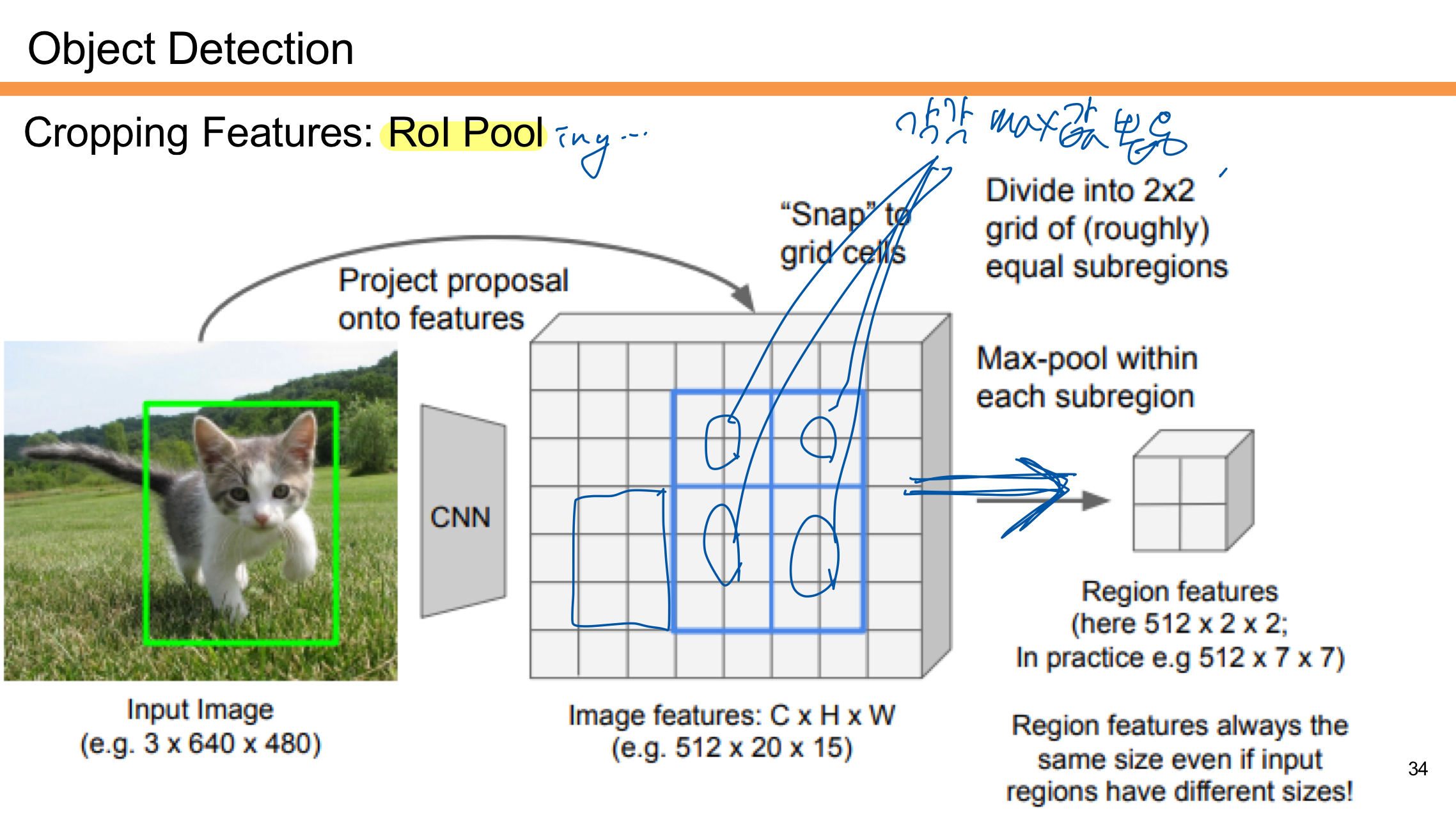
- Region Proposal: 입력 이미지에서 생성된 후보 영역(Region Proposal)을 CNN을 통해 Feature Map으로 매핑한다.
- Grid 분할: 해당 후보 영역을 2x2 또는 더 세밀한 격자(Grid)로 나눈다.
- Max-Pooling 적용: 각 격자(Subregion) 내에서 Max-Pooling을 수행해 가장 큰 값을 선택한다.
- 고정된 크기의 출력: 다양한 크기의 후보 영역도 RoI Pooling을 통해 항상 고정된 크기의 특징 맵(예: 7x7, 2x2 등)으로 변환된다.
RoI Pooling은 입력 후보 영역의 크기가 다르더라도 동일한 크기의 Region Features를 생성하며, 이를 통해 Fully Connected Layer에 전달할 수 있게 된다.
