경사 하강법은 경사를 따라 내려가는 방법을 말한다. 그럼 확률적이란 말은 무슨 뜻일까? 훈련 셋을 사용해 모델을 훈련하기 때문에 경사 하강법도 당연히 훈련 세트를 사용하여 가장 가파른 길을 찾을 것이다. 그런데 전체 샘플을 사용하지 않고 딱 하나의 샘플을 훈련 세트에서 랜덤하게 골라 가장 가파른 길을 찾는 것이다. 그다음 훈련 세트에서 랜덤하게 또 다른 샘플을 하나 선택하여 경사를 조금 내려가고 이런 식으로 전체 샘플을 모두 사용할 때까지 반복한다. 이처럼 훈련 세트에서 랜덤하게 하나의 샘플을 고르는 것이 확률적 경사 하강법이다.
모든 샘플을 다 사용했는데도 다 못내려왔다면 어떻게 할까? 훈련 세트에 모든 샘플을 다시 채워 넣는다. 그다음 다시 랜덤하게 하나의 샘플을 선택해 이어서 경사를 내려간다. 이렇게 만족 할 만한 위치에 도달할 때까지 계속 내려가면 된다. 확률적 경사 하강법에서 훈련 세트를 한 번 모두 사용하는 과정을 에포크(epoch)라고 부른다.
무자위로 샘플을 선택해서 내려가는게 잘 안 동작할 것같지만 꽤나 잘 동작한다. 하지만 그래도 미심쩍다면 1개 말고 무작위로 몇 개의 샘플을 선택해서 경사를 따라 내려가는 방법이 있다. 이를 미니배치 경사 하강법(minibatch gradient descent)이라고 한다.
그리고 극단적으로 한 번 경사로를 따라 이동할 때 전체 샘플을 사용할 수도 있다. 이를 배치 경사 하강법(batch gradient descent)이라고 한다. 사실 전체 데이터를 사용하기 때문에 가장 안정적인 방법이 될 수 있지만 전체 데이터를 사용하면 그만큼 컴퓨터 자원을 많이 사용하게 된다.
손실함수
손실함수는 어떤 문제에서 머신러닝 알고리즘이 얼마나 엉터리인지를 측정하는 기준이다. 그래서 손실 함수는 값이 작을수록 좋다. 하지만 어떤 값이 최솟값인지는 알 수 없다. 최대한 많이 찾아보고 만족할만한 수준이면 최적의 값을 찾았다고 인정해야한다.
로지스틱 손실 함수
첫 번째 샘플의 예측이 0.9라면 양성 클래스의 타깃인 1과 곱한 다음 음수로 바꾸어 준다. 이 경우 예측이 1에 가까울수록 좋은 모델이다. 예측이 1에 가까울수록 예측과 타깃의 곱의 음수는 점점 작아진다.
0.9 * 1 -> -0.9
만약 샘플의 타깃이 음성 클래스라고 하면 0이기 때문에 이 값을 예측 확률인 0.2와 그대로 곱하면 0이 되기 때문에 다른 방법을 이용해야한다. 그 방법으로 타깃을 마치 양성 클래스처럼 바꾸어 1로 만드는 것이다. 대신 예측값도 양성 클래스에 대한 예측으로 바꾼다. 즉 1 - 0.2 = 0.8로 사용하는 것이다. 그다음 곱하고 음수로 바꾸는 것은 위와 동일하다.
0.8 * 1 -> -0.8
여기에서 예측 확률에 로그 함수를 적용하면 더 좋다. 예측 확률의 범위는 0~1 사이인데 로그 함수는 이 사이에서 음수가 되므로 최종 손실값은 양수 된다. 손실이 양수가 되면 직관적으로 이해하기 더 쉽다. 또 로그 함수는 0에 가까울 수록 아주 큰 음수가 되기 때문에 손실을 아주 크게 만들어 모델에 큰 영향을 미칠 수 있다.
양성 클래스(타깃 = 1)일 때 손실은 -log(예측확률)로 계산한다. 확률이 1에서 멀어져 0에 가까워질수록 손실을 아주 큰 양수가 된다. 음성 클래스(타깃 = 0)일 때 손실은 -log(1 - 예측확률)로 계산한다. 이 예측 확률이 0에서 멀어져 1에 가까워질수록 손실은 아주 큰 양수가 된다. 이 손실 함수를 로지스틱 손실 함수(logistic loss function) 또는 이진 크로스엔트로피 손실 함수(binary cross entropy loss function)라고 부른다.
