Instance Reweighting
● 각 instance 별로 가중치 부여하기
○ 어떤 (negative/positive) instance가 중요한가?
● 가중치는 휴리스틱에 근거하여 결정

Bayesian Personalized Ranking
● Idea: 사용자가 아이템을 싫어할지 여부를 맞추는 대신, 덜 좋아하는 정도를 맞춘다면 어떨까?
● Goal: 각 사용자 별로 개인화된 ranking function을 예측하기
○ 아이템 i와 j를 함께 비교
○ i: 사용자 u가 이미 본 아이템
○ j: 사용자 u가 안 본 아이템
○ i가 j에 비해 더 높은 점수를 가지도록 학습
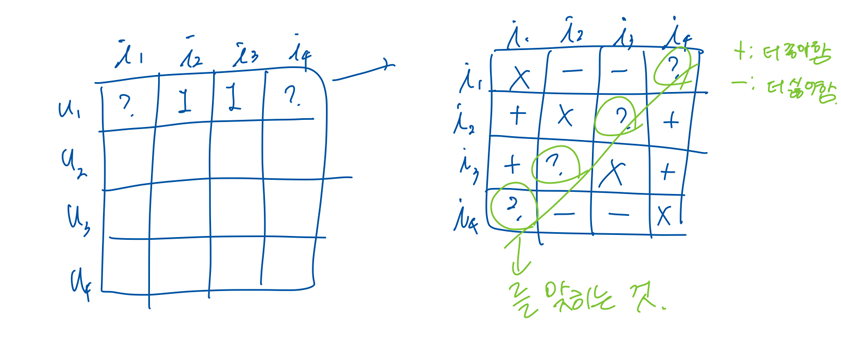
● Basic scheme:
○ 원래 데이터셋은 positive 만 있음 (u, i)
■ 즉, 사용자가 아이템을 봤다는 정보
○ 데이터셋을 증강(augment)하여 triple (u, i, j)들을 생성
■ (u, i): positive
■ (u, j): negative
○ 모델은 i와 j 중 어떤것이 positive인지 binary prediction
● Latent factor model
Implicit
● 파이썬 추천시스템 라이브러리
● 공식홈페이지: https://benfred.github.io/implicit
● github: https://github.com/benfred/implicit
● implicit feedback 데이터용 추천 알고리즘 제공
○ ALS with Instance Reweighting
○ Bayesian Personalized Ranking
○ Logistic Matrix Factorization
○ Nearest Neighbor Models
!pip install implicit
데이터 준비
!wget https://files.grouplens.org/datasets/movielens/ml-latest-small.zip
!unzip ml-latest-small.zip● ml-latest-small: 소규모 데이터셋
○ 100,000 ratings, 9000 movies, 600 users
● wget: url로부터 파일을 다운로드 받는 쉘 명령어
● unzip: zip 압축 파일을 해제하는 쉘 명령어
Compressed Sparse Row (CSR)
● CSR: 희소 행렬 (sparse matrix) 표현 방법 중 하나
● 세 개의 list로 표현: indptr, indices, data

BPR in Implicit
from implicit import bpr
# train
model = bpr.BayesianPersonalizedRanking(factors = 10)
model.fit(ratings_csr)
# test
users = [2, 3]
ids, scores = model.recommend(users, ratings_csr[users])
print(ids)
print(scores)
BPR with Pytorch
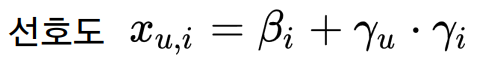
import torch
users = torch.from_numpy(rows)
items = torch.from_numpy(cols)
n_factors = 10
n_items = max(items) + 1
n_users = max(users) + 1
item_bias = torch.randn(n_items, requires_grad=True)
item_factor = torch.randn(n_items, n_factors, requires_grad=True)
user_factor = torch.randn(n_users, n_factors, requires_grad=True)* n_factors : 각 아이템마다 n_factors차원 만큼 만들어 주는 것.
● Training...
lmd = 0.01
n_ratings = len(users)
optim = torch.optim.Adam([item_bias, item_factor, user_factor], lr=0.1)
logsigmoid = torch.nn.LogSigmoid()
for epoch in range(100):
neg_items = torch.randint(1, n_items, (n_ratings,))
pos_score = item_bias[items] + (user_factor[users] * item_factor[items]).sum(dim=1)
neg_score = item_bias[neg_items] + (user_factor[users] * item_factor[neg_items]).sum(dim=1)
reg = (item_bias ** 2).sum() + (item_factor ** 2).sum() + (user_factor ** 2).sum()
cost = -logsigmoid(pos_score - neg_score).sum() + lmd * reg
optim.zero_grad()
cost.backward()
optim.step()
with torch.no_grad():
train_acc = sum(pos_score > neg_score) / n_ratings
print(f"epoch: {epoch}, train accuracy: {train_acc.item()}, cost: {cost.item()}")
● Test...
with torch.no_grad():
n_outputs = 10
uid = 2
scores_all = item_bias + (user_factor[uid] * item_factor).sum(dim=1)
scores_all = scores_all.numpy()
ids = np.argsort(scores_all)[::-1]
pure_ids = ids[np.isin(ids, items[users == uid], invert=True)]
pure_ids = pure_ids[:n_outputs]
scores = scores_all[pure_ids]
print(pure_ids)
print(scores)
'AI > 추천 시스템 설계' 카테고리의 다른 글
| L05.1 User-free Models Practice (0) | 2024.04.30 |
|---|---|
| L03.2 Rating Prediction Practice (0) | 2024.04.11 |
| L03.1 Rating Prediction Practice (1) | 2024.04.10 |
| L02.1 Finding Similar Items Practice (0) | 2024.04.10 |