2.3 멀티모달 기초 모델(Multimodal Foundation Models)
멀티모달리티(Multimodality)는 현재 기초 모델(FM, Foundation Model) 연구에서 중요한 연구 방향 중 하나이다. 대형 기초 모델은 다양한 모달 간 이해, 변환(translation), 생성(generation) 능력이 강력한 특징을 보인다.
일반적으로 멀티모달 기초 모델 연구는 두 가지 방향으로 나뉜다.
- 다양한 모달 데이터를 동일한 잠재 공간(latent space)으로 인코딩하는 방법
- 주로 트랜스포머(Transformer) 기반 인코더를 사용한다.
- 다양한 모달 데이터를 생성하는 방법
- 주로 트랜스포머 디코더(Transformer Decoder)를 활용한다.
- 특히, 텍스트를 기반으로 이미지를 생성(text-to-image generation)하는 연구가 활발히 진행되고 있으며, 최근 몇 년 동안 상당한 발전을 이루었다.
이 두 연구 방향은 서로 점점 융합(convergence)되고 있다. 예를 들어,
- 하나의 모달에서 다른 모달을 생성하는 것뿐만 아니라,
- 멀티모달 입력을 받아 또 다른 멀티모달 데이터를 생성하는 모델(multimodal-to-multimodal generation)도 연구되고 있으며,
- 나아가 어떤 형태의 입력이든 받아서 어떤 형태의 출력이든 생성할 수 있는(Any-to-Any generation) 기술 개발도 이루어지고 있다.
2.3.1 주요 아키텍처(Key Architectures)
멀티모달 데이터를 효과적으로 처리하고 정렬(alignment)하기 위해, 현재의 모델 아키텍처는 여러 개의 인코더(encoders)로 구성되는 경우가 많다.
- 멀티모달 데이터 정렬(alignment) : 서로 다른 모달리티(텍스트, 이미지, 오디오 등)의 데이터를 공통된 표현 공간(shared representation space)에서 연결하는 과정
- 각 모달리티(텍스트, 이미지, 오디오 등)마다 별도의 트랜스포머 인코더가 존재하며,
- 일반적으로 처음부터 학습(training from scratch)된다.
- 이 과정에서 정렬된(align된) 데이터(예: 텍스트와 이미지 쌍)를 활용하여, 서로 다른 모달리티 간 관계를 학습한다.
멀티모달 입력을 받으면,
- 각각의 인코더는 데이터를 정규화된(fixed-dimensional) 임베딩으로 변환한다.
- 이 임베딩을 고차원 공간(high-dimensional space)에 매핑하고,
- 손실 함수(loss function)를 설계하여 서로 다른 모달리티 간 거리를 최소화하도록 학습한다.
이러한 접근 방식은 다양한 모달 간 정렬(alignment)을 가능하게 하며, 모델이 일관된 표현(consistent representation)을 학습할 수 있도록 돕는다.
멀티모달 데이터가 정렬된 후, 기존 연구는 다음과 같은 방법을 사용한다.
- LLM을 활용하여 텍스트 생성
- 기존의 대형 언어 모델(LLM, Large Language Model)은 순수한 텍스트 데이터(corpus)로 사전 학습(pretraining)되었으며,
- 이를 멀티모달 입력과 정렬하여 텍스트를 생성하는 방식이다.
- LLM은 디코더 전용(Decoder-only) 아키텍처를 채택하며,
- 대규모 사전 학습 덕분에 풍부한 의미적 지식(semantic knowledge)을 보유하고 있다.
- 따라서, 텍스트 모달리티로 표현된 데이터를 효과적으로 이해하고, 시퀀스 단위(autoregressive 방식)로 텍스트를 생성할 수 있다.
- 확산 모델(Diffusion Model)을 활용하여 고품질 이미지 생성
- Diffusion Model은 입력 이미지의 노이즈를 제거하여 고품질 이미지를 생성하는 방식이다.
- 학습 과정에서는 이미지에 점진적으로 노이즈를 추가하며,
- 추론 과정에서는 이 노이즈를 반대로 제거하는 방식으로 이미지를 복원한다.
- 이 디노이징(denoising) 과정이 이미지의 선명도를 높이는 데 필수적이며, 고해상도(high resolution)와 세밀한 디테일을 가진 이미지를 생성할 수 있도록 한다.
- 특히, Stable Diffusion 모델의 발전으로 인해, 텍스트 및 이미지 설명을 기반으로 특정 스타일이나 의미를 반영한 이미지 생성 기술이 크게 향상되었다.
이러한 확산 모델은 멀티모달 임베딩 입력(multimodal embedding input)을 활용하며, 주로 두 가지 핵심 컴포넌트로 구성된다.
- 이미지 인코더/디코더(Image Encoder/Decoder)
- 입력 이미지를 벡터로 변환하거나, 반대로 벡터를 이미지로 변환하는 역할을 수행한다.
- 디노이징 네트워크(Denoising Network)
- 이미지 내 불필요한 노이즈를 제거하여 더 선명한 결과물을 얻도록 한다.
