참고 링크 :
실험으로 알아보는 LLM 파인튜닝 최적화 가이드 Part 1.
devocean.sk.com
1. Batch, Step, Epoch
Batch, Step 그리고 Epoch은 LLM 학습 과정에서 데이터 처리를 정의 하는 단위로, 학습 효율성과 성능에 직접적인 영향을 미칩니다.
또한 학습 과정을 효과적으로 모니터링하려면 어떤 지표를 중심으로 관찰 할지 명확히 이해 하는 것도 중요합니다.
1.1 Batch
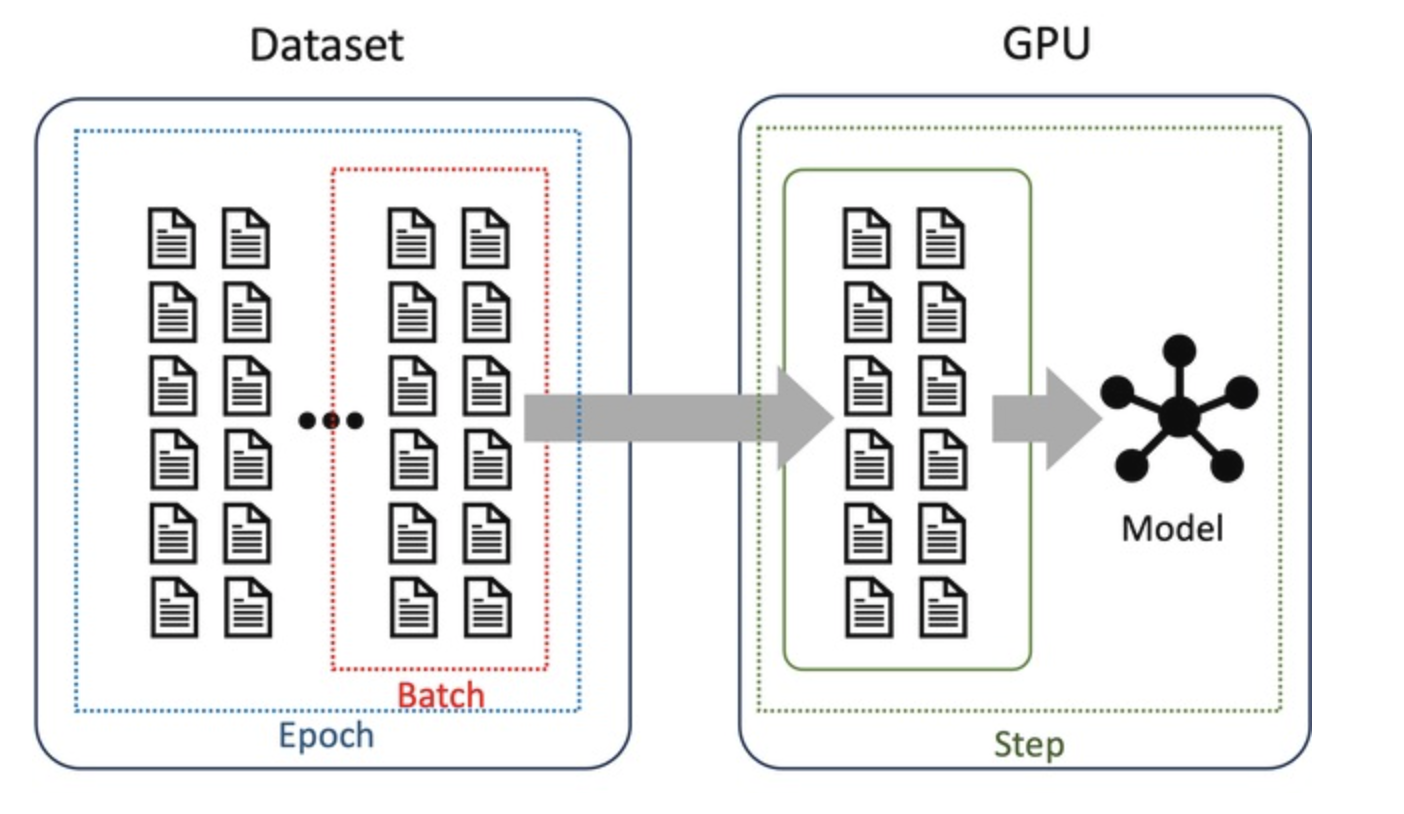
Batch 크기는 한 번의 학습 단계(Training Step)에서 모델이 처리하는 데이터 샘플의 개수를 의미한다.
그림 1에서 볼 수 있듯이, 학습을 위해 데이터셋에서 선택된 데이터 묶음이 바로 Batch이다.
예를 들어, Batch 크기가 10이라면, 한 번의 Training Step에서 모델은 10개의 샘플을 이용하여 모델 파라미터를 업데이트한다.
Batch 크기는 학습 속도와 메모리 사용량에 직접적인 영향을 주며, 크기에 따라 학습 과정의 특성이 달라진다. 이에 대한 자세한 내용은 다음 섹션에서 설명한다.
1.2 Step
Training Step(흔히 Step라고 불림)은 모델의 파라미터가 한 번 업데이트되는 과정을 의미한다.
그림 1에서 확인할 수 있듯이, 모델은 Batch 크기만큼의 데이터를 GPU에 로드하여 학습을 진행한 후, 파라미터를 업데이트한다.
예를 들어, 데이터셋의 크기가 10,000개이고 Batch 크기가 10이라면,

즉, 데이터셋 전체를 한 번 학습하려면 1,000번의 Training Step이 필요하다.
1.3 Epoch
Epoch은 모델이 학습 데이터셋의 모든 샘플을 한 번씩 학습하는 과정을 의미한다.
즉, 데이터셋 전체를 한 번 학습한 상태를 1 Epoch라고 한다.
1.4 LLM 학습에서 Training Step vs Epoch
대규모 언어 모델(LLM)을 학습할 때는 보통 Training Step을 기준으로 학습 지표를 설정한다.
이는 LLM 학습의 특성과 효율적인 학습 관리를 고려했을 때, Step 단위의 관리가 더 적합하기 때문이다.
1.4.1 Step을 기준으로 학습하는 이유
- 모델 파라미터 업데이트 단위
- LLM 학습은 파라미터 업데이트를 중심으로 진행되며, 이 과정은 Training Step 단위로 실행된다.
- 학습률 조정 및 스케줄링
- 학습률 조정(Warm-up 및 Decay)과 같은 중요한 학습 전략은 일반적으로 Step 단위를 기준으로 적용한다.
- Gradient Accumulation 역시 Step 단위로 이루어지며, 이를 통해 학습의 안정성과 효율성을 향상시킬 수 있다.
- Early Stopping 및 모델 모니터링
- 학습 중 목표 성능에 도달하거나 추가적인 개선이 없는 경우, Early Stopping을 통해 불필요한 학습을 방지하는데, 이는 보통 Training Step을 기준으로 수행한다.
1.4.2 Epoch을 기준으로 학습하는 경우
- 소규모 데이터셋을 활용한 파인튜닝
- 데이터셋이 작을 경우, 모델이 전체 데이터를 몇 번 학습했는지(Epoch 수)가 중요한 성능 지표가 된다.
- 과적합(Overfitting) 방지
- Epoch 단위로 학습 곡선을 모니터링하면, Validation Loss의 급격한 증가 등 과적합 징후를 조기에 감지할 수 있다.
2. Batch
딥러닝 모델, 특히 LLM을 학습할 때 배치 크기(Batch Size)는 가장 중요한 하이퍼파라미터 중 하나이다.
이전 섹션에서 설명했듯이, 배치 크기는 한 번의 학습 단계(Training Step)에서 처리되는 데이터 샘플의 개수를 의미하며, 모델의 학습 속도와 성능에 직접적인 영향을 미친다.
HF Training Arguments 예시
per_device_train_batch_size=8
per_device_eval_batch_size=8
2.1 작은 배치 vs 큰 배치
배치 크기에 따라 학습 과정에서 다음과 같은 차이가 나타난다.
작은 배치 크기
- 학습 과정이 불안정할 수 있지만, 일반화 성능이 더 좋아지는 경향이 있다.
- 메모리 사용량이 적어 제한된 자원에서도 학습할 수 있지만, 전체 학습 시간이 길어질 가능성이 있다.
큰 배치 크기
- 학습이 더 안정적이지만, 세부적인 특징을 놓칠 가능성이 있어 과적합(Overfitting)의 위험이 있다.
- 더 많은 메모리가 필요하지만 학습 속도를 더 빠르게 할 수 있다.
이러한 차이를 확인하기 위해 gemma-2-2b-it 모델을 사용하여 배치 크기를 1에서 16까지 점진적으로 증가시키며 학습을 진행해 보았다.
학습 곡선 변화
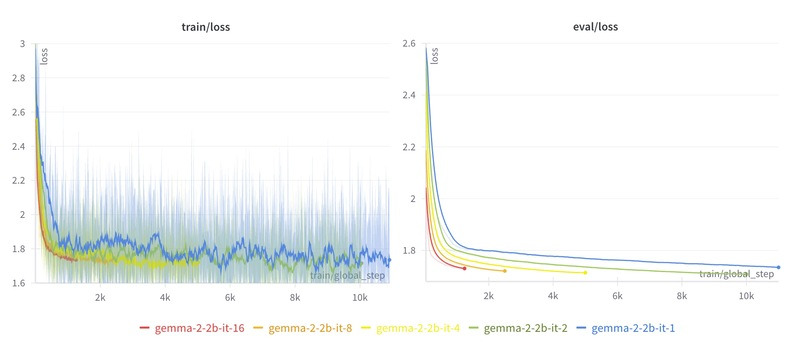
그림 2의 그래프는 Train Loss와 Eval Loss를 나타내며, 배치 크기에 따라 색상으로 구분된다.
(파랑: 1, 녹색: 2, 노랑: 4, 주황: 8, 빨강: 16)
- 작은 배치 크기(1~2개): Loss 곡선의 변동성이 크며, 이는 학습이 불안정하다는 것을 의미한다. 배치 크기가 작을수록 학습에 사용되는 샘플 수가 적어 데이터 샘플링 노이즈의 영향을 크게 받는다.
- 큰 배치 크기(8~16개): Loss 곡선의 변동성이 작아지며 학습이 더 안정적으로 진행된다. 이는 한 번에 더 많은 데이터를 처리하여 샘플 노이즈의 영향을 평균화하기 때문이다.