Faster R-CNN

Faster R-CNN은 기존 Fast R-CNN의 Region Proposal 단계를 개선하기 위해 Region Proposal Network (RPN)을 도입한 모델이다.
1. Region Proposal Network (RPN)의 도입
- 더 이상 Selective Search와 같은 외부 Region Proposal 기법이 필요하지 않다.
- 대신 RPN이 CNN Feature Map을 기반으로 후보 영역(Region Proposal)을 직접 생성한다.
2. Stage 1: RPN 훈련
- Anchor Boxes를 사용하여 후보 영역을 설정한다.
- 각 위치에서 3개의 비율(1:1, 1:2, 2:1)과 3개의 크기를 조합해 총 9개의 Anchor를 사용한다.
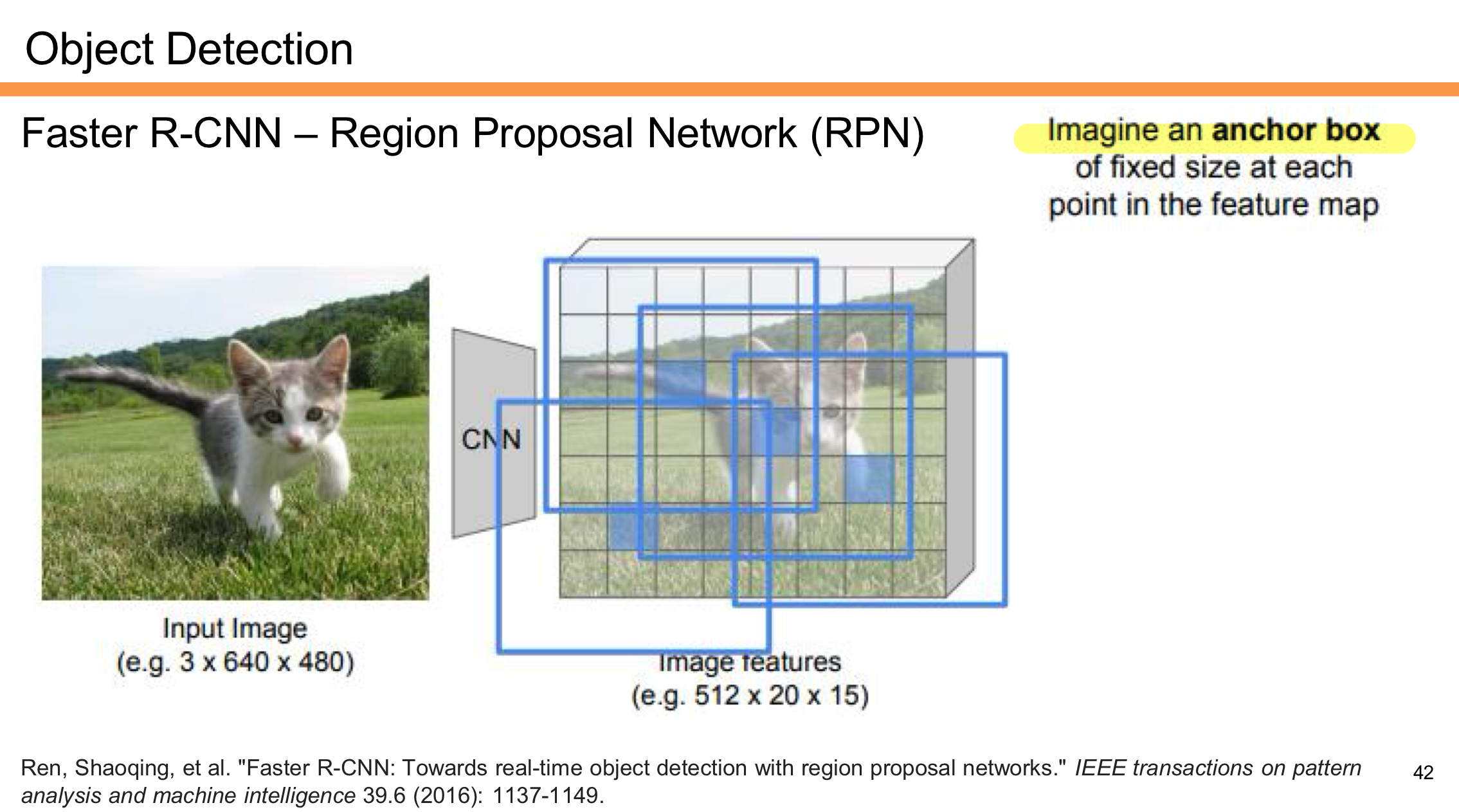
- Anchor Box의 평가
- Anchor가 Ground Truth 바운딩 박스와 충분히 겹치면 Positive(양성)로 간주한다.
