앞서 로지스틱 회귀를 통해 2개의 선택지 중에서 1개를 고르는 이진 분류(Binary Classification)를 풀어봤습니다. 이번 챕터에서는 소프트맥스 회귀를 통해 3개 이상의 선택지 중에서 1개를 고르는 다중 클래스 분류(Multi-Class Classification)를 실습해봅시다.
1. 다중 클래스 분류(Multi-class Classification)
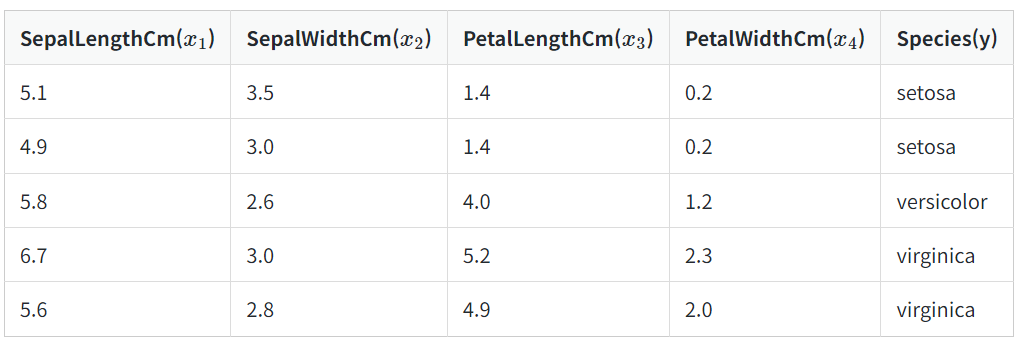
이진 분류가 두 개의 답 중 하나를 고르는 문제였다면, 세 개 이상의 답 중 하나를 고르는 문제를 다중 클래스 분류(Multi-class Classification)라고 합니다. 아래의 문제는 꽃받침 길이, 꽃받침 넓이, 꽃잎 길이, 꽃잎 넓이라는 4개의 특성(feature)을 가지고 setosa, versicolor, virginica라는 3개의 붓꽃 품종 중 어떤 품종인지를 예측하는 문제로 전형적인 다중 클래스 분류 문제입니다.
위 붓꽃 품종 분류하기 문제를 어떻게 풀지 고민하기 위해 앞서 배운 로지스틱 회귀의 이진 분류를 복습해보겠습니다.
이번 챕터의 설명에서 입력은 𝑋, 가중치는 𝑊, 편향은 𝐵, 출력은 𝑌^로 각 변수는 벡터 또는 행렬로 가정합니다.
- 𝑌^은 예측값이라는 의미를 가지고 있으므로 가설식에서 𝐻(𝑋) 대신 사용되기도 합니다.
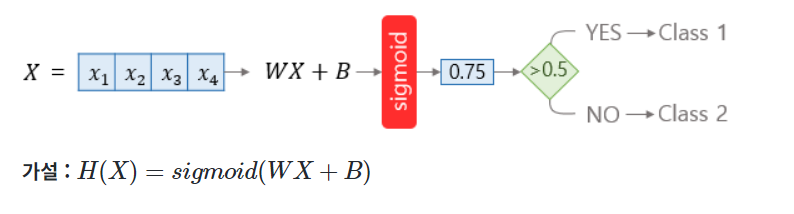
1. 로지스틱 회귀
로지스틱 회귀에서 시그모이드 함수는 예측값을 0과 1 사이의 값으로 만듭니다. 예를 들어 스팸 메일 분류기를 로지스틱 회귀로 구현하였을 때, 출력이 0.75이라면 이는 이메일이 스팸일 확률이 75%라는 의미가 됩니다. 반대로, 스팸 메일이 아닐 확률은 25%가 됩니다. 이 두 확률의 총 합은 1입니다.
2. 소프트맥스 회귀
소프트맥스 회귀는 확률의 총 합이 1이 되는 이 아이디어를 다중 클래스 분류 문제에 적용합니다. 소프트맥스 회귀는 각 클래스. 즉, 각 선택지마다 소수 확률을 할당합니다. 이때 총 확률의 합은 1이 되어야 합니다. 이렇게 되면 각 선택지가 정답일 확률로 표현됩니다.
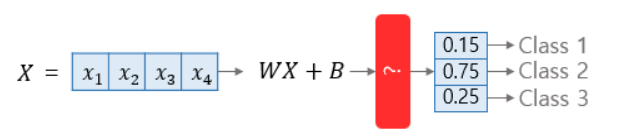
결국 소프트맥스 회귀는 선택지의 개수만큼의 차원을 가지는 벡터를 만들고, 해당 벡터가 벡터의 모든 원소의 합이 1이 되도록 원소들의 값을 변환시키는 어떤 함수를 지나게 만들어야 합니다. 위의 그림은 붓꽃 품종 분류하기 문제 등과 같이 선택지의 개수가 3개일때, 3차원 벡터가 어떤 함수 ?를 지나 원소의 총 합이 1이 되도록 원소들의 값이 변환되는 모습을 보여줍니다. 이 함수를 소프트맥스(softmax) 함수라고 합니다.
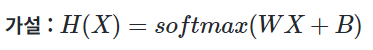
2. 소프트맥스 함수(Softmax function)
소프트맥스 함수는 분류해야하는 정답지(클래스)의 총 개수를 k라고 할 때, k차원의 벡터를 입력받아 각 클래스에 대한 확률을 추정합니다. 우선 수식에 대해 설명하고, 그 후에는 그림으로 이해해보겠습니다.