여기서는 이진 분류를 예로 들어 설명했지만 다중 분류도 매우 비슷한 손실 함수를 사용한다. 다중 분류에서 사용하는 손실 함수를 크로스엔트로피 손실 함수라고 부른다. 이진 분류는 로지스틱 손실 함수를 사용하고 다중 분류는 크로스엔트로피 손실 함수를 사용한다. 회귀에는 MSE를 많이 사용한다.
다중 분류일 경우 SGDClassifier에 loss='log_loss'로 지정하면 클래스마다 이진 분류 모델을 만든다. 즉 하나만 양성 클래스로 두고 나머지를 모두 음성 클래스로 두는 방식이다. 이런 방식을 OvR(One versus Rest)라고 부른다.
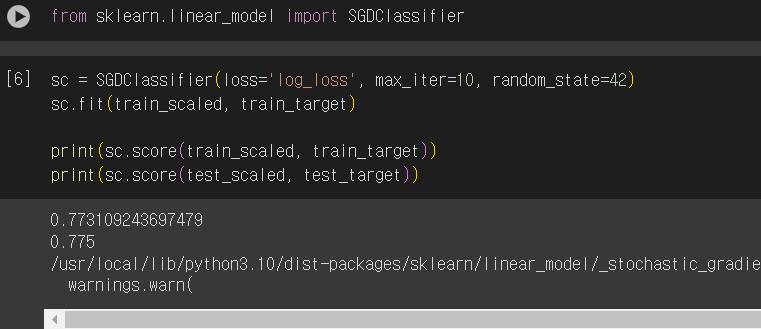
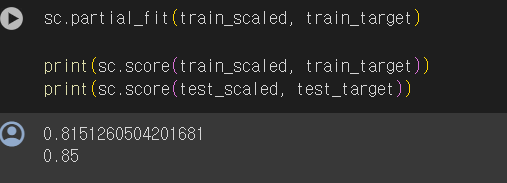
확률적 경사 하강법은 점진적 학습이 가능하다. SGDClassifier객체를 다시 만들지 않고 훈련한 모델 sc를 추가로 더 훈련해보자. 모델을 이어서 훈련할 때는 partial_fit()메서드를 사용한다. 이 메서드는 fit()메서드와 사용법이 같지만 호출할 때마다 1 에포크씩 이어서 훈련할 수 있다.
하지만 얼마나 더 훈련해야 할까? 무작정 많이 반복할 수는 없으니 어떤 기준이 필요하다.
에포크가 진행됨에 따라 모델의 정확도를 나타낸 그래프를 보면 훈련 세트 점수는 에포크가 진행될수록 꾸준히 증가하지만 테스트 세트 점수는 어느 순간 감소하기 시작한다. 바로 이 지점이 모델이 과대적합되기 시작하는 곳이다. 과대적합이 시작하기 전에 훈련을 멈추는 것을 조기 종료(early stopping)이라고 한다.
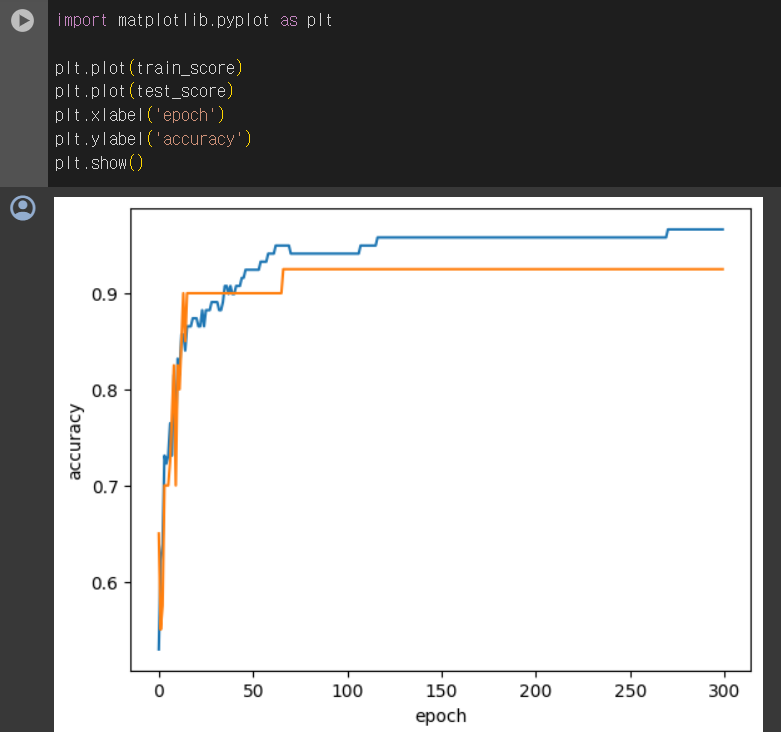
100번 째 에포크 이후에는 후녈ㄴ 세트와 테스트 세트의 점수가 조금씩 벌어지고 있다. 또 확실히 에포크 초기에는 과소적합 되어 훈련 셋과 테스트 셋의 점수가 낮다. 이 모델의 경우 백 번째 에포크가 적절한 반복 횟수로 보인다.