학습 속도 및 GPU 자원 사용량
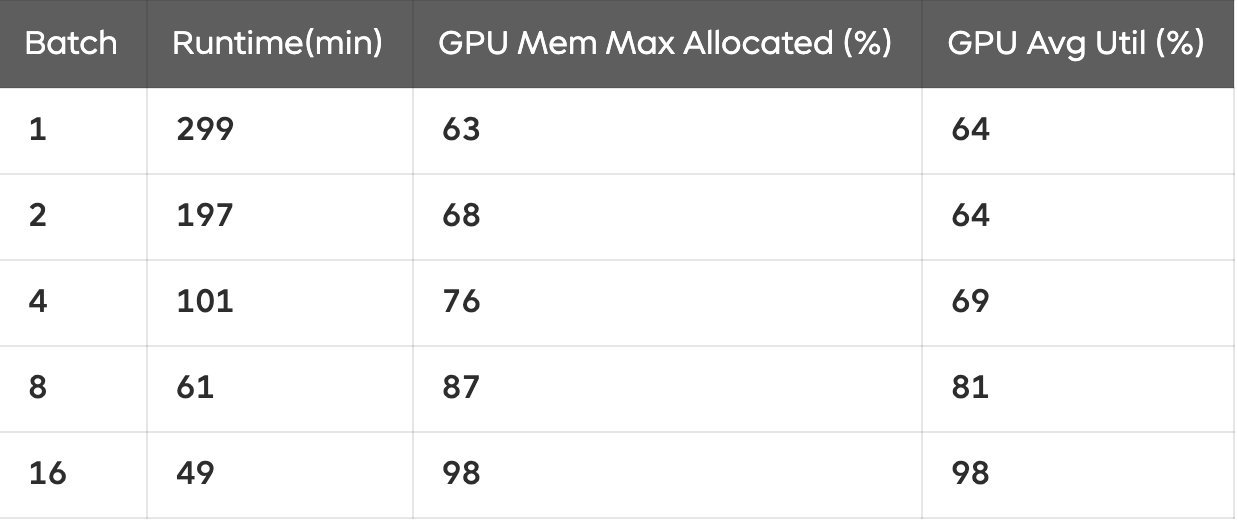
표 1에서 볼 수 있듯이, 배치 크기가 증가할수록 학습 속도가 빨라지고 GPU 활용도가 높아지는 경향이 있다.
특히 배치가 작을수록 GPU 자원을 비효율적으로 사용하는 모습이 나타난다.
2.2 배치 크기 설정 시 고려할 요소
실험을 통해 배치 크기에 따른 학습 안정성과 학습 시간을 확인했으며, 배치 크기를 설정할 때 다음과 같은 요소들을 고려하는 것이 좋다.
✔ 모델 크기 및 자원 제약
- 사용 중인 모델의 크기와 GPU 메모리를 확인해야 한다.
- 모델이 커서 GPU 메모리를 많이 차지할 경우, 배치를 늘리기 위해 추가 GPU를 활용한 분산 학습을 고려해야 한다.
✔ 학습 안정성 vs. 일반화 성능
- 메모리가 충분하다면 큰 배치 크기를 사용하는 것이 효율적이다.
- 다만, 큰 배치를 사용할 때 과적합이 발생하면 배치 크기를 줄여 일반화 성능을 개선하는 것도 방법이다.
✔ 메모리 제약 해결 방법
- GPU 메모리가 부족해 배치 크기를 늘리기 어렵다면, Gradient Accumulation이나 Gradient Checkpointing을 활용해 해결할 수 있다.
2.3 과적합(Overfitting)
과적합은 모델이 학습 데이터에는 매우 잘 맞지만, 새로운 데이터에서는 성능이 떨어지는 현상을 의미한다.
예를 들어, 파인튜닝을 진행할 때 학습 데이터의 Loss는 계속 줄어드는데, 평가 데이터의 Loss는 오히려 증가하는 경우가 발생할 수 있다. 이는 모델이 학습 데이터에 지나치게 최적화된 나머지, 학습하지 않은 새로운 데이터(즉, 평가 데이터)에서 일반화 성능이 낮아졌다는 뜻이다.
과적합이 발생하는 원인은 다양하지만, 큰 배치 크기와 지나친 반복 학습도 주요한 원인 중 하나이다.
특히 학습 데이터셋이 작은 경우, 큰 배치를 사용하면 데이터의 세부적인 특징을 놓칠 가능성이 높아진다. 따라서 배치 크기를 늘리기 전에 학습할 데이터가 충분한지를 먼저 고려해야 한다.
흥미로운 점은, 도메인 특화 모델을 만들고자 할 때 일부러 과적합을 유도하는 경우도 있다.
이러한 경우에는 특정 도메인 데이터에 최적화된 모델을 만들기 위해, 모델이 도메인 데이터의 특성을 더욱 세밀하게 학습하도록 유도하는 방식으로 접근한다. 즉, 특정한 데이터셋에서 높은 성능을 내기 위해 일부러 일반화 성능을 희생하는 전략을 선택할 수도 있다.
3. Sequence Length
LLM은 입력으로 받을 수 있는 최대 토큰 길이(시퀀스 길이)가 기본적으로 정해져 있다.
일반적으로 512~8,192 토큰 사이에서 설정되지만, 최근에는 상대적 위치 인코딩(Relative Positional Encoding) 기법을 활용하여 128,000개 이상의 토큰도 처리할 수 있게 되었다.
Q. RPE는 단어 위치만 고려할 수 있게 되는거 아니었나?? 왜 토큰 길이도 늘어나는 것이지?
1️⃣ 기존 Positional Encoding (절대적 위치 인코딩, APE)의 한계
기본적인 Transformer 모델(예: GPT, BERT)은 절대적 위치 인코딩(Absolute Positional Encoding, APE)을 사용한다.
💡절대적 위치 인코딩(APE)의 원리
Transformer는 원래 순서를 고려하지 않는 구조이므로, 단어의 위치 정보를 따로 추가해야 한다.
이때 사용하는 것이 바로 Positional Encoding이다.
절대적 위치 인코딩은 아래와 같이 특정 위치마다 고유한 벡터를 추가한다.
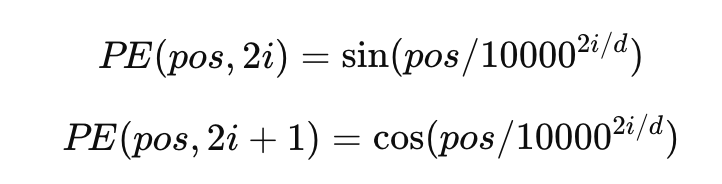
- pos: 단어의 위치 (1번째 단어인지, 2번째 단어인지)
- i: 벡터 차원의 인덱스
- d: 모델의 임베딩 차원 수
이렇게 하면 위치마다 고유한 위치 벡터가 만들어지고, 모델은 이를 이용해 단어의 순서를 인식한다.
❌ APE의 문제점: 시퀀스 길이를 늘리기 어렵다!
절대적 위치 인코딩은 미리 정해진 최대 길이까지 위치 벡터를 생성해야 한다.
예를 들어,
- GPT-2는 최대 1,024 토큰
- GPT-3는 최대 2,048 토큰
이렇게 제한된 크기의 위치 인코딩을 사용한다.
문제는, 모델이 처음부터 2,048개까지만 학습했다면, 2,049번째 단어가 들어오면 인코딩을 할 수 없다는 것이다.
→ 즉, 최대 길이를 넘어가면 확장할 수 없다!
2️⃣ Relative Positional Encoding (상대적 위치 인코딩, RPE)의 등장
RPE는 위치 자체가 아니라, 단어들 간의 상대적 거리를 학습하는 방식이다.
즉, 특정한 단어의 절대 위치가 아니라, 이전 단어와의 거리를 표현한다.
💡 RPE의 원리: 단어 위치가 아니라 "상대적 거리"를 사용한다
기존의 절대적 위치 인코딩은 단어의 고정된 위치를 저장했지만,
상대적 위치 인코딩은 두 단어 간의 거리를 계산하여 위치 정보를 표현한다.
예를 들어,
- "강아지가 뛰었다" → "강아지"와 "뛰었다"의 상대적 거리는 2
- "강아지가 매우 빠르게 뛰었다" → "강아지"와 "뛰었다"의 상대적 거리는 4
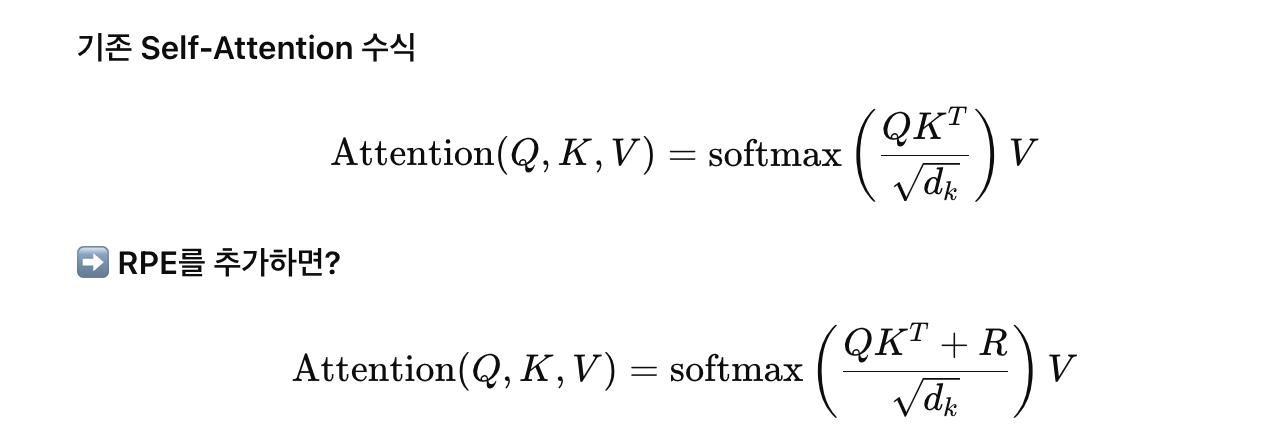
위에 있는 수식이 절대적 위치 인코딩(APE) 방식, 아래 수식이 상대적 위치 인코딩(RPE) 방식이다.
절대적 위치 인코딩(APE)에서는 위치 정보를 직접 입력 임베딩에 더해준다.
즉, 위치 정보는 Attention Score(즉, QKTQK^T)에 직접 추가되지 않고, 입력 토큰의 임베딩에 포함된다.이처럼, 모델이 단어들의 상대적인 거리만 인식하면,
시퀀스 길이가 길어져도 절대적인 위치 정보가 필요하지 않으므로 더 많은 토큰을 처리할 수 있다.
3️⃣ RPE를 활용하면 어떻게 128,000개 이상의 토큰을 처리할 수 있을까?