1. 이미지 인코더/디코더
Diffusion 모델은 텍스트-이미지 변환(text-to-image generation)을 위한 SOTA 접근 방식이다.
- 인코더(Encoder)는 입력 이미지를 받아 저차원의 잠재 표현(latent representation)으로 압축한다.
- 이 압축 과정은 연산 부담을 줄이고 모델의 효율성을 높이는 데 중요하다.
- 디코더(Decoder)는 반대로, 잠재 표현을 받아 다시 고해상도 이미지로 복원한다.
- 이 과정은 모델이 세밀한 시각적 콘텐츠를 생성할 수 있도록 하는 핵심 요소이다.
변분 오토인코더(VAE, Variational Autoencoder)는 이미지의 잠재 공간(latent space)을 학습하는 생성 모델이다.
- VAE는 인코더와 디코더로 구성된다.
- 인코더는 이미지를 받아 잠재 공간으로 매핑하는 역할을 한다.
- 디코더는 반대로 잠재 공간에서 다시 이미지 공간으로 변환하는 역할을 한다.
- 인코더와 디코더 네트워크는 일반적으로 합성곱 신경망(CNN, Convolutional Neural Networks) 레이어로 구축된다.
- VAE는 다음 두 가지 손실을 최소화하도록 학습된다.
- 재구성 손실(Reconstruction Loss): 디코더가 생성한 이미지가 원본 이미지와 유사하도록 함.
- KL 발산 손실(KL Divergence Loss): 학습된 잠재 공간이 표준 정규 분포(standard normal distribution)에 가깝도록 유도함.
VAE는 Diffusion 모델에서 이미지의 잠재 공간을 학습하는 데 사용된다.
- Diffusion 작업에서 종종 사용되는 또 다른 VAE 변형 모델은 VQ-VAE(Vector Quantized VAE)이다.
- VQ-VAE는 벡터 양자화(vector quantization) 레이어를 통해 이미지의 잠재 공간을 학습한다.
- 벡터 양자화 레이어는 이미지의 각 픽셀을 가장 가까운 코드북 벡터(codebook vector)로 양자화(quantization)한다.
- 이를 통해 VQ-VAE 모델은 보다 효율적으로 이미지를 인코딩 및 디코딩할 수 있다.
2. 디노이징 네트워크(Denoising Network)
디노이징 네트워크는 인코딩된 이미지에서 점진적으로 노이즈를 제거하는 역할을 한다.
- 모델은 노이즈 분포를 예측하고 샘플링 알고리즘을 활용하여 이를 제거한다.
- 대표적인 샘플링 알고리즘에는 DDPM(Denoising Diffusion Probabilistic Model)과 DDIM(Denoising Diffusion Implicit Model) 있다.
학습 과정(training phase)
- 모델은 이미지에 점진적으로 노이즈를 추가하여 점차적으로 완전한 무작위 상태(random state)로 만든다.
- 이 과정을 통해 모델이 노이즈를 학습하도록 훈련된다.
추론 과정(inference phase)
- 학습된 디노이징 네트워크는 추론 단계에서 역방향으로 이 노이즈를 제거한다.
- 이 점진적인 디노이징 과정이 이미지의 선명도와 품질을 향상시키는 데 핵심적인 역할을 한다.
U-Net은 Diffusion 모델에서 노이즈 예측 네트워크로 자주 사용되는 합성곱 신경망 모델이다.
- U-Net은 수축 경로(contracting path)와 확장 경로(expansive path)로 구성된다.
- 수축 경로: 이미지를 고차원 공간(high-dimensional space)으로 매핑하여 문맥 정보를 추출함.
- 확장 경로: 업샘플링(upsampling)을 통해 정확한 위치 정보를 복원함.
- Skip connection을 통해 수축 경로에서 얻은 정보를 확장 경로에 연결하여 정보 손실을 방지한다.
- U-Net 모델은 이미지 분할(image segmentation) 작업에서도 널리 사용되며, Diffusion 모델에서도 이미지 내 노이즈를 예측하는 역할을 수행한다.
퓨전 디코더(Fusion Decoder, FD)
퓨전 디코더(FD) 모듈은 이미지 자체뿐만 아니라 관련된 이미지 프롬프트(prompt)까지 활용하여 이미지의 이해를 향상시키는 역할을 한다.
- 주어진 작업(task requirement)에 따라 출력을 생성하는 기능을 한다.
- 일반적으로 퓨전 디코더를 설계하고, 이미지 및 텍스트 데이터셋을 함께 학습(pre-training)하는 방식을 따른다.
- 이를 통해 이미지와 텍스트 표현을 동시에 처리할 수 있는 능력을 갖추게 된다.
- 이 모듈은 이미지 및 텍스트 데이터를 함께 처리할 수 있도록 설계된 퓨전 디코더를 포함하며,
- 이미지와 텍스트 데이터셋을 기반으로 사전 학습(pretraining)된다.
