728x90
데이터 준비
● wget: url로부터 파일을 다운로드 받는 쉘 명령어
● unzip: zip 압축 파일을 해제하는 쉘 명령어
!wget https://files.grouplens.org/datasets/movielens/ml-25m.zip
!unzip ml-25m.zip
● ratings.csv 에서 각 열을 각각 users, items, ratings에 numpy array 형태로 저장
import numpy as np
with open("ml-25m/ratings.csv", "r") as f:
print(f.readline()) # skip column names
users = []
items = []
ratings = []
for line in f:
uid, mid, rating, timestamp = line.split(",")
users.append(int(uid))
items.append(int(mid))
ratings.append(float(rating))
users = np.array(users)
items = np.array(items)
ratings = np.array(ratings)* numpy는 내부적으로 C언어로 구현이 되어있어서 효율적으로 작동한다.
기본 모델의 RMSE 확인
● 기본 모델
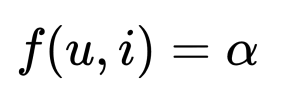
이렇게 하면 알파값은 결국 모든 rating의 평균에 수렴하게 된다. 그래서 알파를 평균으로 봐도 무방하다.
● RMSE (Root Mean Square Error) : (실제값 - 예측값)2 의 평균의 제곱근
rmse = ((ratings - ratings.mean()) ** 2).mean() ** 0.5평균에서 실제값이 rmse만큼 차이가 난다.
Bias 모델
● Bias 모델
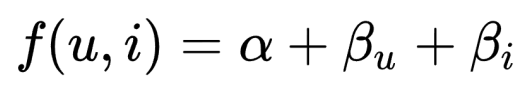
● 변수 생성 및 초기화
alpha = ratings.mean()
user_bias = np.zeros(users.max() + 1)
item_bias = np.zeros(items.max() + 1)
Gradient Descent

lr = 1
lmd = 0.001
n_ratings = len(ratings)
n_users = len(user_bias)
n_items = len(item_bias)
for epoch in range(100):
h = alpha + user_bias[users] + item_bias[items]
diff = h - ratings
rmse = (diff ** 2).mean() ** 0.5
print(f"epoch: {epoch}, rmse: {rmse}")
grd_alpha = diff.mean()
grd_user_bias = np.bincount(users, weights=diff)/n_ratings + lmd * user_bias/n_users
grd_item_bias = np.bincount(items, weights=diff)/n_ratings + lmd * item_bias/n_items
alpha = alpha - lr * grd_alpha
user_bias = user_bias - lr * grd_user_bias
item_bias = item_bias - lr * grd_item_bias
h = alpha + user_bias[users] + item_bias[items]
diff = h - ratings
rmse = (diff ** 2).mean() ** 0.5
print(f"rmse: {rmse}, alpha: {alpha}")
Gradient Descent in Pytorch
import torch
ratings_tensor = torch.from_numpy(ratings)
alpha = torch.tensor(ratings.mean())
alpha.requires_grad_(True)
user_bias = torch.zeros(users.max() + 1, requires_grad=True)
item_bias = torch.zeros(items.max() + 1, requires_grad=True)
optim = torch.optim.Adam([alpha, user_bias, item_bias], lr=0.3)
lmd = 0.001
for epoch in range(20):
h = alpha + user_bias[users] + item_bias[items]
mse = ((h - ratings_tensor) ** 2).mean()
reg = lmd * ((item_bias ** 2).mean() + (user_bias ** 2).mean())
cost = mse + reg
optim.zero_grad()
cost.backward()
optim.step()
# with torch.no_grad():
# print((mse ** 0.5).item(), alpha.item())
with torch.no_grad():
rmse = ((h - ratings_tensor) ** 2).mean() ** 0.5
print(f"epoch: {epoch}, rmse: {rmse}")
Closed-form Solution
해당 변수만 변수로 취급하고 나머지를 다 상수로 취급했을 때 편미분하여 기울기가 0이 되는 지점으로 그 값들을 바로 이동시키는 방법.

from tqdm import tqdm
lmd = 0.001
alpha = ratings.mean()
user_bias = np.zeros(users.max() + 1)
item_bias = np.zeros(items.max() + 1)
for epoch in range(10):
h = alpha + user_bias[users] + item_bias[items]
rmse = ((h - ratings) ** 2).mean() ** 0.5
print(rmse)
alpha = (ratings - (user_bias[users] + item_bias[items])).mean()
user_bias = np.bincount(users, weights=ratings - (alpha + item_bias[items])) / (np.bincount(users) + lmd)
item_bias = np.bincount(items, weights=ratings - (alpha + user_bias[users])) / (np.bincount(items) + lmd)
h = alpha + user_bias[users] + item_bias[items]
rmse = ((h - ratings) ** 2).mean() ** 0.5
print(f"final rmse: {rmse}")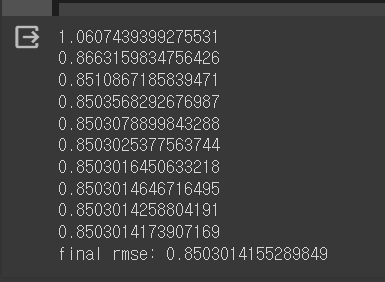
그런데 기울기계산을 하기 어려운 문제들에서는 잘 적용되지않음.
728x90
'AI > 추천 시스템 설계' 카테고리의 다른 글
| L05.1 User-free Models Practice (0) | 2024.04.30 |
|---|---|
| L04.1 Implicit Feedback Practice (0) | 2024.04.12 |
| L03.2 Rating Prediction Practice (0) | 2024.04.11 |
| L02.1 Finding Similar Items Practice (0) | 2024.04.10 |