💡 1. 기존 Transformer는 시퀀스 길이마다 고유한 벡터를 저장해야 한다.
→ 최대 2,048개까지 학습한 모델은 2,049번째 토큰을 처리할 수 없다.
💡2. RPE는 단어 간의 상대적 거리만 계산한다.
→ 새로운 단어가 추가되어도, 기존 단어들과의 거리 정보만 알면 학습이 가능하다.
→ 즉, 128,000개 이상이 들어와도 "거리를 계산하는 방식"이므로 문제없이 확장된다!
4️⃣ RPE의 추가적인 장점
✔ 메모리 사용량 감소
- 기존 APE는 모든 단어에 대해 위치 벡터를 저장해야 해서 메모리 사용량이 증가한다.
- 하지만 RPE는 상대적인 거리만 계산하면 되므로, 메모리 사용량이 훨씬 줄어든다.
✔ 학습된 범위를 넘어가도 사용 가능
- 기존 Transformer는 사전에 정한 길이까지만 학습할 수 있다.
- RPE는 학습된 길이보다 더 긴 문장도 자연스럽게 확장하여 사용할 수 있다.
HF Training Arguments 예시
max_seq_length=1024
3.1 시퀀스 길이와 배치 크기의 관계
시퀀스 길이는 배치 크기에 직접적인 영향을 미친다.
예를 들어, 최대 시퀀스 길이가 8,192인 모델에서 배치 크기를 8로 설정했다고 가정해 보자.
- 시퀀스 길이를 512로 설정하면 한 번의 입력에서 512 × 8 = 4,096 토큰이 처리된다.
- 시퀀스 길이를 8,192로 설정하면 한 번의 입력에서 8,192 × 8 = 65,536 토큰이 처리된다.
이처럼 시퀀스 길이가 길어질수록 모델이 처리해야 할 토큰 수가 급격히 증가하며, 이에 따라 GPU 메모리 사용량도 크게 늘어난다.
따라서 사용 중인 GPU의 메모리 용량이 충분하지 않다면 OOM(Out of Memory) 오류가 발생하면서 학습이 중단될 수 있다.
3.2 작업 유형에 따른 시퀀스 길이
LLM의 작업 유형과 데이터셋의 특성에 따라 적절한 시퀀스 길이를 선택해야 한다.
- 일반적인 파인튜닝
- 대부분의 경우 4,096 이하의 시퀀스 길이로 처리 가능하다.
- 대화형 AI, 텍스트 요약, 질문 응답(Q/A) 등의 작업은 한정된 맥락 내에서 이루어지므로 긴 시퀀스가 필요하지 않은 경우가 많다.
- RAG(Retrieval-Augmented Generation)
- 검색된 정보를 바탕으로 답변을 생성해야 하므로 8,192 이상의 시퀀스 길이가 유리하다.
- 긴 문맥을 유지해야 검색된 정보의 정확성과 응답 품질이 향상될 수 있다.
3.3 LLM이 입력 데이터를 처리하는 방식
LLM은 배치(batch) 내 모든 샘플의 길이가 동일해야 병렬 연산이 가능하다.
이를 맞추기 위해 패딩(Padding) 과 잘림(Truncation) 이라는 두 가지 기법을 사용한다.
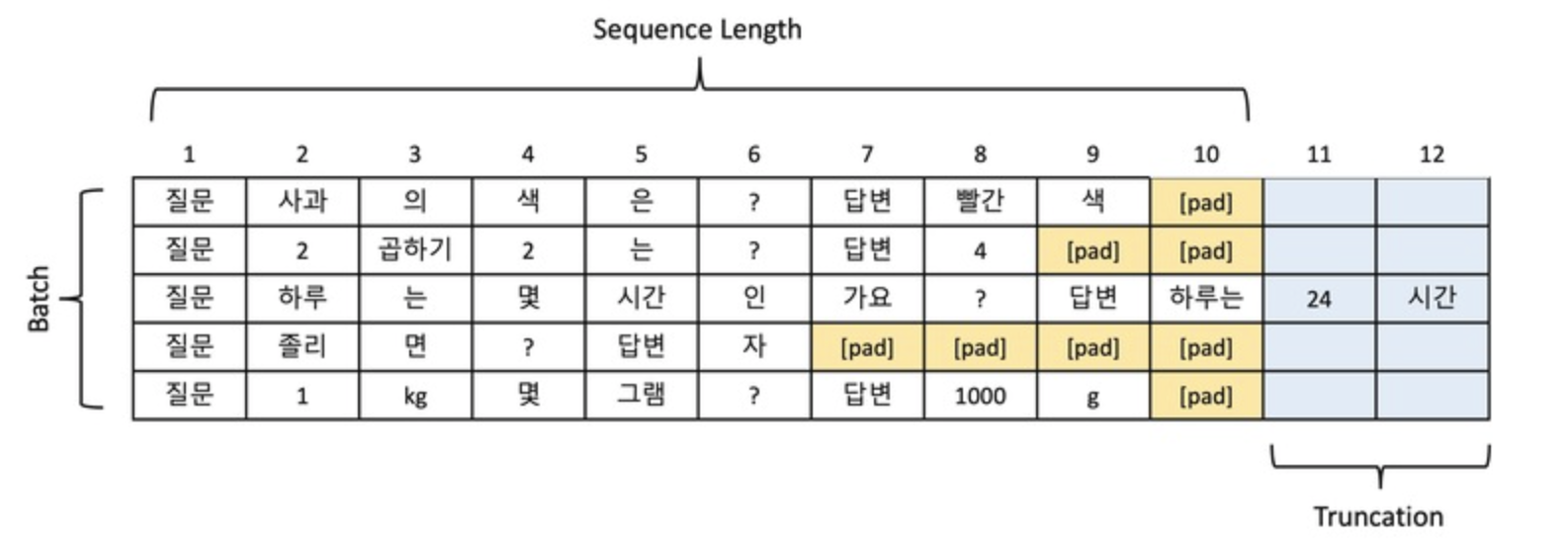
3.3.1 패딩(Padding)
패딩은 짧은 샘플의 길이를 배치 내 가장 긴 샘플에 맞추기 위해 특수 토큰([PAD])을 추가하는 과정이다.
예를 들어, 각 샘플의 시퀀스 길이를 10으로 맞추기 위해, 길이가 부족한 샘플의 끝에 [PAD] 토큰을 추가할 수 있다.
패딩의 위치는 모델 설정에 따라 다를 수 있으며,
- 오른쪽 패딩: 일반적으로 많이 사용됨.
- 왼쪽 패딩: Autoregressive 모델(GPT 계열)에서 유리할 수 있음.
- 양쪽 패딩: 특정 모델에서 필요할 수 있음.
패딩을 통해 모든 샘플의 길이가 동일해지면, LLM은 이를 병렬로 처리할 수 있다.
3.3.2 잘림(Truncation)
잘림은 모델의 시퀀스 길이 제한을 초과하는 샘플에서 초과된 부분을 제거하는 과정이다.
예를 들어, 시퀀스 길이를 10으로 제한해야 할 때, 12개 토큰으로 구성된 샘플이 있다면, 초과된 2개의 토큰을 제거해야 한다.
잘림은 보통 오른쪽(끝부분)에서 수행 되지만, 작업 특성에 따라 왼쪽에서 잘라내는 경우도 있다.
하지만, 잘림 과정에서 중요한 정보(예: 답변의 핵심 부분)가 제거될 수도 있기 때문에, 데이터셋을 직접 확인하고 적절한 시퀀스 길이를 설정하는 것이 중요하다.
3.4 시퀀스 길이 설정 시 고려할 요소
✔ 데이터셋 분포 분석
- 데이터셋 내 문장의 길이를 분석하여 적절한 시퀀스 길이를 설정하는 것이 좋다.
- 예를 들어, 데이터의 95%가 1,024 토큰 이하라면, 시퀀스 길이를 1,024로 설정하여 리소스를 최적화할 수 있다.
✔ 잘림된 데이터 확인
- 잘림으로 인해 중요한 정보가 손실되지 않는지 확인해야 한다.
- 중요한 정보가 잘려 나가면, 시퀀스 길이를 늘리는 것이 필요할 수 있다.
✔ 시퀀스 길이와 배치 크기의 균형
- 긴 시퀀스를 사용하면 모델의 성능이 좋아질 수 있지만, GPU 메모리 사용량이 증가하므로 배치 크기를 줄여야 할 수 있다.
- 데이터셋의 특성을 보고, 적절한 시퀀스 길이와 배치 크기를 조절하는 것이 중요하다.
3.5 패딩 위치: 왼쪽 vs. 오른쪽
패딩을 왼쪽 또는 오른쪽에 두는 것은 모델의 특성과 연산 효율성에 따라 다르다.
GPT와 같은 Autoregressive 모델에서는 왼쪽 패딩을 선호한다.
- GPT 계열 모델은 이전 입력을 바탕으로 다음 출력을 생성한다.
- 입력이 의미 있는 정보로 구성되어야, 모델이 다음 토큰을 잘 예측할 수 있다.
- 왼쪽에 PAD를 두면, 오른쪽에 유효한 데이터가 정렬되므로 모델이 더 자연스럽게 학습할 수 있다.
Instruction SFT에서는 오른쪽 패딩을 선호한다.
- Instruction SFT에서는 Instruction과 Output 쌍을 학습하며, Output의 끝에 EOS 토큰을 추가한다.
- 오른쪽 패딩을 사용하더라도 EOS 토큰이 명확히 포함되어 있으므로, 모델이 적절한 위치에서 출력을 종료할 수 있다.
- 또한, 오른쪽 패딩을 하면 여러 개의 입력을 배치로 정렬하기 쉽고, GPU에서 병렬 연산을 수행하는 데 효율적이다.
4. 메모리 최적화 기법
앞에서 살펴본 배치 크기나 시퀀스 길이를 조정하는 이유는 메모리 제한 때문이다.
이러한 메모리 제약을 극복하기 위한 기법으로 Gradient Accumulation과 Gradient Checkpointing이 있다.
4.1 Gradient Accumulation
Gradient Accumulation은 GPU 메모리가 부족하여 한 번에 큰 배치를 처리할 수 없는 경우 사용하는 기술이다.
이 기법은 작은 배치(mini-batch)에서 그래디언트를 계산한 후 누적(accumulate) 하고, 지정된 횟수(Accumulation Step)가 되면 한 번에 파라미터를 업데이트한다.
이를 통해 작은 배치에서도 큰 배치 크기와 유사한 학습 효과를 얻을 수 있다.