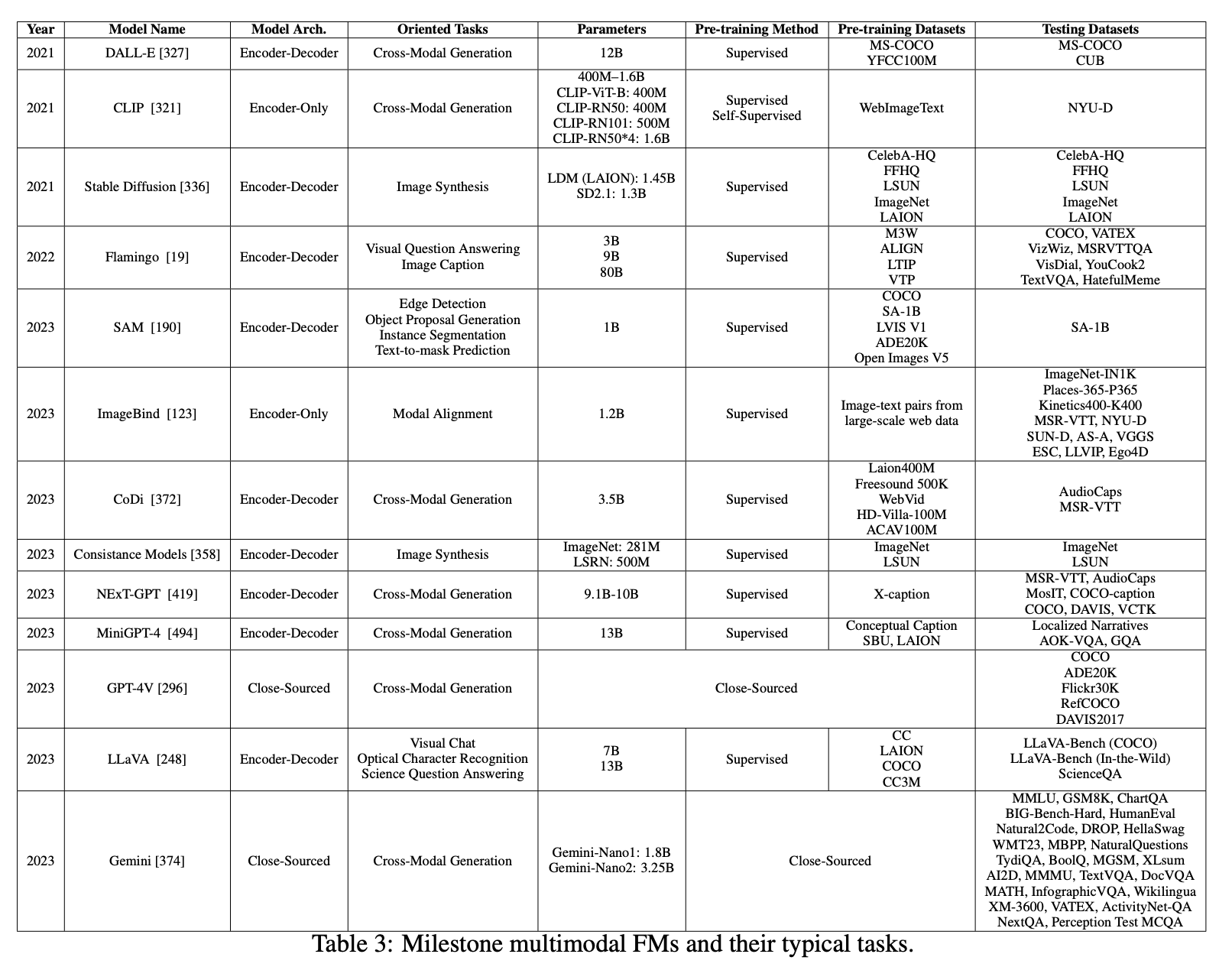
2.3.2 대표적인 모델과 다운스트림 작업(Representative Models and Downstream Tasks)
(1) 다중 인코더 기초 모델(Multi-Encoder FMs)
CLIP [321], ALBEF [216], ALIGN은 가장 초기의 연구들로, 이미지와 텍스트 간 연결을 구축하여 텍스트를 통해 더 풍부한 이미지 표현을 학습하는 크로스모달 정렬(cross-modal alignment) 기법을 제안했다.
- 이러한 모델들은 멀티모달 가능성을 보여주었지만, 이미지 및 텍스트 인코더의 성능과 이미지-텍스트 페어 데이터의 품질 및 양에 의해 성능이 제한되었다.
- 이후 ImageBind [123], LanguageBind [492]와 같은 연구들은 중간 모달(intermediate modalities)을 활용한 정렬 방식을 확장했다.
- 이러한 모델들은 다양한 입력 소스를 중간 모달의 특징 공간(feature space)에 매핑함으로써, 공동 벡터 공간(joint vector space) 내에서 크로스모달 변환을 용이하게 한다.