- Anchor가 어떤 Ground Truth와도 겹치지 않으면 Negative(음성)로 간주한다.
Positive로 분류된 Anchor의 위치를 Bounding Box Regression을 통해 보정한다.
3. Stage 2: Fast R-CNN
- RPN이 생성한 후보 영역을 RoI Pooling을 통해 고정된 크기로 변환하고,
- Fast R-CNN 구조를 사용하여 객체의 클래스와 Bounding Box를 최종 예측한다.
RPN (Regoin Proposal)
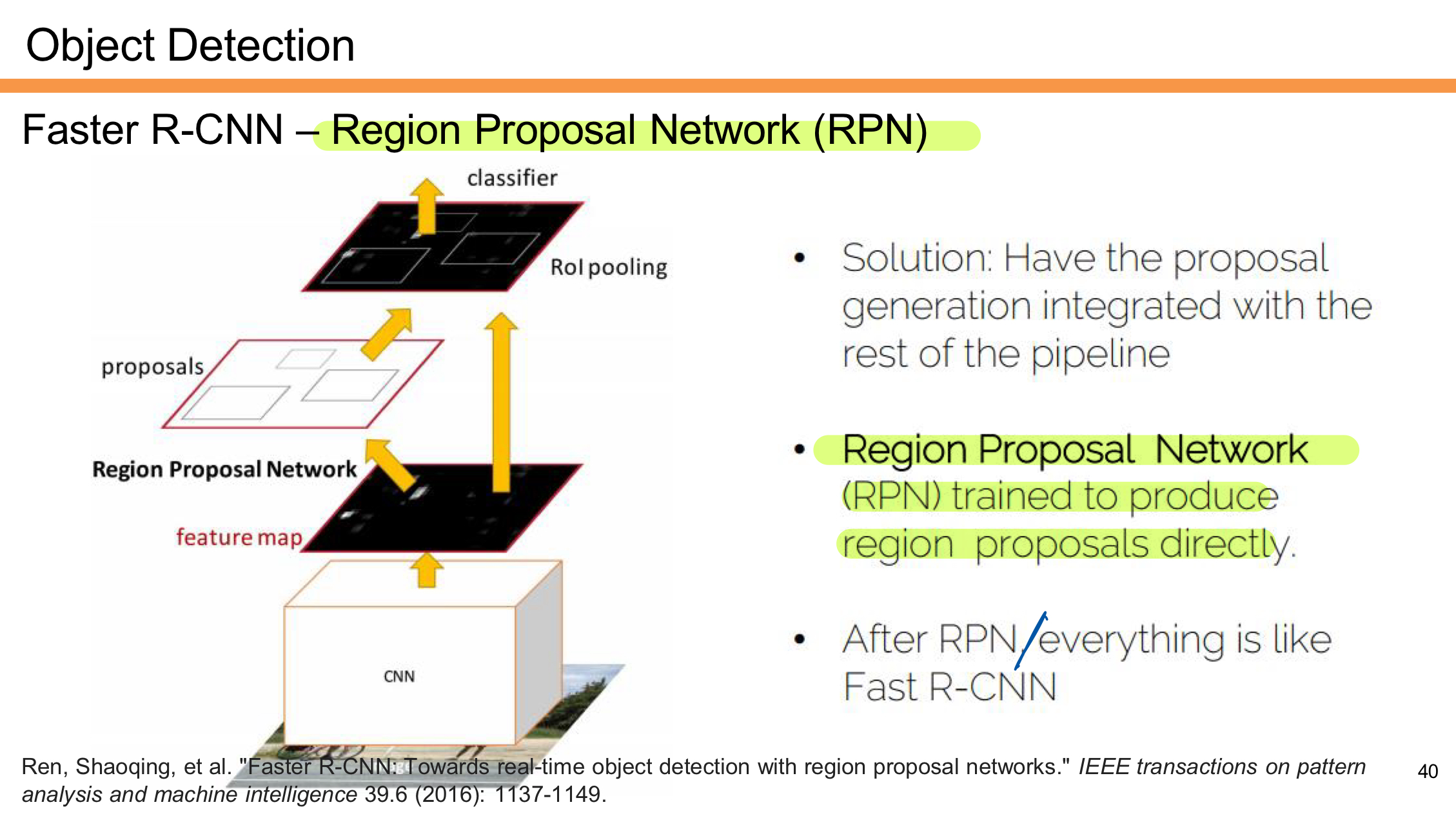
Faster R-CNN은 기존 Fast R-CNN에서 사용되던 외부 Region Proposal 방법(예: Selective Search)을 대체하기 위해 RPN을 도입했다.