HF Training Arguments 예시
per_device_train_batch_size=8
gradient_accumulation_steps=4
4.1.1 Gradient Accumulation의 원리
기본적인 모델 학습 과정
1️⃣ Forward Pass: 배치를 모델에 입력하여 손실(loss)을 계산
2️⃣ Backward Pass: 손실을 기반으로 그래디언트(Gradient) 계산
3️⃣ Optimizer Update: 그래디언트를 바탕으로 모델 파라미터 업데이트
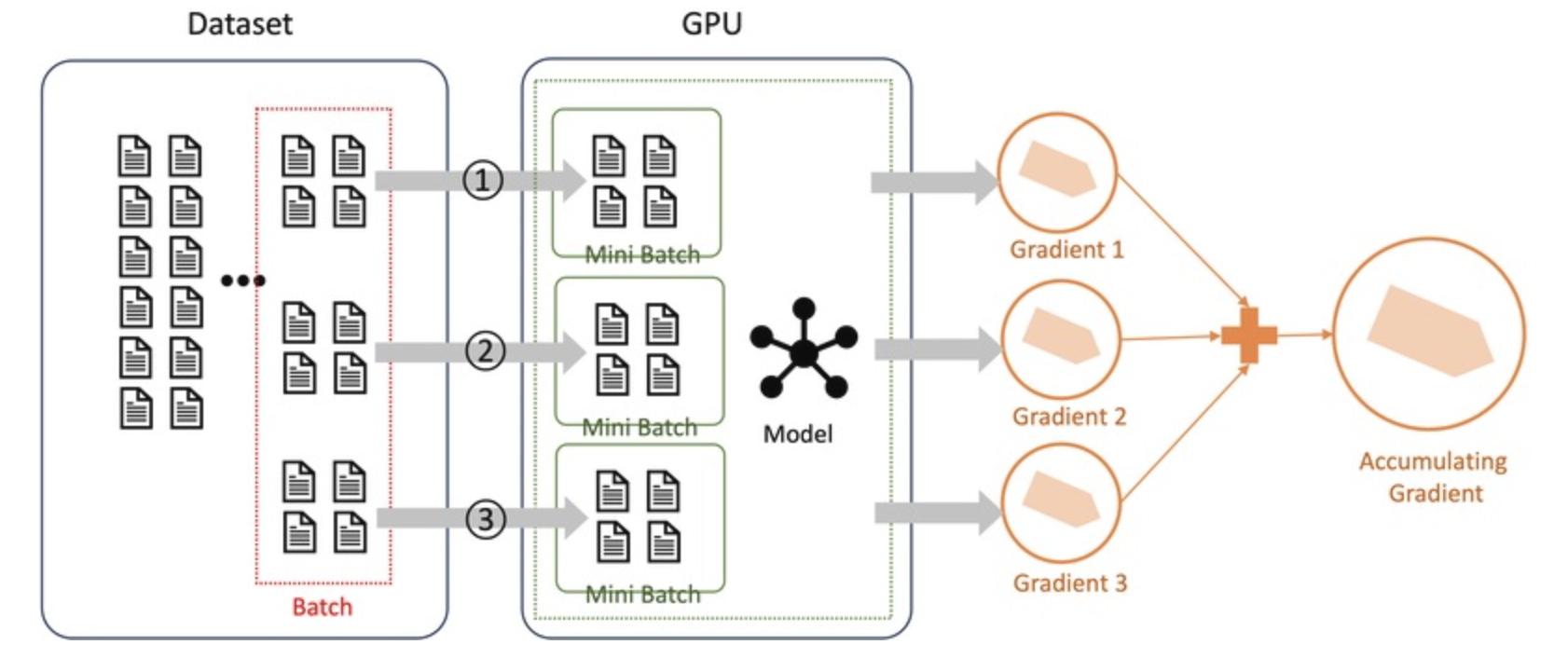
하지만 Gradient Accumulation을 적용하면?
1️⃣ 배치를 여러 개의 작은 mini-batch(예: 배치 1, 2, 3)로 나눈다.
2️⃣ 각 mini-batch에서 Forward와 Backward Pass를 수행하고 계산된 그래디언트(그림4에서 Gradient 1, 2, 3)를 누적(accumulate) 한다.
3️⃣ 지정된 Accumulation Step 횟수에 도달하면, Optimizer가 한 번에 파라미터를 업데이트한다.
4.1.2 Gradient Accumulation의 장점
1️⃣ GPU 메모리 제한 극복
- 한 번에 큰 배치를 학습하려면 많은 메모리가 필요하지만, Gradient Accumulation을 활용하면 작은 배치를 여러 번 학습하여 같은 효과를 낼 수 있다.
- 예:
- Batch Size 4 × Gradient Accumulation 2 → Effective Batch Size 8
- Batch Size 1 × Gradient Accumulation 8 → Effective Batch Size 8
2️⃣ 학습 안정성 및 속도 개선
아래 실험은 아래는 다양한 배치 크기와 Accumulation Step을 조합한 실험 결과이다.
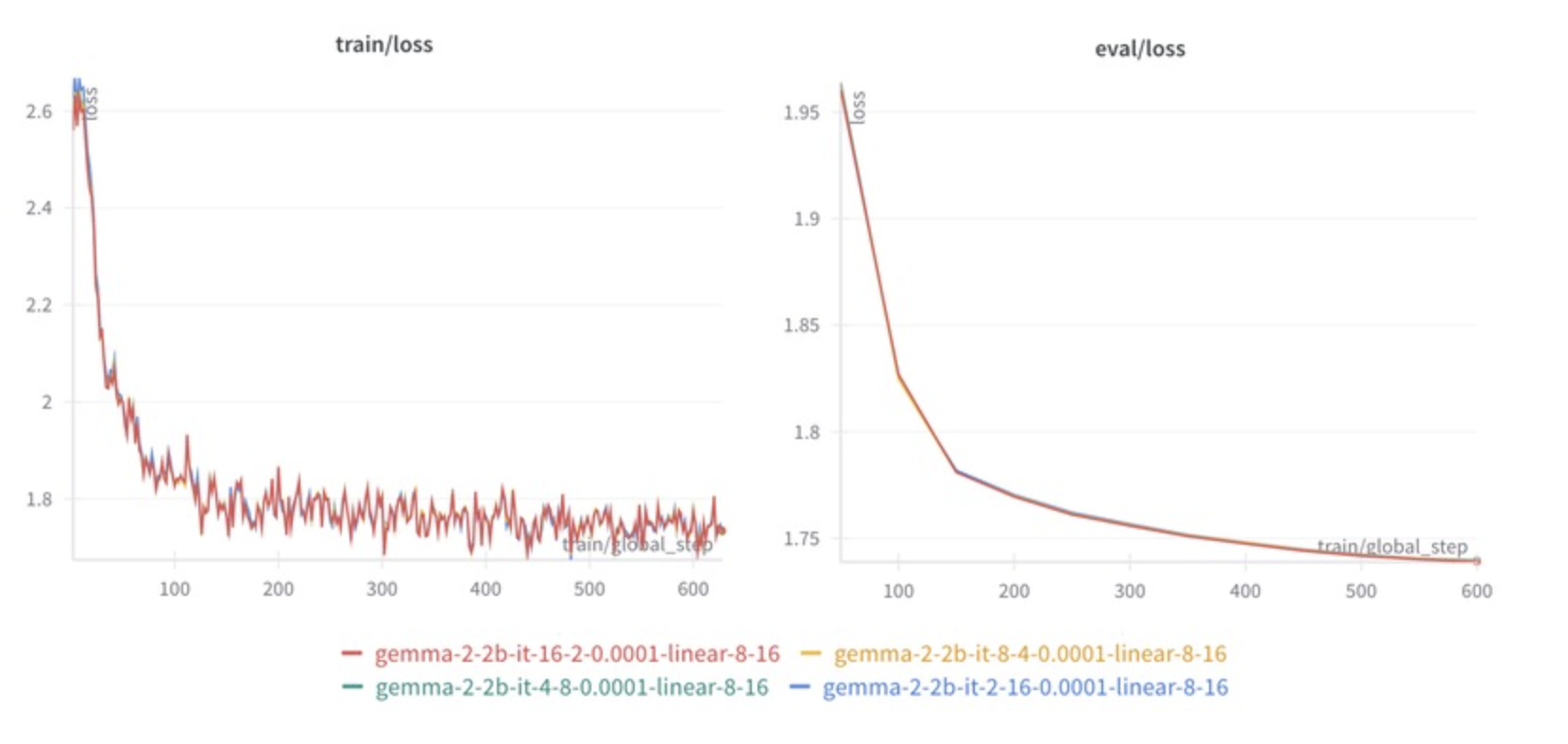
- 배치 크기가 클수록 학습이 더 안정적이고 수렴 속도가 빨라진다.
- Gradient Accumulation을 사용하면 작은 배치에서도 동일한 효과를 얻을 수 있다.
💡 하지만 작은 배치 크기를 사용할 경우,
- Forward와 Backward Pass를 여러 번 수행해야 하므로 학습 시간이 증가할 수 있다.
- GPU 자원을 충분히 활용하지 못해 비효율적인 학습이 될 수도 있다.
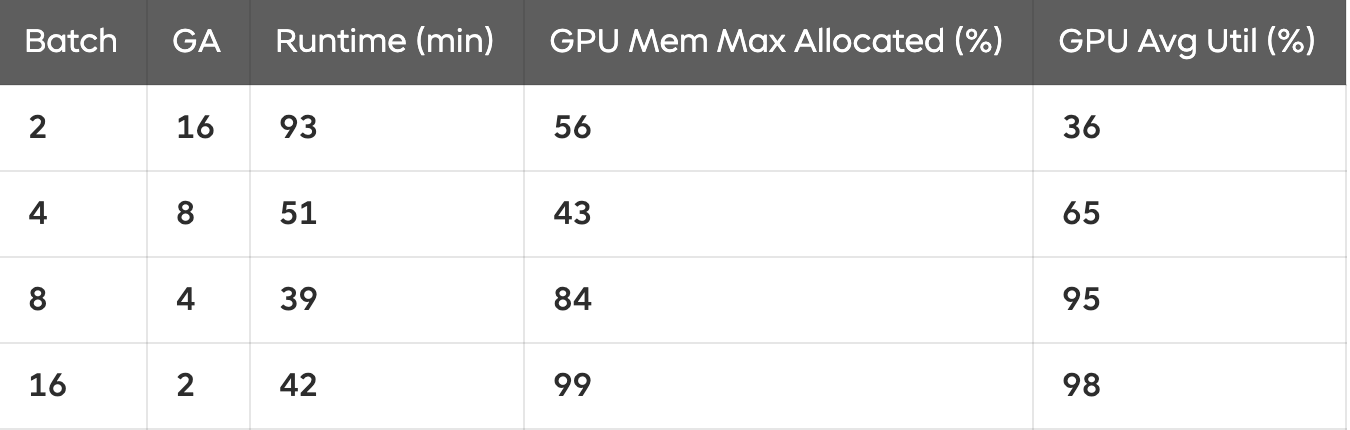
➡ 작은 배치 크기 + 높은 Accumulation Step을 조합하면 학습 시간이 증가하고, GPU 사용률이 낮아지는 문제가 발생할 수 있다.