- 하지만, 멀티모달 표현을 중간 모달과 정렬하는 과정에서 인코더의 한계가 발생하며, 이는 모델 성능에 영향을 미친다.
(2) 인코더-디코더 기초 모델(Encoder-Decoder FMs)
인코더-디코더 방식의 모델은 임베딩 모듈(embedding module)을 활용하여 모달 변환(modality conversion)을 수행하며, 변환된 모달이 생성기(generator)와 호환되도록 한다.
대형 인코더 기초 모델(Encoder-Large FMs)
- PandaGPT [361]:
- 다중 단일 모달(single-modal) 인코더를 사용하여 입력을 중간 모달로 정렬함.
- 이후, 중간 모달을 대형 기초 모델(Large FM)에 입력한 후, 최종 모달 변환을 수행하는 디코더를 사용하여 출력을 생성함.
- BLIP-2 [215], MiniGPT-4 [494]:
- 이미지 모달 인코더(image modal encoder)를 설계하여,
- Q-Former를 활용해 이미지 모달과 텍스트 모달을 결합(fuse)한 후, 멀티모달 대형 FM으로 입력하여 크로스모달 생성 수행.
- mPLUG [453], LLaVA [248]:
- 모달 변환(modality transformation)의 성능 향상을 통해 생성 결과의 가용성 및 신뢰성을 개선하는 데 초점을 맞춤.
- MobileVLM V2 [71]:
- 자원 제한이 있는 디바이스(resource-constrained devices)를 위한 고효율 비전-언어 모델(vision-language model).
- CLIP 기반 인코더와 MobileLLaMA 기반 디코더를 사용하여 빠른 추론 속도를 유지하면서도 우수한 성능을 달성함.
- Flamingo [19], LLaMA-Adapter [478]:
- 낮은 비용으로(multimodal large FM의 튜닝 비용을 줄이는 방법을 탐색하여 고품질 멀티모달 출력을 생성하는 연구.
- PaLM-E [93], HuggingGPT [349]:
- 대형 기초 모델을 중심으로 Embodied Intelligence(체화된 지능, 즉 로봇 등과의 통합 학습)를 활용하는 모델.
- 멀티모달 입력에 체화된 데이터를 통합하여,
- 모델이 복잡한 작업을 수행할 수 있도록 설계된 Task Decomposition Agent(작업 분해 에이전트)를 활용함.
인코더-디퓨전 기초 모델(Encoder-Diffusion FMs)
- Stable Diffusion [336]
- 점진적인 노이즈 제거 과정을 통해 고품질 이미지를 생성하는 모델.
- 다양한 다운스트림 작업에서 활용됨.
- 텍스트 기반 이미지 생성(Text-to-Image Generation)
- 이미지 복원 및 보완(Image Inpainting)
- 이미지 수정(Image Editing)
- 이미지 초해상화(Image Super-Resolution)
- 이러한 범용성 덕분에 이미지 생성 및 처리 분야에서 중요한 도구로 활용됨.
- Consistency Models [358]
- 디퓨전 모델의 효율성을 향상하여 고품질 이미지, 오디오, 비디오를 빠르게 생성할 수 있도록 설계됨.
- 단일 스텝 생성(single-step generation)을 가능하게 하여, 기존 디퓨전 모델이 갖고 있던 느린 샘플링 속도 문제를 해결함.
- 별도의 학습 없이 제로샷(Zero-Shot) 이미지 수정 작업 수행 가능
- 예: 이미지 복원(Inpainting), 색상화(Colorization), 초해상화(Super-Resolution)
- DALL-E [327]
- 텍스트 설명을 바탕으로 다양하고 복잡한 이미지 생성 가능.
- 자연어 이해(Natural Language Understanding)와 컴퓨터 비전(Computer Vision) 기술을 결합하여
- 간단한 설명부터 복잡한 시나리오까지 폭넓게 이미지 생성 가능.
- “Any-to-Any” 생성 모델
- 다양한 유형의 입력을 받아 여러 형태의 출력을 생성할 수 있도록 설계된 모델.
- CoDi [372]
- 다양한 입력 조합을 받아,
- 언어, 이미지, 비디오, 오디오 등 다양한 모달의 출력 생성 가능.
- 동시에 여러 모달을 생성할 수 있으며, 특정 입력 유형에 제한되지 않음.
- 기존 학습 데이터에 존재하지 않는 조합도 생성 가능하도록 설계됨.
- NExT-GPT [419]
- 다양한 모달(텍스트, 이미지, 비디오, 오디오) 입력을 처리하고 출력할 수 있는 기능 보유.
- 대형 기초 모델과 멀티모달 어댑터(multimodal adaptor), 디퓨전 모델을 결합하여 제작됨.
- 최소한의 파라미터 변경으로 파인튜닝 가능하여 비용 효율적인 훈련과 모달 확장이 용이함.
- 모달 전환 지시(Modality-Switching Instruction Tuning) 및 특별히 구축된 데이터셋 활용하여 크로스모달 콘텐츠 생성 및 이해 능력 향상.