*SGDClassifier는 일정 에포크 동안 성능이 향상되지 않으면 더 훈련하지 않고 자동으로 멈춘다.
'AI > 혼공파 머신러닝+딥러닝' 카테고리의 다른 글
| [ML 06-1] 군집 알고리즘 (0) | 2024.05.24 |
|---|---|
| [ML 05-1] 결정 트리 (0) | 2024.05.15 |
| [ML 04-1] 로지스틱 회귀 (0) | 2024.04.04 |
| [ML 03-3] 특성공학과 규제 - 릿지(Ridge), 라쏘(Lasso) (2) | 2024.03.31 |
| [KNN, ML 03-2] 선형회귀(Linear Regression) (0) | 2024.03.27 |
경사 하강법은 경사를 따라 내려가는 방법을 말한다. 그럼 확률적이란 말은 무슨 뜻일까? 훈련 셋을 사용해 모델을 훈련하기 때문에 경사 하강법도 당연히 훈련 세트를 사용하여 가장 가파른 길을 찾을 것이다. 그런데 전체 샘플을 사용하지 않고 딱 하나의 샘플을 훈련 세트에서 랜덤하게 골라 가장 가파른 길을 찾는 것이다. 그다음 훈련 세트에서 랜덤하게 또 다른 샘플을 하나 선택하여 경사를 조금 내려가고 이런 식으로 전체 샘플을 모두 사용할 때까지 반복한다. 이처럼 훈련 세트에서 랜덤하게 하나의 샘플을 고르는 것이 확률적 경사 하강법이다.
모든 샘플을 다 사용했는데도 다 못내려왔다면 어떻게 할까? 훈련 세트에 모든 샘플을 다시 채워 넣는다. 그다음 다시 랜덤하게 하나의 샘플을 선택해 이어서 경사를 내려간다. 이렇게 만족 할 만한 위치에 도달할 때까지 계속 내려가면 된다. 확률적 경사 하강법에서 훈련 세트를 한 번 모두 사용하는 과정을 에포크(epoch)라고 부른다.
무자위로 샘플을 선택해서 내려가는게 잘 안 동작할 것같지만 꽤나 잘 동작한다. 하지만 그래도 미심쩍다면 1개 말고 무작위로 몇 개의 샘플을 선택해서 경사를 따라 내려가는 방법이 있다. 이를 미니배치 경사 하강법(minibatch gradient descent)이라고 한다.
그리고 극단적으로 한 번 경사로를 따라 이동할 때 전체 샘플을 사용할 수도 있다. 이를 배치 경사 하강법(batch gradient descent)이라고 한다. 사실 전체 데이터를 사용하기 때문에 가장 안정적인 방법이 될 수 있지만 전체 데이터를 사용하면 그만큼 컴퓨터 자원을 많이 사용하게 된다.
손실함수
손실함수는 어떤 문제에서 머신러닝 알고리즘이 얼마나 엉터리인지를 측정하는 기준이다. 그래서 손실 함수는 값이 작을수록 좋다. 하지만 어떤 값이 최솟값인지는 알 수 없다. 최대한 많이 찾아보고 만족할만한 수준이면 최적의 값을 찾았다고 인정해야한다.
로지스틱 손실 함수
첫 번째 샘플의 예측이 0.9라면 양성 클래스의 타깃인 1과 곱한 다음 음수로 바꾸어 준다. 이 경우 예측이 1에 가까울수록 좋은 모델이다. 예측이 1에 가까울수록 예측과 타깃의 곱의 음수는 점점 작아진다.