- CNN을 통해 Feature Map을 생성한다.
- RPN은 Feature Map 위에서 작동하며, 각 위치에서 Region Proposal을 직접 예측한다.
- 생성된 Region Proposal은 RoI Pooling을 거쳐 고정된 크기로 변환된다.
- 이후 단계는 Fast R-CNN과 동일하게 진행된다.
- 객체의 클래스를 예측하고, 바운딩 박스를 보정한다.
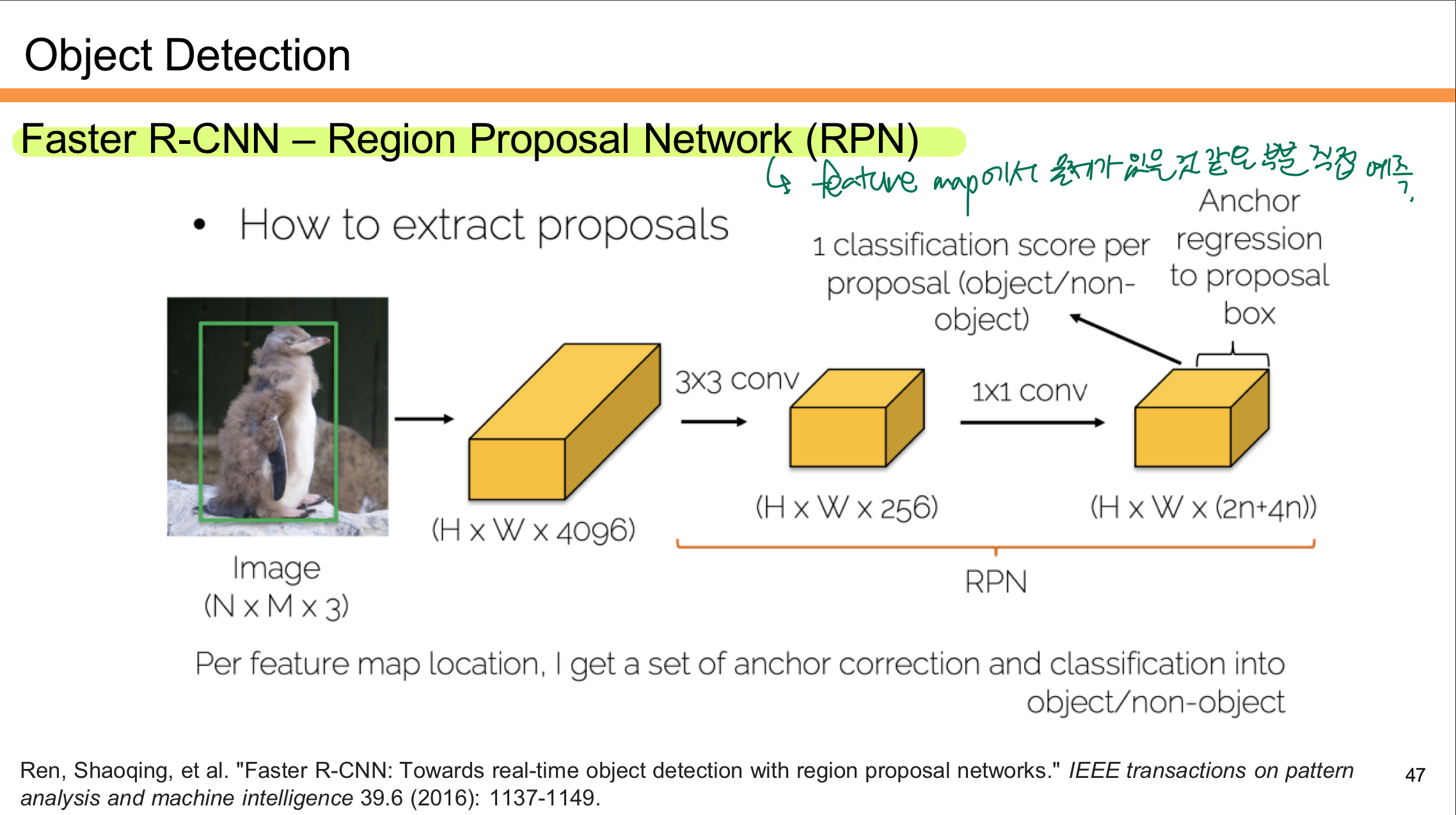
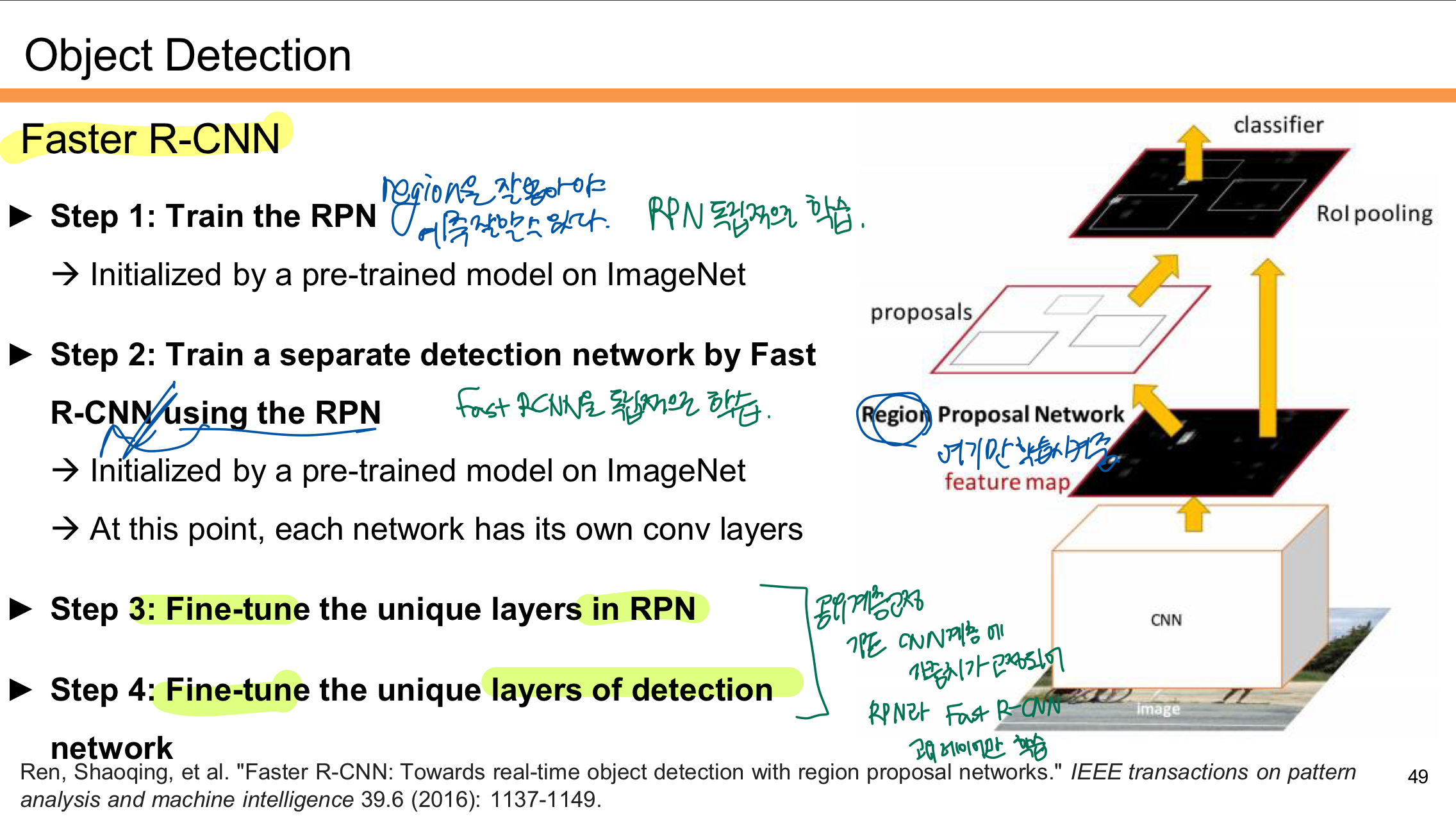
Faster R-CNN 학습순서
Step 1: RPN 학습
- RPN을 먼저 독립적으로 학습시킨다.
- RPN은 입력 이미지의 Feature Map에서 Region Proposal(후보 영역)을 생성하는 네트워크다.
- 초기에는 ImageNet으로 사전 학습된 모델을 사용해 시작한다.
Step 2: Fast R-CNN 학습
- RPN이 생성한 Region Proposal을 기반으로 Fast R-CNN을 학습시킨다.
- 이 단계에서도 ImageNet으로 학습된 CNN을 초기화 모델로 사용한다.
- RPN과 Fast R-CNN은 이 시점에서 각각 다른 합성곱 층(Conv Layers)을 가진다.
Step 3: RPN 미세 조정 (Fine-tuning)
- RPN의 고유한 계층만 미세 조정(Fine-tuning)한다.
- 이를 통해 Region Proposal이 더 정확하게 생성되도록 학습한다.