- M4 [462]
- 모바일 AI를 위한 확장 가능한 기초 모델.
- 다양한 AI 작업을 하나의 모델로 통합.
- 텍스트, 이미지, 오디오, 모션 데이터 등 여러 입력을 처리하고 이해 및 추론 수행.
- 멀티모달 임베딩과 트랜스포머 기반 백본을 활용하여 효율성과 확장성을 극대화함.
인코더-FD 기초 모델(Encoder-FD FMs)
- UNITER [64]
- 멀티모달 환경에서 이미지와 텍스트를 통합적으로 처리하기 위한 초기 연구 중 하나.
- 트랜스포머를 활용하여 이미지와 텍스트 특징을 결합하여 공통 표현(joint representation)을 학습함.
- FLAVA [354], CoCa [459], GLIP [219]
- 디코더를 활용하여 이미지와 텍스트 표현을 더욱 효과적으로 결합 및 정렬(fusion and alignment)하는 연구.
- 멀티모달 추론(reasoning) 능력을 향상시키는 데 초점을 맞춤.
- SAM [190], SAM 2 [331]
- 프롬프트 임베딩(prompt embedding)을 이미지에 적용하여 텍스트 기반 제로샷 자동 이미지/비디오 분할 수행 가능.
- 즉, 텍스트만으로 이미지를 분석하고 자동으로 객체를 분리할 수 있는 기능 제공.
'AI' 카테고리의 다른 글
| Residual Block 이해하기 (0) | 2025.02.21 |
|---|---|
| Batch, Step, Epoch 이해하기 (1) | 2025.02.20 |
| [Object Detection] R-CNN, Fast R-CNN, Faster R-CNN (2) | 2024.12.18 |
| [논문] DoRA: Weight-Decomposed Low-Rank Adaptation (1) | 2024.12.16 |
| [논문] Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented Generation (2) | 2024.11.25 |
2.3 멀티모달 기초 모델(Multimodal Foundation Models)
멀티모달리티(Multimodality)는 현재 기초 모델(FM, Foundation Model) 연구에서 중요한 연구 방향 중 하나이다. 대형 기초 모델은 다양한 모달 간 이해, 변환(translation), 생성(generation) 능력이 강력한 특징을 보인다.
일반적으로 멀티모달 기초 모델 연구는 두 가지 방향으로 나뉜다.
- 다양한 모달 데이터를 동일한 잠재 공간(latent space)으로 인코딩하는 방법
- 주로 트랜스포머(Transformer) 기반 인코더를 사용한다.
- 다양한 모달 데이터를 생성하는 방법
- 주로 트랜스포머 디코더(Transformer Decoder)를 활용한다.
- 특히, 텍스트를 기반으로 이미지를 생성(text-to-image generation)하는 연구가 활발히 진행되고 있으며, 최근 몇 년 동안 상당한 발전을 이루었다.
이 두 연구 방향은 서로 점점 융합(convergence)되고 있다. 예를 들어,
- 하나의 모달에서 다른 모달을 생성하는 것뿐만 아니라,
- 멀티모달 입력을 받아 또 다른 멀티모달 데이터를 생성하는 모델(multimodal-to-multimodal generation)도 연구되고 있으며,
- 나아가 어떤 형태의 입력이든 받아서 어떤 형태의 출력이든 생성할 수 있는(Any-to-Any generation) 기술 개발도 이루어지고 있다.
2.3.1 주요 아키텍처(Key Architectures)
멀티모달 데이터를 효과적으로 처리하고 정렬(alignment)하기 위해, 현재의 모델 아키텍처는 여러 개의 인코더(encoders)로 구성되는 경우가 많다.
- 멀티모달 데이터 정렬(alignment) : 서로 다른 모달리티(텍스트, 이미지, 오디오 등)의 데이터를 공통된 표현 공간(shared representation space)에서 연결하는 과정
- 각 모달리티(텍스트, 이미지, 오디오 등)마다 별도의 트랜스포머 인코더가 존재하며,
- 일반적으로 처음부터 학습(training from scratch)된다.
- 이 과정에서 정렬된(align된) 데이터(예: 텍스트와 이미지 쌍)를 활용하여, 서로 다른 모달리티 간 관계를 학습한다.
멀티모달 입력을 받으면,
- 각각의 인코더는 데이터를 정규화된(fixed-dimensional) 임베딩으로 변환한다.
- 이 임베딩을 고차원 공간(high-dimensional space)에 매핑하고,
- 손실 함수(loss function)를 설계하여 서로 다른 모달리티 간 거리를 최소화하도록 학습한다.
이러한 접근 방식은 다양한 모달 간 정렬(alignment)을 가능하게 하며, 모델이 일관된 표현(consistent representation)을 학습할 수 있도록 돕는다.
멀티모달 데이터가 정렬된 후, 기존 연구는 다음과 같은 방법을 사용한다.