4.1.3 Gradient Accumulation 설정 시 고려할 점
📍 목표 배치 크기 설정
- GPU 메모리에 맞춰 mini-batch 크기와 Gradient Accumulation Step을 조합해야 한다.
- 예: 목표 배치 크기가 32이고, GPU가 mini-batch 8개만 처리할 수 있다면 Gradient Accumulation Step = 4로 설정해서 전체 배치 크기를 32로 맞춘다.
📍 적절한 Accumulation Step 선택
- 이론적으로 같은 Effective Batch 크기면 학습 결과가 같아야 하지만,
- 너무 높은 Accumulation Step을 사용하면 수치적 불안정성이 발생할 수 있다.
- 보통 32 이하의 Accumulation Step을 많이 사용한다.
📍 분산 학습 시 오버헤드 고려
- 여러 GPU를 사용할 경우, 각 GPU에서 계산된 그래디언트를 누적하고 동기화하는 과정에서 성능 저하가 발생할 수 있다.
- 따라서 분산 학습 환경에서는 Accumulation Step을 적절히 조정해야 한다.
4.2 Gradient Checkpointing
Gradient Checkpointing은 메모리 사용량을 줄이기 위한 기법이다.
특히 Transformer처럼 레이어가 깊고 파라미터가 많은 모델에서 유용하다.
이 기법은 순전파(Forward Pass) 과정에서 생성되는 Activation 값을 일부만 저장하고, 역전파(Backward Pass) 과정에서 다시 계산하는 방식을 사용하여 메모리를 절약한다.
HF Training Arguments 예시
gradient_checkpointing=True
4.2.1 Gradient Checkpointing의 원리
1️⃣ 기존 방식 (모든 Activation 저장)
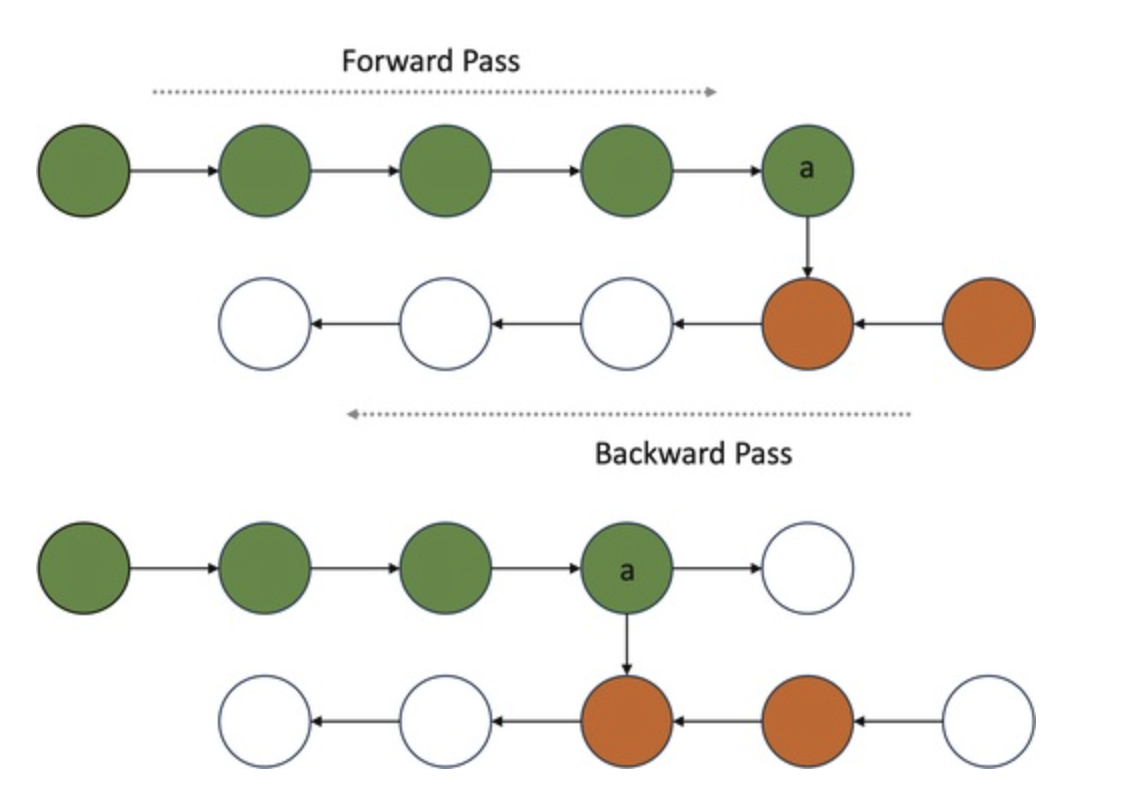
- 일반적으로 모델은 순전파를 수행하면서 Activation 값을 모두 저장하고, 역전파 시 이를 활용하여 그래디언트를 계산한다.
이 방식의 장점은 연산 속도가 빠르지만, 저장해야 할 Activation 값이 많아져 메모리 사용량이 크다는 단점이 있다.
특히, 모델의 깊이가 깊어질수록(즉, 레이어가 많아질수록) 저장해야 할 Activation 값도 많아져 GPU 메모리 부족 문제가 발생할 수 있다.
2️⃣ 모든 Activation을 삭제하고 Forward를 다시 계산
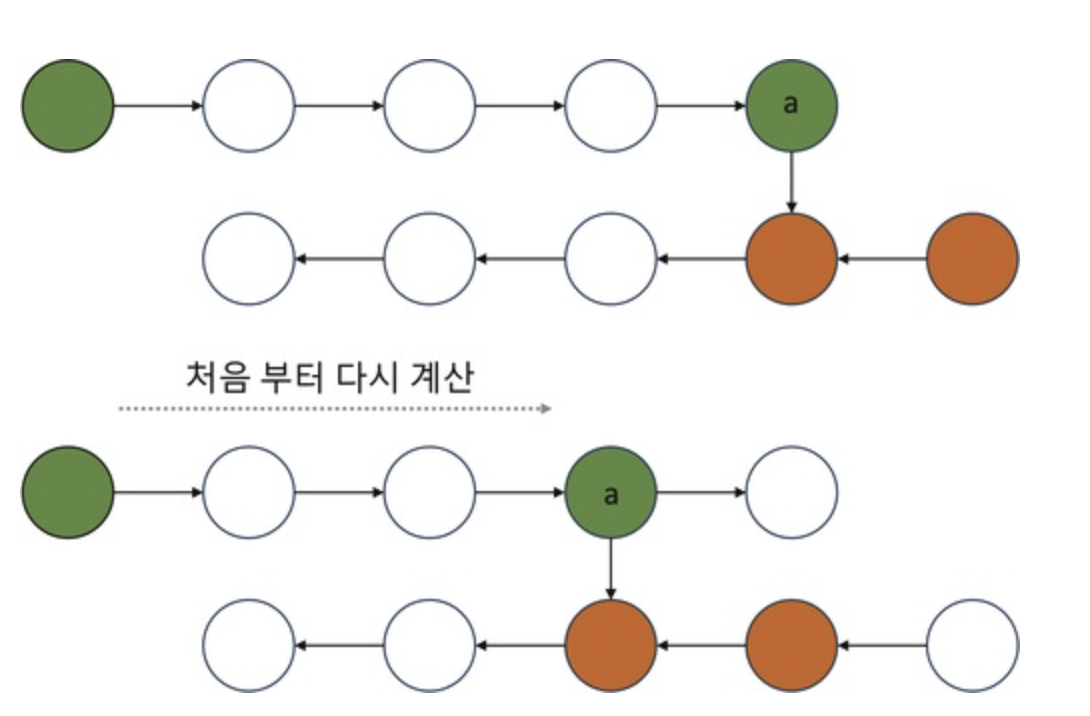
- 순전파(Forward Pass) 과정에서 모든 Activation 값을 저장한 뒤, 역전파가 끝나면 메모리에서 제거하는 방법이 있다.
이 방식은 역전파가 끝난 후 메모리를 해제한다는 점에서 메모리 절감 효과가 있지만, 역전파가 시작되기 전까지는 모든 Activation 값을 유지해야 하므로 절감 효과가 크지 않다. 즉, 순전파 과정에서 여전히 많은 메모리를 사용해야 하므로, 근본적인 해결책이 되지않는다. - 🚨 메모리는 절약되지만, 연산량 증가로 인해 학습 속도가 느려지는 단점이 있다.
3️⃣ Gradient Checkpointing (효율적인 절충안)
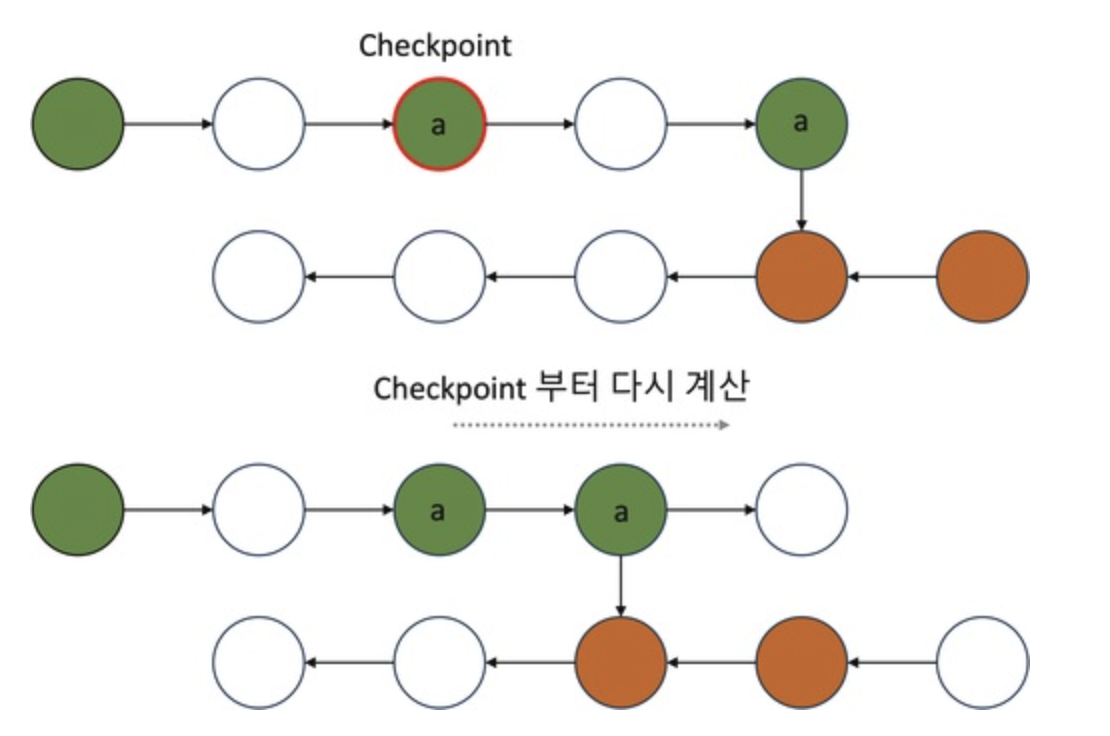
- Gradient Checkpointing은 위 두 가지 방식의 단점을 해결하기 위해 고안된 기법이다.