Step 4: Fast R-CNN 미세 조정
- 마지막으로 Fast R-CNN의 고유한 계층을 미세 조정한다.
- RPN과 Fast R-CNN이 공통된 CNN Feature Map을 사용하도록 조정되며 최적화된다.
Faster R-CNN은 먼저 RPN으로 Region Proposal을 학습시키고, 그 결과를 바탕으로 Fast R-CNN을 학습한다. 이후 두 네트워크를 Fine-tuning하여 최적화된 객체 탐지 모델을 만든다. 이를 통해 속도와 정확도를 동시에 개선한다.
'AI' 카테고리의 다른 글
Object Detection
Object Detection에는 여러가지 기법이 있다.
- Classification:
이미지를 보고 무엇이 있는지를 예측함. 예를 들어 "고양이"라는 클래스만 반환함. 위치 정보는 제공하지 않음. - Semantic Segmentation:
이미지를 픽셀 단위로 분류하여 각 픽셀이 어떤 클래스에 속하는지를 나타냄. 객체의 개수는 구분하지 않고 모든 픽셀을 분할함. - Object Detection:
이미지에서 객체의 종류와 위치를 찾아냄. 바운딩 박스(박스로 감싸는 형태)를 통해 객체를 구분함. - Instance Segmentation:
객체의 종류와 위치를 찾는 것에 더해, 각 객체를 픽셀 단위로 세밀하게 분할함. 같은 클래스라도 서로 다른 객체로 인식함.
여기서 우리는 Object Detection의 기법을 살펴 볼 것이다. 박스로 객체를 구분하는 것이다. 자세한 기법을 살펴보기전에 우선 알아보아야 할 개념인 IoU에 대해 살펴보자.
IoU는 객체 탐지에서 예측한 박스(Our Prediction)와 실제 정답 박스(Ground Truth)가 얼마나 겹치는지를 평가하는 지표이다. 공식은 겹친 영역(Area of Intersection)을 전체 영역(Area of Union)으로 나눈 값으로 표현한다.
- 값이 1에 가까울수록 예측 박스와 정답 박스가 잘 일치한다는 의미임.
- 0에 가까울수록 예측이 부정확하다는 의미임.
위의 사진은 Object Detectio에서 단일 객체를 탐지하는 초기 방법을 설명한다.
- What
객체가 무엇인지 예측한다.- Softmax Loss를 통해 객체의 클래스 점수(ex: 고양이 0.9, 강아지 0.05)를 계산함.
- 클래스 분류는 ImageNet 데이터로 사전 학습된 네트워크를 사용하여 진행함.
- Where
객체의 위치를 찾는다.- 바운딩 박스 좌표 (x, y, w, h)를 회귀 문제로 다룸.
- L2 Loss를 사용해 예측된 박스와 실제 박스(정답)의 차이를 최소화함.
- Multitask Loss:
클래스 분류와 위치 예측의 손실을 함께 최적화함.- 최종 Loss는 두 손실의 가중합으로 계산됨. (L = Lcls + λLreg)
문제는 이미지에 여러 객체가 존재할 수 있다는 것이다. 예를 들어 콘서트장에 사람을 일일히 바운딩 박스를 친다고 하면.. 시간이 엄청 오래 걸릴 것이다. 이를 해결하기 위해 이후 고도화된 Object Detection 모델들이 등장하게 된다.
Proposal-based Models는 Two-stage 모델로, 먼저 후보 영역(Region Proposal)을 생성한 후 객체를 분류하고 위치를 예측한다. 대표적으로 R-CNN(2014), Fast R-CNN(2015), Faster R-CNN(2015) 등이 있다. 이 모델들은 정확도가 높지만 처리 속도가 느리다는 단점이 있다. 그래서 RP를 생략하는 모델인 YOLO가 등장하게 된다.
Proposal-free Models는 Single-stage 모델로, 후보 영역 생성 과정을 생략하고 객체 위치를 직접 예측한다. 대표적으로 YOLO(2016), SSD(2016)가 있다. 이 모델들은 속도가 빠르고 실시간 탐지가 가능하지만 상대적으로 정확도가 낮을 수 있다.
R-CNN
R-CNN 동작 과정
- Region Proposal 생성
입력 이미지를 바탕으로 Selective Search와 같은 방법을 사용해 Region of Interest (RoI)를 생성한다.- 약 2,000개의 후보 영역이 생성된다.
- Region Warping
각 후보 영역을 고정된 크기(224x224)로 변환하여 CNN이 처리할 수 있도록 한다. - Feature Extraction
변환된 각각의 영역을 Convolutional Neural Network(CNN)에 통과시켜 특징(feature)을 추출한다.- 이 단계에서 동일한 크기의 입력에서 각 후보 영역에 대한 특징 벡터가 생성된다.