- LLM을 활용하여 텍스트 생성
- 기존의 대형 언어 모델(LLM, Large Language Model)은 순수한 텍스트 데이터(corpus)로 사전 학습(pretraining)되었으며,
- 이를 멀티모달 입력과 정렬하여 텍스트를 생성하는 방식이다.
- LLM은 디코더 전용(Decoder-only) 아키텍처를 채택하며,
- 대규모 사전 학습 덕분에 풍부한 의미적 지식(semantic knowledge)을 보유하고 있다.
- 따라서, 텍스트 모달리티로 표현된 데이터를 효과적으로 이해하고, 시퀀스 단위(autoregressive 방식)로 텍스트를 생성할 수 있다.
- 확산 모델(Diffusion Model)을 활용하여 고품질 이미지 생성
- Diffusion Model은 입력 이미지의 노이즈를 제거하여 고품질 이미지를 생성하는 방식이다.
- 학습 과정에서는 이미지에 점진적으로 노이즈를 추가하며,
- 추론 과정에서는 이 노이즈를 반대로 제거하는 방식으로 이미지를 복원한다.
- 이 디노이징(denoising) 과정이 이미지의 선명도를 높이는 데 필수적이며, 고해상도(high resolution)와 세밀한 디테일을 가진 이미지를 생성할 수 있도록 한다.
- 특히, Stable Diffusion 모델의 발전으로 인해, 텍스트 및 이미지 설명을 기반으로 특정 스타일이나 의미를 반영한 이미지 생성 기술이 크게 향상되었다.
이러한 확산 모델은 멀티모달 임베딩 입력(multimodal embedding input)을 활용하며, 주로 두 가지 핵심 컴포넌트로 구성된다.
- 이미지 인코더/디코더(Image Encoder/Decoder)
- 입력 이미지를 벡터로 변환하거나, 반대로 벡터를 이미지로 변환하는 역할을 수행한다.
- 디노이징 네트워크(Denoising Network)
- 이미지 내 불필요한 노이즈를 제거하여 더 선명한 결과물을 얻도록 한다.
1. 이미지 인코더/디코더
Diffusion 모델은 텍스트-이미지 변환(text-to-image generation)을 위한 SOTA 접근 방식이다.
- 인코더(Encoder)는 입력 이미지를 받아 저차원의 잠재 표현(latent representation)으로 압축한다.
- 이 압축 과정은 연산 부담을 줄이고 모델의 효율성을 높이는 데 중요하다.
- 디코더(Decoder)는 반대로, 잠재 표현을 받아 다시 고해상도 이미지로 복원한다.
- 이 과정은 모델이 세밀한 시각적 콘텐츠를 생성할 수 있도록 하는 핵심 요소이다.
변분 오토인코더(VAE, Variational Autoencoder)는 이미지의 잠재 공간(latent space)을 학습하는 생성 모델이다.
- VAE는 인코더와 디코더로 구성된다.
- 인코더는 이미지를 받아 잠재 공간으로 매핑하는 역할을 한다.
- 디코더는 반대로 잠재 공간에서 다시 이미지 공간으로 변환하는 역할을 한다.
- 인코더와 디코더 네트워크는 일반적으로 합성곱 신경망(CNN, Convolutional Neural Networks) 레이어로 구축된다.
- VAE는 다음 두 가지 손실을 최소화하도록 학습된다.
- 재구성 손실(Reconstruction Loss): 디코더가 생성한 이미지가 원본 이미지와 유사하도록 함.
- KL 발산 손실(KL Divergence Loss): 학습된 잠재 공간이 표준 정규 분포(standard normal distribution)에 가깝도록 유도함.
VAE는 Diffusion 모델에서 이미지의 잠재 공간을 학습하는 데 사용된다.
- Diffusion 작업에서 종종 사용되는 또 다른 VAE 변형 모델은 VQ-VAE(Vector Quantized VAE)이다.
- VQ-VAE는 벡터 양자화(vector quantization) 레이어를 통해 이미지의 잠재 공간을 학습한다.
- 벡터 양자화 레이어는 이미지의 각 픽셀을 가장 가까운 코드북 벡터(codebook vector)로 양자화(quantization)한다.
- 이를 통해 VQ-VAE 모델은 보다 효율적으로 이미지를 인코딩 및 디코딩할 수 있다.
2. 디노이징 네트워크(Denoising Network)
디노이징 네트워크는 인코딩된 이미지에서 점진적으로 노이즈를 제거하는 역할을 한다.
- 모델은 노이즈 분포를 예측하고 샘플링 알고리즘을 활용하여 이를 제거한다.
- 대표적인 샘플링 알고리즘에는 DDPM(Denoising Diffusion Probabilistic Model)과 DDIM(Denoising Diffusion Implicit Model) 있다.
학습 과정(training phase)
- 모델은 이미지에 점진적으로 노이즈를 추가하여 점차적으로 완전한 무작위 상태(random state)로 만든다.
- 이 과정을 통해 모델이 노이즈를 학습하도록 훈련된다.