- 기본 개념은 모든 Activation 값을 저장하지 않고, 일정 간격으로 Activation 값을 저장(Checkpointing)하고, 나머지는 필요할 때만 다시 계산하는 방식이다.
- 즉, 모델의 모든 레이어에서 Activation을 저장하지 않고, 특정 레이어(Checkpoint)에서만 Activation 값을 저장하고, 역전파 시 저장된 Checkpoint 이후의 Activation 값만 다시 계산하여 필요한 값을 복원하는 방식이다.
- 이 방법을 사용하면 메모리 사용량을 크게 줄일 수 있으며, 불필요한 재계산을 줄여 연산 효율도 개선할 수 있다.
- 즉, 완전히 다시 Forward를 수행하는 것이 아니라, Checkpoint 이후의 연산만 다시 수행하므로 연산량을 줄이면서도 메모리 절감 효과를 얻을 수 있다.
4.2.2 Gradient Checkpointing의 효과
아래 표는 Gradient Checkpointing을 적용했을 때와 적용하지 않았을 때의 메모리 사용량과 학습 시간 비교이다.
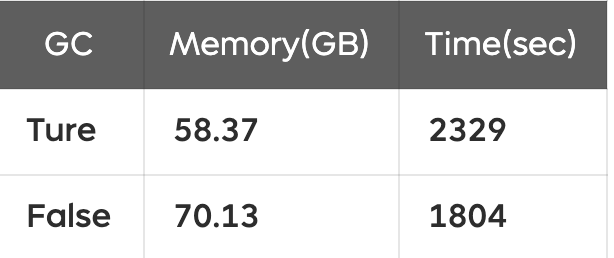
👍 메모리 사용량 감소: 70.13GB → 58.37GB (약 12GB 절감)
🚨 학습 시간 증가: 1804초 → 2329초 (약 29% 증가)
➡ Gradient Checkpointing을 사용하면 메모리를 절약할 수 있지만, 학습 시간이 증가하는 트레이드오프가 존재한다.
4.2.3 Gradient Checkpointing 설정 시 고려할 점
📍 메모리 절감 효과와 활용성
- 확보된 메모리를 활용해 배치 크기 또는 시퀀스 길이를 늘릴 수 있다.
- 특히 GPU 메모리가 부족한 환경에서 파인튜닝을 진행할 때 매우 효과적이다.
📍 적합성 평가
- Layer가 깊은 대형 모델일수록 효과가 크다.
- 하지만 작은 모델에서는 절감 효과가 적고, 연산량만 증가할 수도 있다.
- Gradient Checkpointing 적용 전, 메모리 절감 효과를 먼저 확인하는 것이 중요하다.
'AI' 카테고리의 다른 글
| [인최기] Semi-supervised learning (준지도학습) (0) | 2025.03.12 |
|---|---|
| Residual Block 이해하기 (0) | 2025.02.21 |
| [논문] A Survey of Resource-efficient LLM and Multimodal Foundation Models (0) | 2025.02.13 |
| [Object Detection] R-CNN, Fast R-CNN, Faster R-CNN (2) | 2024.12.18 |
| [논문] DoRA: Weight-Decomposed Low-Rank Adaptation (1) | 2024.12.16 |
참고 링크 :
실험으로 알아보는 LLM 파인튜닝 최적화 가이드 Part 1.
devocean.sk.com
1. Batch, Step, Epoch
Batch, Step 그리고 Epoch은 LLM 학습 과정에서 데이터 처리를 정의 하는 단위로, 학습 효율성과 성능에 직접적인 영향을 미칩니다.
또한 학습 과정을 효과적으로 모니터링하려면 어떤 지표를 중심으로 관찰 할지 명확히 이해 하는 것도 중요합니다.
1.1 Batch
Batch 크기는 한 번의 학습 단계(Training Step)에서 모델이 처리하는 데이터 샘플의 개수를 의미한다.
그림 1에서 볼 수 있듯이, 학습을 위해 데이터셋에서 선택된 데이터 묶음이 바로 Batch이다.
예를 들어, Batch 크기가 10이라면, 한 번의 Training Step에서 모델은 10개의 샘플을 이용하여 모델 파라미터를 업데이트한다.
Batch 크기는 학습 속도와 메모리 사용량에 직접적인 영향을 주며, 크기에 따라 학습 과정의 특성이 달라진다. 이에 대한 자세한 내용은 다음 섹션에서 설명한다.
1.2 Step
Training Step(흔히 Step라고 불림)은 모델의 파라미터가 한 번 업데이트되는 과정을 의미한다.
그림 1에서 확인할 수 있듯이, 모델은 Batch 크기만큼의 데이터를 GPU에 로드하여 학습을 진행한 후, 파라미터를 업데이트한다.
예를 들어, 데이터셋의 크기가 10,000개이고 Batch 크기가 10이라면,
즉, 데이터셋 전체를 한 번 학습하려면 1,000번의 Training Step이 필요하다.
1.3 Epoch
Epoch은 모델이 학습 데이터셋의 모든 샘플을 한 번씩 학습하는 과정을 의미한다.
즉, 데이터셋 전체를 한 번 학습한 상태를 1 Epoch라고 한다.
1.4 LLM 학습에서 Training Step vs Epoch
대규모 언어 모델(LLM)을 학습할 때는 보통 Training Step을 기준으로 학습 지표를 설정한다.
이는 LLM 학습의 특성과 효율적인 학습 관리를 고려했을 때, Step 단위의 관리가 더 적합하기 때문이다.
1.4.1 Step을 기준으로 학습하는 이유
- 모델 파라미터 업데이트 단위
- LLM 학습은 파라미터 업데이트를 중심으로 진행되며, 이 과정은 Training Step 단위로 실행된다.
- 학습률 조정 및 스케줄링
- 학습률 조정(Warm-up 및 Decay)과 같은 중요한 학습 전략은 일반적으로 Step 단위를 기준으로 적용한다.
- Gradient Accumulation 역시 Step 단위로 이루어지며, 이를 통해 학습의 안정성과 효율성을 향상시킬 수 있다.
- Early Stopping 및 모델 모니터링
- 학습 중 목표 성능에 도달하거나 추가적인 개선이 없는 경우, Early Stopping을 통해 불필요한 학습을 방지하는데, 이는 보통 Training Step을 기준으로 수행한다.
1.4.2 Epoch을 기준으로 학습하는 경우
- 소규모 데이터셋을 활용한 파인튜닝
- 데이터셋이 작을 경우, 모델이 전체 데이터를 몇 번 학습했는지(Epoch 수)가 중요한 성능 지표가 된다.
- 과적합(Overfitting) 방지
- Epoch 단위로 학습 곡선을 모니터링하면, Validation Loss의 급격한 증가 등 과적합 징후를 조기에 감지할 수 있다.
2. Batch
딥러닝 모델, 특히 LLM을 학습할 때 배치 크기(Batch Size)는 가장 중요한 하이퍼파라미터 중 하나이다.
이전 섹션에서 설명했듯이, 배치 크기는 한 번의 학습 단계(Training Step)에서 처리되는 데이터 샘플의 개수를 의미하며, 모델의 학습 속도와 성능에 직접적인 영향을 미친다.
HF Training Arguments 예시
per_device_train_batch_size=8
per_device_eval_batch_size=8
2.1 작은 배치 vs 큰 배치
배치 크기에 따라 학습 과정에서 다음과 같은 차이가 나타난다.
작은 배치 크기
- 학습 과정이 불안정할 수 있지만, 일반화 성능이 더 좋아지는 경향이 있다.
- 메모리 사용량이 적어 제한된 자원에서도 학습할 수 있지만, 전체 학습 시간이 길어질 가능성이 있다.
큰 배치 크기
- 학습이 더 안정적이지만, 세부적인 특징을 놓칠 가능성이 있어 과적합(Overfitting)의 위험이 있다.
- 더 많은 메모리가 필요하지만 학습 속도를 더 빠르게 할 수 있다.
이러한 차이를 확인하기 위해 gemma-2-2b-it 모델을 사용하여 배치 크기를 1에서 16까지 점진적으로 증가시키며 학습을 진행해 보았다.
학습 곡선 변화
그림 2의 그래프는 Train Loss와 Eval Loss를 나타내며, 배치 크기에 따라 색상으로 구분된다.
(파랑: 1, 녹색: 2, 노랑: 4, 주황: 8, 빨강: 16)
- 작은 배치 크기(1~2개): Loss 곡선의 변동성이 크며, 이는 학습이 불안정하다는 것을 의미한다. 배치 크기가 작을수록 학습에 사용되는 샘플 수가 적어 데이터 샘플링 노이즈의 영향을 크게 받는다.
- 큰 배치 크기(8~16개): Loss 곡선의 변동성이 작아지며 학습이 더 안정적으로 진행된다. 이는 한 번에 더 많은 데이터를 처리하여 샘플 노이즈의 영향을 평균화하기 때문이다.
학습 속도 및 GPU 자원 사용량
표 1에서 볼 수 있듯이, 배치 크기가 증가할수록 학습 속도가 빨라지고 GPU 활용도가 높아지는 경향이 있다.
특히 배치가 작을수록 GPU 자원을 비효율적으로 사용하는 모습이 나타난다.
2.2 배치 크기 설정 시 고려할 요소
실험을 통해 배치 크기에 따른 학습 안정성과 학습 시간을 확인했으며, 배치 크기를 설정할 때 다음과 같은 요소들을 고려하는 것이 좋다.
✔ 모델 크기 및 자원 제약
- 사용 중인 모델의 크기와 GPU 메모리를 확인해야 한다.
- 모델이 커서 GPU 메모리를 많이 차지할 경우, 배치를 늘리기 위해 추가 GPU를 활용한 분산 학습을 고려해야 한다.