- Classification and Bounding Box Regression
- Class 예측: 각 RoI의 특징을 Fully Connected Layer를 통해 분류하고, 객체의 클래스(예: 고양이, 개)를 예측한다.
- Bounding Box Regression: 후보 영역의 위치를 보정하기 위해 4개의 값을 예측한다. 이 값들은 바운딩 박스의 변환 정보(tx, ty, th, tw)를 나타낸다.
- 결과 출력
각 후보 영역에 대해 클래스와 보정된 바운딩 박스를 출력한다.
이렇게 R-CNN 방법을 이용했을 때 output box들이 overlapping되는 문제가 발생한다. 같은 객체에 박스가 여러개 쳐지는 것이다. 이런 문제를 해결하기 위해 NMS 개념이 등장한다.
NMS (Non-Max Suppression)
R-CNN은 같은 객체에 대해 여러 개의 겹치는 바운딩 박스를 출력하는 문제가 있어 이를 해결하기 위해 NMS를 적용한다.
- 확률(Confidence Score)이 가장 높은 바운딩 박스를 먼저 선택한다.
- 선택된 박스와 겹치는 정도(Intersection over Union, IoU)가 특정 임계값(예: 0.7)을 넘는 다른 낮은 점수의 박스들은 제거한다.
- 남아 있는 바운딩 박스가 있으면 1단계를 반복한다.
위의 그림에서는 두마리의 "dog"에 대한 바운딩 박스가 보인다.
- 확률이 가장 높은 박스(각 강아지 개체마다)는 P(dog) = 0.9, 0.75이며, 이 박스가 우선 선택된다.
- 이후 다른 박스들(P(dog) = 0.8, 0.7)은 제거된다.
결과적으로 NMS는 겹치는 바운딩 박스 중 가장 신뢰도 높은 박스만 남기고 나머지를 제거해 최종 탐지 결과를 정리한다.
Fast R-CNN
등장 배경
R-CNN은 객체 탐지 과정에서 약 2,000개의 후보 영역(Region Proposal)을 생성하고, 각 영역을 개별적으로 CNN에 통과시켜 특징을 추출한다. 이 과정에서 CNN을 반복적으로 실행해야 하기 때문에 연산량이 매우 많고 시간이 오래 걸렸다.
Fast R-CNN은 이 문제를 해결하기 위해 이미지 전체에서 한 번만 CNN에 통과시킨 후, 생성된 특징 맵에서 후보 영역(Region Proposal)의 특징을 추출하는 방법을 도입했다. 이를 통해 연산량을 획기적으로 줄였다.
핵심 개선점
- CNN 연산을 한 번만 수행하여 속도를 크게 향상시켰다.
- 후보 영역의 특징을 RoI Pooling으로 효율적으로 추출한다.
1. R-CNN 동작 과정
- 입력 이미지를 받아 Selective Search와 같은 방법으로 약 2,000개의 후보 영역(Region Proposals)을 생성한다.
- 각 후보 영역을 고정된 크기(224x224)로 변환한 후 CNN에 개별적으로 통과시켜 특징을 추출한다.
- 즉, 2,000번의 CNN Forward Pass가 필요하므로 매우 비효율적이다.
- 추출된 특징은 SVM으로 분류되고, Bounding Box Regression을 통해 위치를 보정한다.
2. Fast R-CNN 동작 과정
- 입력 이미지 전체를 한 번만 CNN에 통과시켜 Feature Map을 생성한다.
- 이미지 전체에서 공통된 특징 맵을 추출하기 때문에 CNN 연산이 한 번만 수행된다.
- Region Proposal은 여전히 Selective Search를 통해 생성되지만,
- 이 후보 영역들은 Feature Map에서 해당 영역을 Crop(잘라내고) Resize한다.
- 이를 통해 각 Region Proposal에 대한 특징을 Feature Map에서 효율적으로 추출한다.
- 추출된 특징을 RoI Pooling을 통해 고정된 크기로 변환한다.
- 각 Region의 특징은 Fully Connected Layer를 통과하여 객체의 클래스를 예측하고, 동시에 Bounding Box Regression을 통해 바운딩 박스의 위치를 보정한다.