추론 과정(inference phase)
- 학습된 디노이징 네트워크는 추론 단계에서 역방향으로 이 노이즈를 제거한다.
- 이 점진적인 디노이징 과정이 이미지의 선명도와 품질을 향상시키는 데 핵심적인 역할을 한다.
U-Net은 Diffusion 모델에서 노이즈 예측 네트워크로 자주 사용되는 합성곱 신경망 모델이다.
- U-Net은 수축 경로(contracting path)와 확장 경로(expansive path)로 구성된다.
- 수축 경로: 이미지를 고차원 공간(high-dimensional space)으로 매핑하여 문맥 정보를 추출함.
- 확장 경로: 업샘플링(upsampling)을 통해 정확한 위치 정보를 복원함.
- Skip connection을 통해 수축 경로에서 얻은 정보를 확장 경로에 연결하여 정보 손실을 방지한다.
- U-Net 모델은 이미지 분할(image segmentation) 작업에서도 널리 사용되며, Diffusion 모델에서도 이미지 내 노이즈를 예측하는 역할을 수행한다.
퓨전 디코더(Fusion Decoder, FD)
퓨전 디코더(FD) 모듈은 이미지 자체뿐만 아니라 관련된 이미지 프롬프트(prompt)까지 활용하여 이미지의 이해를 향상시키는 역할을 한다.
- 주어진 작업(task requirement)에 따라 출력을 생성하는 기능을 한다.
- 일반적으로 퓨전 디코더를 설계하고, 이미지 및 텍스트 데이터셋을 함께 학습(pre-training)하는 방식을 따른다.
- 이를 통해 이미지와 텍스트 표현을 동시에 처리할 수 있는 능력을 갖추게 된다.
- 이 모듈은 이미지 및 텍스트 데이터를 함께 처리할 수 있도록 설계된 퓨전 디코더를 포함하며,
- 이미지와 텍스트 데이터셋을 기반으로 사전 학습(pretraining)된다.
2.3.2 대표적인 모델과 다운스트림 작업(Representative Models and Downstream Tasks)
(1) 다중 인코더 기초 모델(Multi-Encoder FMs)
CLIP [321], ALBEF [216], ALIGN은 가장 초기의 연구들로, 이미지와 텍스트 간 연결을 구축하여 텍스트를 통해 더 풍부한 이미지 표현을 학습하는 크로스모달 정렬(cross-modal alignment) 기법을 제안했다.
- 이러한 모델들은 멀티모달 가능성을 보여주었지만, 이미지 및 텍스트 인코더의 성능과 이미지-텍스트 페어 데이터의 품질 및 양에 의해 성능이 제한되었다.
- 이후 ImageBind [123], LanguageBind [492]와 같은 연구들은 중간 모달(intermediate modalities)을 활용한 정렬 방식을 확장했다.
- 이러한 모델들은 다양한 입력 소스를 중간 모달의 특징 공간(feature space)에 매핑함으로써, 공동 벡터 공간(joint vector space) 내에서 크로스모달 변환을 용이하게 한다.
- 하지만, 멀티모달 표현을 중간 모달과 정렬하는 과정에서 인코더의 한계가 발생하며, 이는 모델 성능에 영향을 미친다.
(2) 인코더-디코더 기초 모델(Encoder-Decoder FMs)
인코더-디코더 방식의 모델은 임베딩 모듈(embedding module)을 활용하여 모달 변환(modality conversion)을 수행하며, 변환된 모달이 생성기(generator)와 호환되도록 한다.
대형 인코더 기초 모델(Encoder-Large FMs)
- PandaGPT [361]:
- 다중 단일 모달(single-modal) 인코더를 사용하여 입력을 중간 모달로 정렬함.
- 이후, 중간 모달을 대형 기초 모델(Large FM)에 입력한 후, 최종 모달 변환을 수행하는 디코더를 사용하여 출력을 생성함.
- BLIP-2 [215], MiniGPT-4 [494]:
- 이미지 모달 인코더(image modal encoder)를 설계하여,
- Q-Former를 활용해 이미지 모달과 텍스트 모달을 결합(fuse)한 후, 멀티모달 대형 FM으로 입력하여 크로스모달 생성 수행.
- mPLUG [453], LLaVA [248]:
- 모달 변환(modality transformation)의 성능 향상을 통해 생성 결과의 가용성 및 신뢰성을 개선하는 데 초점을 맞춤.
- MobileVLM V2 [71]:
- 자원 제한이 있는 디바이스(resource-constrained devices)를 위한 고효율 비전-언어 모델(vision-language model).
- CLIP 기반 인코더와 MobileLLaMA 기반 디코더를 사용하여 빠른 추론 속도를 유지하면서도 우수한 성능을 달성함.
- Flamingo [19], LLaMA-Adapter [478]:
- 낮은 비용으로(multimodal large FM의 튜닝 비용을 줄이는 방법을 탐색하여 고품질 멀티모달 출력을 생성하는 연구.