✔ 학습 안정성 vs. 일반화 성능
- 메모리가 충분하다면 큰 배치 크기를 사용하는 것이 효율적이다.
- 다만, 큰 배치를 사용할 때 과적합이 발생하면 배치 크기를 줄여 일반화 성능을 개선하는 것도 방법이다.
✔ 메모리 제약 해결 방법
- GPU 메모리가 부족해 배치 크기를 늘리기 어렵다면, Gradient Accumulation이나 Gradient Checkpointing을 활용해 해결할 수 있다.
2.3 과적합(Overfitting)
과적합은 모델이 학습 데이터에는 매우 잘 맞지만, 새로운 데이터에서는 성능이 떨어지는 현상을 의미한다.
예를 들어, 파인튜닝을 진행할 때 학습 데이터의 Loss는 계속 줄어드는데, 평가 데이터의 Loss는 오히려 증가하는 경우가 발생할 수 있다. 이는 모델이 학습 데이터에 지나치게 최적화된 나머지, 학습하지 않은 새로운 데이터(즉, 평가 데이터)에서 일반화 성능이 낮아졌다는 뜻이다.
과적합이 발생하는 원인은 다양하지만, 큰 배치 크기와 지나친 반복 학습도 주요한 원인 중 하나이다.
특히 학습 데이터셋이 작은 경우, 큰 배치를 사용하면 데이터의 세부적인 특징을 놓칠 가능성이 높아진다. 따라서 배치 크기를 늘리기 전에 학습할 데이터가 충분한지를 먼저 고려해야 한다.
흥미로운 점은, 도메인 특화 모델을 만들고자 할 때 일부러 과적합을 유도하는 경우도 있다.
이러한 경우에는 특정 도메인 데이터에 최적화된 모델을 만들기 위해, 모델이 도메인 데이터의 특성을 더욱 세밀하게 학습하도록 유도하는 방식으로 접근한다. 즉, 특정한 데이터셋에서 높은 성능을 내기 위해 일부러 일반화 성능을 희생하는 전략을 선택할 수도 있다.
3. Sequence Length
LLM은 입력으로 받을 수 있는 최대 토큰 길이(시퀀스 길이)가 기본적으로 정해져 있다.
일반적으로 512~8,192 토큰 사이에서 설정되지만, 최근에는 상대적 위치 인코딩(Relative Positional Encoding) 기법을 활용하여 128,000개 이상의 토큰도 처리할 수 있게 되었다.
Q. RPE는 단어 위치만 고려할 수 있게 되는거 아니었나?? 왜 토큰 길이도 늘어나는 것이지?
1️⃣ 기존 Positional Encoding (절대적 위치 인코딩, APE)의 한계
기본적인 Transformer 모델(예: GPT, BERT)은 절대적 위치 인코딩(Absolute Positional Encoding, APE)을 사용한다.
💡절대적 위치 인코딩(APE)의 원리
Transformer는 원래 순서를 고려하지 않는 구조이므로, 단어의 위치 정보를 따로 추가해야 한다.
이때 사용하는 것이 바로 Positional Encoding이다.
절대적 위치 인코딩은 아래와 같이 특정 위치마다 고유한 벡터를 추가한다.
- pos: 단어의 위치 (1번째 단어인지, 2번째 단어인지)
- i: 벡터 차원의 인덱스
- d: 모델의 임베딩 차원 수
이렇게 하면 위치마다 고유한 위치 벡터가 만들어지고, 모델은 이를 이용해 단어의 순서를 인식한다.
❌ APE의 문제점: 시퀀스 길이를 늘리기 어렵다!
절대적 위치 인코딩은 미리 정해진 최대 길이까지 위치 벡터를 생성해야 한다.
예를 들어,
- GPT-2는 최대 1,024 토큰
- GPT-3는 최대 2,048 토큰
이렇게 제한된 크기의 위치 인코딩을 사용한다.
문제는, 모델이 처음부터 2,048개까지만 학습했다면, 2,049번째 단어가 들어오면 인코딩을 할 수 없다는 것이다.
→ 즉, 최대 길이를 넘어가면 확장할 수 없다!
2️⃣ Relative Positional Encoding (상대적 위치 인코딩, RPE)의 등장
RPE는 위치 자체가 아니라, 단어들 간의 상대적 거리를 학습하는 방식이다.
즉, 특정한 단어의 절대 위치가 아니라, 이전 단어와의 거리를 표현한다.
💡 RPE의 원리: 단어 위치가 아니라 "상대적 거리"를 사용한다
기존의 절대적 위치 인코딩은 단어의 고정된 위치를 저장했지만,
상대적 위치 인코딩은 두 단어 간의 거리를 계산하여 위치 정보를 표현한다.
예를 들어,
- "강아지가 뛰었다" → "강아지"와 "뛰었다"의 상대적 거리는 2
- "강아지가 매우 빠르게 뛰었다" → "강아지"와 "뛰었다"의 상대적 거리는 4
위에 있는 수식이 절대적 위치 인코딩(APE) 방식, 아래 수식이 상대적 위치 인코딩(RPE) 방식이다.
절대적 위치 인코딩(APE)에서는 위치 정보를 직접 입력 임베딩에 더해준다.
즉, 위치 정보는 Attention Score(즉, QKTQK^T)에 직접 추가되지 않고, 입력 토큰의 임베딩에 포함된다.이처럼, 모델이 단어들의 상대적인 거리만 인식하면,
시퀀스 길이가 길어져도 절대적인 위치 정보가 필요하지 않으므로 더 많은 토큰을 처리할 수 있다.
3️⃣ RPE를 활용하면 어떻게 128,000개 이상의 토큰을 처리할 수 있을까?
💡 1. 기존 Transformer는 시퀀스 길이마다 고유한 벡터를 저장해야 한다.
→ 최대 2,048개까지 학습한 모델은 2,049번째 토큰을 처리할 수 없다.
💡2. RPE는 단어 간의 상대적 거리만 계산한다.
→ 새로운 단어가 추가되어도, 기존 단어들과의 거리 정보만 알면 학습이 가능하다.
→ 즉, 128,000개 이상이 들어와도 "거리를 계산하는 방식"이므로 문제없이 확장된다!
4️⃣ RPE의 추가적인 장점
✔ 메모리 사용량 감소
- 기존 APE는 모든 단어에 대해 위치 벡터를 저장해야 해서 메모리 사용량이 증가한다.
- 하지만 RPE는 상대적인 거리만 계산하면 되므로, 메모리 사용량이 훨씬 줄어든다.
✔ 학습된 범위를 넘어가도 사용 가능
- 기존 Transformer는 사전에 정한 길이까지만 학습할 수 있다.
- RPE는 학습된 길이보다 더 긴 문장도 자연스럽게 확장하여 사용할 수 있다.
HF Training Arguments 예시
max_seq_length=1024
3.1 시퀀스 길이와 배치 크기의 관계
시퀀스 길이는 배치 크기에 직접적인 영향을 미친다.
예를 들어, 최대 시퀀스 길이가 8,192인 모델에서 배치 크기를 8로 설정했다고 가정해 보자.
- 시퀀스 길이를 512로 설정하면 한 번의 입력에서 512 × 8 = 4,096 토큰이 처리된다.
- 시퀀스 길이를 8,192로 설정하면 한 번의 입력에서 8,192 × 8 = 65,536 토큰이 처리된다.
이처럼 시퀀스 길이가 길어질수록 모델이 처리해야 할 토큰 수가 급격히 증가하며, 이에 따라 GPU 메모리 사용량도 크게 늘어난다.
따라서 사용 중인 GPU의 메모리 용량이 충분하지 않다면 OOM(Out of Memory) 오류가 발생하면서 학습이 중단될 수 있다.
3.2 작업 유형에 따른 시퀀스 길이
LLM의 작업 유형과 데이터셋의 특성에 따라 적절한 시퀀스 길이를 선택해야 한다.
- 일반적인 파인튜닝
- 대부분의 경우 4,096 이하의 시퀀스 길이로 처리 가능하다.
- 대화형 AI, 텍스트 요약, 질문 응답(Q/A) 등의 작업은 한정된 맥락 내에서 이루어지므로 긴 시퀀스가 필요하지 않은 경우가 많다.
- RAG(Retrieval-Augmented Generation)
- 검색된 정보를 바탕으로 답변을 생성해야 하므로 8,192 이상의 시퀀스 길이가 유리하다.
- 긴 문맥을 유지해야 검색된 정보의 정확성과 응답 품질이 향상될 수 있다.
3.3 LLM이 입력 데이터를 처리하는 방식
LLM은 배치(batch) 내 모든 샘플의 길이가 동일해야 병렬 연산이 가능하다.
이를 맞추기 위해 패딩(Padding) 과 잘림(Truncation) 이라는 두 가지 기법을 사용한다.
3.3.1 패딩(Padding)
패딩은 짧은 샘플의 길이를 배치 내 가장 긴 샘플에 맞추기 위해 특수 토큰([PAD])을 추가하는 과정이다.
예를 들어, 각 샘플의 시퀀스 길이를 10으로 맞추기 위해, 길이가 부족한 샘플의 끝에 [PAD] 토큰을 추가할 수 있다.
패딩의 위치는 모델 설정에 따라 다를 수 있으며,
- 오른쪽 패딩: 일반적으로 많이 사용됨.
- 왼쪽 패딩: Autoregressive 모델(GPT 계열)에서 유리할 수 있음.
- 양쪽 패딩: 특정 모델에서 필요할 수 있음.
패딩을 통해 모든 샘플의 길이가 동일해지면, LLM은 이를 병렬로 처리할 수 있다.
3.3.2 잘림(Truncation)
잘림은 모델의 시퀀스 길이 제한을 초과하는 샘플에서 초과된 부분을 제거하는 과정이다.
예를 들어, 시퀀스 길이를 10으로 제한해야 할 때, 12개 토큰으로 구성된 샘플이 있다면, 초과된 2개의 토큰을 제거해야 한다.
잘림은 보통 오른쪽(끝부분)에서 수행 되지만, 작업 특성에 따라 왼쪽에서 잘라내는 경우도 있다.
하지만, 잘림 과정에서 중요한 정보(예: 답변의 핵심 부분)가 제거될 수도 있기 때문에, 데이터셋을 직접 확인하고 적절한 시퀀스 길이를 설정하는 것이 중요하다.
3.4 시퀀스 길이 설정 시 고려할 요소
✔ 데이터셋 분포 분석
- 데이터셋 내 문장의 길이를 분석하여 적절한 시퀀스 길이를 설정하는 것이 좋다.
- 예를 들어, 데이터의 95%가 1,024 토큰 이하라면, 시퀀스 길이를 1,024로 설정하여 리소스를 최적화할 수 있다.