0.9 * 1 -> -0.9
만약 샘플의 타깃이 음성 클래스라고 하면 0이기 때문에 이 값을 예측 확률인 0.2와 그대로 곱하면 0이 되기 때문에 다른 방법을 이용해야한다. 그 방법으로 타깃을 마치 양성 클래스처럼 바꾸어 1로 만드는 것이다. 대신 예측값도 양성 클래스에 대한 예측으로 바꾼다. 즉 1 - 0.2 = 0.8로 사용하는 것이다. 그다음 곱하고 음수로 바꾸는 것은 위와 동일하다.
0.8 * 1 -> -0.8
여기에서 예측 확률에 로그 함수를 적용하면 더 좋다. 예측 확률의 범위는 0~1 사이인데 로그 함수는 이 사이에서 음수가 되므로 최종 손실값은 양수 된다. 손실이 양수가 되면 직관적으로 이해하기 더 쉽다. 또 로그 함수는 0에 가까울 수록 아주 큰 음수가 되기 때문에 손실을 아주 크게 만들어 모델에 큰 영향을 미칠 수 있다.
양성 클래스(타깃 = 1)일 때 손실은 -log(예측확률)로 계산한다. 확률이 1에서 멀어져 0에 가까워질수록 손실을 아주 큰 양수가 된다. 음성 클래스(타깃 = 0)일 때 손실은 -log(1 - 예측확률)로 계산한다. 이 예측 확률이 0에서 멀어져 1에 가까워질수록 손실은 아주 큰 양수가 된다. 이 손실 함수를 로지스틱 손실 함수(logistic loss function) 또는 이진 크로스엔트로피 손실 함수(binary cross entropy loss function)라고 부른다.
여기서는 이진 분류를 예로 들어 설명했지만 다중 분류도 매우 비슷한 손실 함수를 사용한다. 다중 분류에서 사용하는 손실 함수를 크로스엔트로피 손실 함수라고 부른다. 이진 분류는 로지스틱 손실 함수를 사용하고 다중 분류는 크로스엔트로피 손실 함수를 사용한다. 회귀에는 MSE를 많이 사용한다.
다중 분류일 경우 SGDClassifier에 loss='log_loss'로 지정하면 클래스마다 이진 분류 모델을 만든다. 즉 하나만 양성 클래스로 두고 나머지를 모두 음성 클래스로 두는 방식이다. 이런 방식을 OvR(One versus Rest)라고 부른다.
확률적 경사 하강법은 점진적 학습이 가능하다. SGDClassifier객체를 다시 만들지 않고 훈련한 모델 sc를 추가로 더 훈련해보자. 모델을 이어서 훈련할 때는 partial_fit()메서드를 사용한다. 이 메서드는 fit()메서드와 사용법이 같지만 호출할 때마다 1 에포크씩 이어서 훈련할 수 있다.
하지만 얼마나 더 훈련해야 할까? 무작정 많이 반복할 수는 없으니 어떤 기준이 필요하다.
에포크가 진행됨에 따라 모델의 정확도를 나타낸 그래프를 보면 훈련 세트 점수는 에포크가 진행될수록 꾸준히 증가하지만 테스트 세트 점수는 어느 순간 감소하기 시작한다. 바로 이 지점이 모델이 과대적합되기 시작하는 곳이다. 과대적합이 시작하기 전에 훈련을 멈추는 것을 조기 종료(early stopping)이라고 한다.
100번 째 에포크 이후에는 후녈ㄴ 세트와 테스트 세트의 점수가 조금씩 벌어지고 있다. 또 확실히 에포크 초기에는 과소적합 되어 훈련 셋과 테스트 셋의 점수가 낮다. 이 모델의 경우 백 번째 에포크가 적절한 반복 횟수로 보인다.
*SGDClassifier는 일정 에포크 동안 성능이 향상되지 않으면 더 훈련하지 않고 자동으로 멈춘다.
'AI > 혼공파 머신러닝+딥러닝' 카테고리의 다른 글
| [ML 06-1] 군집 알고리즘 (0) | 2024.05.24 |
|---|---|
| [ML 05-1] 결정 트리 (0) | 2024.05.15 |
| [ML 04-1] 로지스틱 회귀 (0) | 2024.04.04 |
| [ML 03-3] 특성공학과 규제 - 릿지(Ridge), 라쏘(Lasso) (2) | 2024.03.31 |
| [KNN, ML 03-2] 선형회귀(Linear Regression) (0) | 2024.03.27 |