- PaLM-E [93], HuggingGPT [349]:
- 대형 기초 모델을 중심으로 Embodied Intelligence(체화된 지능, 즉 로봇 등과의 통합 학습)를 활용하는 모델.
- 멀티모달 입력에 체화된 데이터를 통합하여,
- 모델이 복잡한 작업을 수행할 수 있도록 설계된 Task Decomposition Agent(작업 분해 에이전트)를 활용함.
인코더-디퓨전 기초 모델(Encoder-Diffusion FMs)
- Stable Diffusion [336]
- 점진적인 노이즈 제거 과정을 통해 고품질 이미지를 생성하는 모델.
- 다양한 다운스트림 작업에서 활용됨.
- 텍스트 기반 이미지 생성(Text-to-Image Generation)
- 이미지 복원 및 보완(Image Inpainting)
- 이미지 수정(Image Editing)
- 이미지 초해상화(Image Super-Resolution)
- 이러한 범용성 덕분에 이미지 생성 및 처리 분야에서 중요한 도구로 활용됨.
- Consistency Models [358]
- 디퓨전 모델의 효율성을 향상하여 고품질 이미지, 오디오, 비디오를 빠르게 생성할 수 있도록 설계됨.
- 단일 스텝 생성(single-step generation)을 가능하게 하여, 기존 디퓨전 모델이 갖고 있던 느린 샘플링 속도 문제를 해결함.
- 별도의 학습 없이 제로샷(Zero-Shot) 이미지 수정 작업 수행 가능
- 예: 이미지 복원(Inpainting), 색상화(Colorization), 초해상화(Super-Resolution)
- DALL-E [327]
- 텍스트 설명을 바탕으로 다양하고 복잡한 이미지 생성 가능.
- 자연어 이해(Natural Language Understanding)와 컴퓨터 비전(Computer Vision) 기술을 결합하여
- 간단한 설명부터 복잡한 시나리오까지 폭넓게 이미지 생성 가능.
- “Any-to-Any” 생성 모델
- 다양한 유형의 입력을 받아 여러 형태의 출력을 생성할 수 있도록 설계된 모델.
- CoDi [372]
- 다양한 입력 조합을 받아,
- 언어, 이미지, 비디오, 오디오 등 다양한 모달의 출력 생성 가능.
- 동시에 여러 모달을 생성할 수 있으며, 특정 입력 유형에 제한되지 않음.
- 기존 학습 데이터에 존재하지 않는 조합도 생성 가능하도록 설계됨.
- NExT-GPT [419]
- 다양한 모달(텍스트, 이미지, 비디오, 오디오) 입력을 처리하고 출력할 수 있는 기능 보유.
- 대형 기초 모델과 멀티모달 어댑터(multimodal adaptor), 디퓨전 모델을 결합하여 제작됨.
- 최소한의 파라미터 변경으로 파인튜닝 가능하여 비용 효율적인 훈련과 모달 확장이 용이함.
- 모달 전환 지시(Modality-Switching Instruction Tuning) 및 특별히 구축된 데이터셋 활용하여 크로스모달 콘텐츠 생성 및 이해 능력 향상.
- M4 [462]
- 모바일 AI를 위한 확장 가능한 기초 모델.
- 다양한 AI 작업을 하나의 모델로 통합.
- 텍스트, 이미지, 오디오, 모션 데이터 등 여러 입력을 처리하고 이해 및 추론 수행.
- 멀티모달 임베딩과 트랜스포머 기반 백본을 활용하여 효율성과 확장성을 극대화함.
인코더-FD 기초 모델(Encoder-FD FMs)
- UNITER [64]
- 멀티모달 환경에서 이미지와 텍스트를 통합적으로 처리하기 위한 초기 연구 중 하나.
- 트랜스포머를 활용하여 이미지와 텍스트 특징을 결합하여 공통 표현(joint representation)을 학습함.
- FLAVA [354], CoCa [459], GLIP [219]
- 디코더를 활용하여 이미지와 텍스트 표현을 더욱 효과적으로 결합 및 정렬(fusion and alignment)하는 연구.
- 멀티모달 추론(reasoning) 능력을 향상시키는 데 초점을 맞춤.
- SAM [190], SAM 2 [331]
- 프롬프트 임베딩(prompt embedding)을 이미지에 적용하여 텍스트 기반 제로샷 자동 이미지/비디오 분할 수행 가능.
- 즉, 텍스트만으로 이미지를 분석하고 자동으로 객체를 분리할 수 있는 기능 제공.
'AI' 카테고리의 다른 글
| Residual Block 이해하기 (0) | 2025.02.21 |
|---|---|
| Batch, Step, Epoch 이해하기 (1) | 2025.02.20 |
| [Object Detection] R-CNN, Fast R-CNN, Faster R-CNN (2) | 2024.12.18 |
| [논문] DoRA: Weight-Decomposed Low-Rank Adaptation (1) | 2024.12.16 |
| [논문] Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented Generation (2) | 2024.11.25 |