R-CNN vs Fast R-CNN 비교
| 비교 항목 | R-CNN | Fast R-CNN |
| CNN 연산 횟수 | 후보 영역(약 2,000개)마다 CNN을 수행 (비효율적) | 이미지 전체를 CNN에 한 번만 통과 (효율적) |
| Feature Extraction | 개별 후보 영역에서 특징 추출 | 전체 Feature Map에서 후보 영역의 특징 추출 |
| Region Proposal | Selective Search 사용 | Selective Search 사용 |
| 속도 | 느림 (2,000번 Forward Pass) | 빠름 (1번의 Forward Pass) |
| RoI Pooling | 없음 | 후보 영역을 Feature Map에서 고정된 크기로 변환 |
- Region Proposal: 입력 이미지에서 생성된 후보 영역(Region Proposal)을 CNN을 통해 Feature Map으로 매핑한다.
- Grid 분할: 해당 후보 영역을 2x2 또는 더 세밀한 격자(Grid)로 나눈다.
- Max-Pooling 적용: 각 격자(Subregion) 내에서 Max-Pooling을 수행해 가장 큰 값을 선택한다.
- 고정된 크기의 출력: 다양한 크기의 후보 영역도 RoI Pooling을 통해 항상 고정된 크기의 특징 맵(예: 7x7, 2x2 등)으로 변환된다.
RoI Pooling은 입력 후보 영역의 크기가 다르더라도 동일한 크기의 Region Features를 생성하며, 이를 통해 Fully Connected Layer에 전달할 수 있게 된다.
Faster R-CNN
Faster R-CNN은 기존 Fast R-CNN의 Region Proposal 단계를 개선하기 위해 Region Proposal Network (RPN)을 도입한 모델이다.
1. Region Proposal Network (RPN)의 도입
- 더 이상 Selective Search와 같은 외부 Region Proposal 기법이 필요하지 않다.
- 대신 RPN이 CNN Feature Map을 기반으로 후보 영역(Region Proposal)을 직접 생성한다.
2. Stage 1: RPN 훈련
- Anchor Boxes를 사용하여 후보 영역을 설정한다.
- 각 위치에서 3개의 비율(1:1, 1:2, 2:1)과 3개의 크기를 조합해 총 9개의 Anchor를 사용한다.
- Anchor Box의 평가
- Anchor가 Ground Truth 바운딩 박스와 충분히 겹치면 Positive(양성)로 간주한다.
- Anchor가 어떤 Ground Truth와도 겹치지 않으면 Negative(음성)로 간주한다.
Positive로 분류된 Anchor의 위치를 Bounding Box Regression을 통해 보정한다.
3. Stage 2: Fast R-CNN
- RPN이 생성한 후보 영역을 RoI Pooling을 통해 고정된 크기로 변환하고,
- Fast R-CNN 구조를 사용하여 객체의 클래스와 Bounding Box를 최종 예측한다.
RPN (Regoin Proposal)
Faster R-CNN은 기존 Fast R-CNN에서 사용되던 외부 Region Proposal 방법(예: Selective Search)을 대체하기 위해 RPN을 도입했다.
- CNN을 통해 Feature Map을 생성한다.
- RPN은 Feature Map 위에서 작동하며, 각 위치에서 Region Proposal을 직접 예측한다.
- 생성된 Region Proposal은 RoI Pooling을 거쳐 고정된 크기로 변환된다.
- 이후 단계는 Fast R-CNN과 동일하게 진행된다.
- 객체의 클래스를 예측하고, 바운딩 박스를 보정한다.
Faster R-CNN 학습순서
Step 1: RPN 학습
- RPN을 먼저 독립적으로 학습시킨다.
- RPN은 입력 이미지의 Feature Map에서 Region Proposal(후보 영역)을 생성하는 네트워크다.
- 초기에는 ImageNet으로 사전 학습된 모델을 사용해 시작한다.
Step 2: Fast R-CNN 학습
- RPN이 생성한 Region Proposal을 기반으로 Fast R-CNN을 학습시킨다.
- 이 단계에서도 ImageNet으로 학습된 CNN을 초기화 모델로 사용한다.
- RPN과 Fast R-CNN은 이 시점에서 각각 다른 합성곱 층(Conv Layers)을 가진다.
Step 3: RPN 미세 조정 (Fine-tuning)
- RPN의 고유한 계층만 미세 조정(Fine-tuning)한다.
- 이를 통해 Region Proposal이 더 정확하게 생성되도록 학습한다.
Step 4: Fast R-CNN 미세 조정
- 마지막으로 Fast R-CNN의 고유한 계층을 미세 조정한다.
- RPN과 Fast R-CNN이 공통된 CNN Feature Map을 사용하도록 조정되며 최적화된다.
Faster R-CNN은 먼저 RPN으로 Region Proposal을 학습시키고, 그 결과를 바탕으로 Fast R-CNN을 학습한다. 이후 두 네트워크를 Fine-tuning하여 최적화된 객체 탐지 모델을 만든다. 이를 통해 속도와 정확도를 동시에 개선한다.