✔ 잘림된 데이터 확인
- 잘림으로 인해 중요한 정보가 손실되지 않는지 확인해야 한다.
- 중요한 정보가 잘려 나가면, 시퀀스 길이를 늘리는 것이 필요할 수 있다.
✔ 시퀀스 길이와 배치 크기의 균형
- 긴 시퀀스를 사용하면 모델의 성능이 좋아질 수 있지만, GPU 메모리 사용량이 증가하므로 배치 크기를 줄여야 할 수 있다.
- 데이터셋의 특성을 보고, 적절한 시퀀스 길이와 배치 크기를 조절하는 것이 중요하다.
3.5 패딩 위치: 왼쪽 vs. 오른쪽
패딩을 왼쪽 또는 오른쪽에 두는 것은 모델의 특성과 연산 효율성에 따라 다르다.
GPT와 같은 Autoregressive 모델에서는 왼쪽 패딩을 선호한다.
- GPT 계열 모델은 이전 입력을 바탕으로 다음 출력을 생성한다.
- 입력이 의미 있는 정보로 구성되어야, 모델이 다음 토큰을 잘 예측할 수 있다.
- 왼쪽에 PAD를 두면, 오른쪽에 유효한 데이터가 정렬되므로 모델이 더 자연스럽게 학습할 수 있다.
Instruction SFT에서는 오른쪽 패딩을 선호한다.
- Instruction SFT에서는 Instruction과 Output 쌍을 학습하며, Output의 끝에 EOS 토큰을 추가한다.
- 오른쪽 패딩을 사용하더라도 EOS 토큰이 명확히 포함되어 있으므로, 모델이 적절한 위치에서 출력을 종료할 수 있다.
- 또한, 오른쪽 패딩을 하면 여러 개의 입력을 배치로 정렬하기 쉽고, GPU에서 병렬 연산을 수행하는 데 효율적이다.
4. 메모리 최적화 기법
앞에서 살펴본 배치 크기나 시퀀스 길이를 조정하는 이유는 메모리 제한 때문이다.
이러한 메모리 제약을 극복하기 위한 기법으로 Gradient Accumulation과 Gradient Checkpointing이 있다.
4.1 Gradient Accumulation
Gradient Accumulation은 GPU 메모리가 부족하여 한 번에 큰 배치를 처리할 수 없는 경우 사용하는 기술이다.
이 기법은 작은 배치(mini-batch)에서 그래디언트를 계산한 후 누적(accumulate) 하고, 지정된 횟수(Accumulation Step)가 되면 한 번에 파라미터를 업데이트한다.
이를 통해 작은 배치에서도 큰 배치 크기와 유사한 학습 효과를 얻을 수 있다.
HF Training Arguments 예시
per_device_train_batch_size=8
gradient_accumulation_steps=4
4.1.1 Gradient Accumulation의 원리
기본적인 모델 학습 과정
1️⃣ Forward Pass: 배치를 모델에 입력하여 손실(loss)을 계산
2️⃣ Backward Pass: 손실을 기반으로 그래디언트(Gradient) 계산
3️⃣ Optimizer Update: 그래디언트를 바탕으로 모델 파라미터 업데이트
하지만 Gradient Accumulation을 적용하면?
1️⃣ 배치를 여러 개의 작은 mini-batch(예: 배치 1, 2, 3)로 나눈다.
2️⃣ 각 mini-batch에서 Forward와 Backward Pass를 수행하고 계산된 그래디언트(그림4에서 Gradient 1, 2, 3)를 누적(accumulate) 한다.
3️⃣ 지정된 Accumulation Step 횟수에 도달하면, Optimizer가 한 번에 파라미터를 업데이트한다.
4.1.2 Gradient Accumulation의 장점
1️⃣ GPU 메모리 제한 극복
- 한 번에 큰 배치를 학습하려면 많은 메모리가 필요하지만, Gradient Accumulation을 활용하면 작은 배치를 여러 번 학습하여 같은 효과를 낼 수 있다.
- 예:
- Batch Size 4 × Gradient Accumulation 2 → Effective Batch Size 8
- Batch Size 1 × Gradient Accumulation 8 → Effective Batch Size 8
2️⃣ 학습 안정성 및 속도 개선
아래 실험은 아래는 다양한 배치 크기와 Accumulation Step을 조합한 실험 결과이다.
- 배치 크기가 클수록 학습이 더 안정적이고 수렴 속도가 빨라진다.
- Gradient Accumulation을 사용하면 작은 배치에서도 동일한 효과를 얻을 수 있다.
💡 하지만 작은 배치 크기를 사용할 경우,
- Forward와 Backward Pass를 여러 번 수행해야 하므로 학습 시간이 증가할 수 있다.
- GPU 자원을 충분히 활용하지 못해 비효율적인 학습이 될 수도 있다.
➡ 작은 배치 크기 + 높은 Accumulation Step을 조합하면 학습 시간이 증가하고, GPU 사용률이 낮아지는 문제가 발생할 수 있다.
4.1.3 Gradient Accumulation 설정 시 고려할 점
📍 목표 배치 크기 설정
- GPU 메모리에 맞춰 mini-batch 크기와 Gradient Accumulation Step을 조합해야 한다.
- 예: 목표 배치 크기가 32이고, GPU가 mini-batch 8개만 처리할 수 있다면 Gradient Accumulation Step = 4로 설정해서 전체 배치 크기를 32로 맞춘다.
📍 적절한 Accumulation Step 선택
- 이론적으로 같은 Effective Batch 크기면 학습 결과가 같아야 하지만,
- 너무 높은 Accumulation Step을 사용하면 수치적 불안정성이 발생할 수 있다.
- 보통 32 이하의 Accumulation Step을 많이 사용한다.
📍 분산 학습 시 오버헤드 고려
- 여러 GPU를 사용할 경우, 각 GPU에서 계산된 그래디언트를 누적하고 동기화하는 과정에서 성능 저하가 발생할 수 있다.
- 따라서 분산 학습 환경에서는 Accumulation Step을 적절히 조정해야 한다.
4.2 Gradient Checkpointing
Gradient Checkpointing은 메모리 사용량을 줄이기 위한 기법이다.
특히 Transformer처럼 레이어가 깊고 파라미터가 많은 모델에서 유용하다.
이 기법은 순전파(Forward Pass) 과정에서 생성되는 Activation 값을 일부만 저장하고, 역전파(Backward Pass) 과정에서 다시 계산하는 방식을 사용하여 메모리를 절약한다.
HF Training Arguments 예시
gradient_checkpointing=True
4.2.1 Gradient Checkpointing의 원리
1️⃣ 기존 방식 (모든 Activation 저장)
- 일반적으로 모델은 순전파를 수행하면서 Activation 값을 모두 저장하고, 역전파 시 이를 활용하여 그래디언트를 계산한다.
이 방식의 장점은 연산 속도가 빠르지만, 저장해야 할 Activation 값이 많아져 메모리 사용량이 크다는 단점이 있다.
특히, 모델의 깊이가 깊어질수록(즉, 레이어가 많아질수록) 저장해야 할 Activation 값도 많아져 GPU 메모리 부족 문제가 발생할 수 있다.
2️⃣ 모든 Activation을 삭제하고 Forward를 다시 계산
- 순전파(Forward Pass) 과정에서 모든 Activation 값을 저장한 뒤, 역전파가 끝나면 메모리에서 제거하는 방법이 있다.
이 방식은 역전파가 끝난 후 메모리를 해제한다는 점에서 메모리 절감 효과가 있지만, 역전파가 시작되기 전까지는 모든 Activation 값을 유지해야 하므로 절감 효과가 크지 않다. 즉, 순전파 과정에서 여전히 많은 메모리를 사용해야 하므로, 근본적인 해결책이 되지않는다. - 🚨 메모리는 절약되지만, 연산량 증가로 인해 학습 속도가 느려지는 단점이 있다.
3️⃣ Gradient Checkpointing (효율적인 절충안)
- Gradient Checkpointing은 위 두 가지 방식의 단점을 해결하기 위해 고안된 기법이다.
- 기본 개념은 모든 Activation 값을 저장하지 않고, 일정 간격으로 Activation 값을 저장(Checkpointing)하고, 나머지는 필요할 때만 다시 계산하는 방식이다.
- 즉, 모델의 모든 레이어에서 Activation을 저장하지 않고, 특정 레이어(Checkpoint)에서만 Activation 값을 저장하고, 역전파 시 저장된 Checkpoint 이후의 Activation 값만 다시 계산하여 필요한 값을 복원하는 방식이다.
- 이 방법을 사용하면 메모리 사용량을 크게 줄일 수 있으며, 불필요한 재계산을 줄여 연산 효율도 개선할 수 있다.
- 즉, 완전히 다시 Forward를 수행하는 것이 아니라, Checkpoint 이후의 연산만 다시 수행하므로 연산량을 줄이면서도 메모리 절감 효과를 얻을 수 있다.
4.2.2 Gradient Checkpointing의 효과
아래 표는 Gradient Checkpointing을 적용했을 때와 적용하지 않았을 때의 메모리 사용량과 학습 시간 비교이다.
👍 메모리 사용량 감소: 70.13GB → 58.37GB (약 12GB 절감)
🚨 학습 시간 증가: 1804초 → 2329초 (약 29% 증가)
➡ Gradient Checkpointing을 사용하면 메모리를 절약할 수 있지만, 학습 시간이 증가하는 트레이드오프가 존재한다.
4.2.3 Gradient Checkpointing 설정 시 고려할 점
📍 메모리 절감 효과와 활용성
- 확보된 메모리를 활용해 배치 크기 또는 시퀀스 길이를 늘릴 수 있다.
- 특히 GPU 메모리가 부족한 환경에서 파인튜닝을 진행할 때 매우 효과적이다.
📍 적합성 평가
- Layer가 깊은 대형 모델일수록 효과가 크다.
- 하지만 작은 모델에서는 절감 효과가 적고, 연산량만 증가할 수도 있다.
- Gradient Checkpointing 적용 전, 메모리 절감 효과를 먼저 확인하는 것이 중요하다.
'AI' 카테고리의 다른 글
| [인최기] Semi-supervised learning (준지도학습) (0) | 2025.03.12 |
|---|---|
| Residual Block 이해하기 (0) | 2025.02.21 |
| [논문] A Survey of Resource-efficient LLM and Multimodal Foundation Models (0) | 2025.02.13 |
| [Object Detection] R-CNN, Fast R-CNN, Faster R-CNN (2) | 2024.12.18 |
| [논문] DoRA: Weight-Decomposed Low-Rank Adaptation (1) | 2024.12.16 |