728x90
MovieLens에서 사용자의 영화 별점을 예측하는 프로그램을 만들어보자. 우선 데이터셋을 다운받는다.
!wget https://files.grouplens.org/datasets/movielens/ml-25m.zip
!unzip ml-25m.zip
이 데이터는 sparse 데이터 셋이다. 전체 데이터셋 크기는 user수 x movie수 인데, 실제로 rating이 매겨진 곳은 훨씬 적기 때문이다. 이 상황에서 우리가 피어슨 유사도나 자카드 유사도를 빠르게 계산하는 방법에 대해서 알아볼 것 이다.
장르가 유사한 영화 찾기
● 영화 제목(movies)과 장르(genresets) 불러오기
○ csv (comma separated values) 파일: 값들을 쉼표로 구분한 텍스트 파일
movies에는 title들을 딕셔너리로. (key: movie id, value: title)
genresets에도 딕셔너리로. (key: movie id, value: genre set)
import csv
titles = {}
genresets = {}
with open("ml-25m/movies.csv") as f:
print(f.readline())
csvreader = csv.reader(f)
next(csvreader) # skip column names
for mid, title, genre in csvreader:
titles[int(mid)] = title
genresets[int(mid)] = set(genre.split("|"))
● 자카드 유사도가 가장 높은 k개의 영화 찾기
자카드 유사도 : 교집합의 크기 / 합집합의 크기
def jaccard_similarity(a, b):
if len(a|b) == 0: return 0
return len(a&b) / len(a|b)
def find_topk_jaccard_genres(target_mid, k=20):
target_title = titles[target_mid]
target_genres = genresets[target_mid]
res = []
for mid, title in titles.items():
genres = genresets[mid]
jaccard_score = jaccard_similarity(target_genres, genres)
# 정렬할 때 편하라고 score를 먼저 넣음.
res.append( (jaccard_score, title) )
res.sort(reverse=True)
return res[:k]
'라라랜드'를 예시로 비슷한 영화를 예측해 보았다.

장르만 같으니 결과가 너무 많고 유명하지 않은 영화도 많이 출력된다.. 좀 다른 방식으로 찾아보자
다른 사용자가 함께 본 영화 찾기
● 별점데이터 불러오기
ratings = []
with open("ml-25m/ratings.csv", "r") as f:
print(f.readline()) # skip column names
for line in f:
uid, mid, rating, timestamp = line.split(",")
ratings.append((int(uid), int(mid), float(rating)))● 시청한 사용자 집합이 유사한 영화 찾기
○ 각 영화를 사용자 집합으로 표현
# jaccard similarity with rating history
from collections import defaultdict
# 딕셔너리로 만듦.
usets = defaultdict(set)
for uid, mid, rating in ratings:
usets[mid].add(uid)user[1] 하면 1번 아이템을 평가한 유저들의 uid집합이 표현된다.
○ 사용자 집합간 자카드 유사도 계산
from tqdm import tqdm
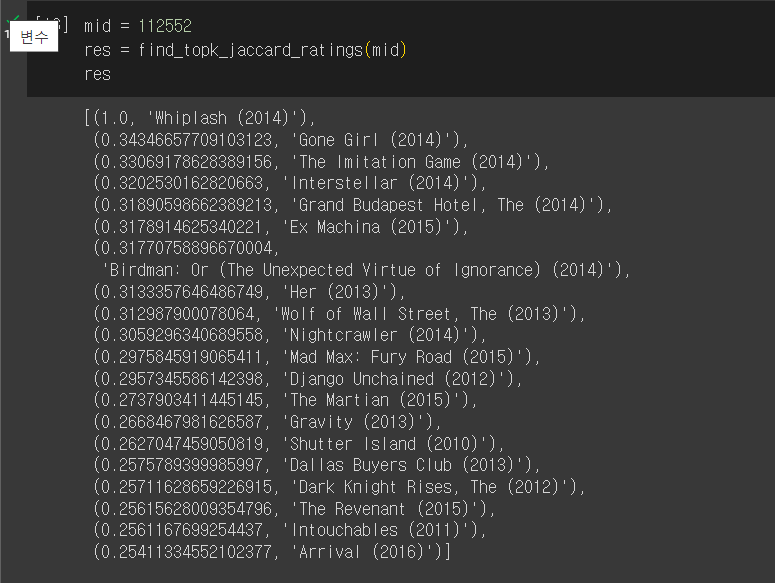
def find_topk_jaccard_ratings(target_mid, k=20):
target_uset = usets[target_mid]
res = []
for mid, uset in tqdm(usets.items()):
jaccard_score = jaccard_similarity(target_uset, uset)
res.append( (jaccard_score, titles[mid]) )
res.sort(reverse=True)
return res[:k]
○ 사용자 집합간 피어슨 유사도 계산
ursets = defaultdict(dict)
for uid, mid, rating in ratings:
ursets[mid][uid] = ratingfor mid, urset in ursets.items():
avg = sum(urset.values())/ len(urset)
for k in urset:
urset[k] -= avg
from tqdm import tqdm
def cosine_similarity(a, b):
numerator = sum(a[k] * b[k] for k in a.keys() & b.keys())
de = (sum(x*x for x in a.values()) * sum(x*x for x in b.values())) **0.5
if de == 0: return 0
return numerator / de
def find_topk_pearson_ratings(target_mid, k=20):
target_uset = ursets[target_mid]
res = []
for mid, title in tqdm(titles.items()):
uset = ursets[mid]
cosine_score = cosine_similarity(target_uset, urset)
res.append( (cosine_score, title) )
res.sort(reverse=True)
return res[:k]
728x90
'AI > 추천 시스템 설계' 카테고리의 다른 글
| L05.1 User-free Models Practice (0) | 2024.04.30 |
|---|---|
| L04.1 Implicit Feedback Practice (0) | 2024.04.12 |
| L03.2 Rating Prediction Practice (0) | 2024.04.11 |
| L03.1 Rating Prediction Practice (1) | 2024.04.10 |