1) 소프트맥스 함수의 이해
k차원의 벡터에서 i번째 원소를 𝑧𝑖, i번째 클래스가 정답일 확률을 𝑝𝑖로 나타낸다고 하였을 때 소프트맥스 함수는 𝑝𝑖를 다음과 같이 정의합니다.

𝑝1,𝑝2,𝑝3 각각은 1번 클래스가 정답일 확률, 2번 클래스가 정답일 확률, 3번 클래스가 정답일 확률을 나타내며 각각 0과 1사이의 값으로 총 합은 1이 됩니다. 여기서 분류하고자하는 3개의 클래스는 virginica, setosa, versicolor이므로 이는 결국 주어진 입력이 virginica일 확률, setosa일 확률, versicolor일 확률을 나타내는 값을 의미합니다. 여기서는 i가 1일 때는 virginica일 확률을 나타내고, 2일 때는 setosa일 확률, 3일때는 versicolor일 확률이라고 지정하였다고 합시다. 이에따라 식을 문제에 맞게 다시 쓰면 아래와 같습니다.
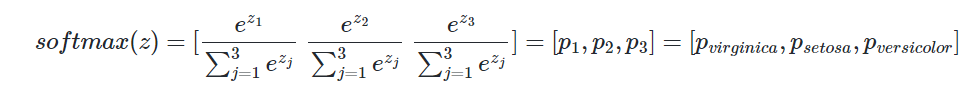
분류하고자 하는 클래스가 k개일 때, k차원의 벡터를 입력받아서 모든 벡터 원소의 값을 0과 1사이의 값으로 값을 변경하여 다시 k차원의 벡터를 리턴한다는 내용을 식으로 낸 것 입니다. 방금 배운 개념을 그림을 통해 다시 봅시다.
2) 그림을 통한 이해
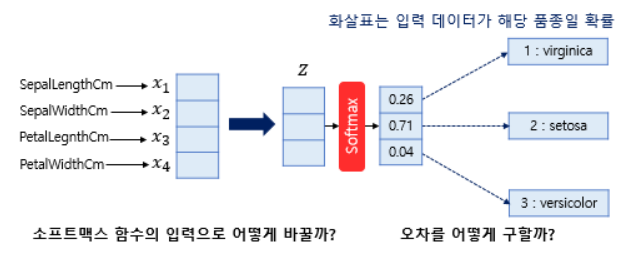
위의 그림에 점차 살을 붙여봅시다. 여기서는 샘플 데이터를 1개씩 입력으로 받아 처리한다고 가정해봅시다. 즉, 배치 크기가 1입니다.
위의 그림에는 두 가지 질문이 있습니다. 첫번째 질문은 소프트맥스 함수의 입력에 대한 질문입니다. 하나의 샘플 데이터는 4개의 독립 변수 𝑥를 가지는데 이는 모델이 4차원 벡터를 입력으로 받음을 의미합니다. 그런데 소프트맥스의 함수의 입력으로 사용되는 벡터는 벡터의 차원이 분류하고자 하는 클래스의 개수가 되어야 하므로 어떤 가중치 연산을 통해 3차원 벡터로 변환되어야 합니다. 위의 그림에서는 소프트맥스 함수의 입력으로 사용되는 3차원 벡터를 𝑧로 표현하였습니다.
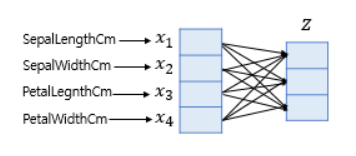
샘플 데이터 벡터를 소프트맥스 함수의 입력 벡터로 차원을 축소하는 방법은 간단합니다. 소프트맥스 함수의 입력 벡터 𝑧의 차원수만큼 결과값의 나오도록 가중치 곱을 진행합니다. 위의 그림에서 화살표는 총 (4 × 3 = 12) 12개이며 전부 다른 가중치를 가지고, 학습 과정에서 점차적으로 오차를 최소화하는 가중치로 값이 변경됩니다.
두번째 질문은 오차 계산 방법에 대한 질문입니다. 소프트맥스 함수의 출력은 분류하고자하는 클래스의 개수만큼 차원을 가지는 벡터로 각 원소는 0과 1사이의 값을 가집니다. 이 각각은 특정 클래스가 정답일 확률을 나타냅니다. 여기서는 첫번째 원소인 𝑝1은 virginica가 정답일 확률, 두번째 원소인 𝑝2는 setosa가 정답일 확률, 세번째 원소인 𝑝3은 versicolor가 정답일 확률로 고려하고자 합니다. 그렇다면 이 예측값과 비교를 할 수 있는 실제값의 표현 방법이 있어야 합니다. 소프트맥스 회귀에서는 실제값을 원-핫 벡터로 표현합니다.
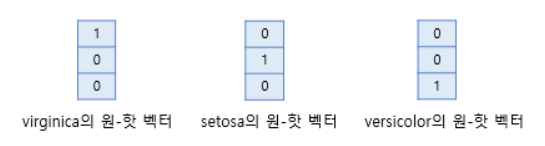
위의 그림은 소프트맥스 함수의 출력 벡터의 첫번째 원소 𝑝1가 virginica가 정답일 확률, 두번째 원소 𝑝2가 setosa가 정답일 확률, 세번째 원소 𝑝3가 versicolor가 정답일 확률을 의미한다고 하였을 때, 각 실제값의 정수 인코딩은 1, 2, 3이 되고 이에 원-핫 인코딩을 수행하여 실제값을 원-핫 벡터로 수치화한 것을 보여줍니다.
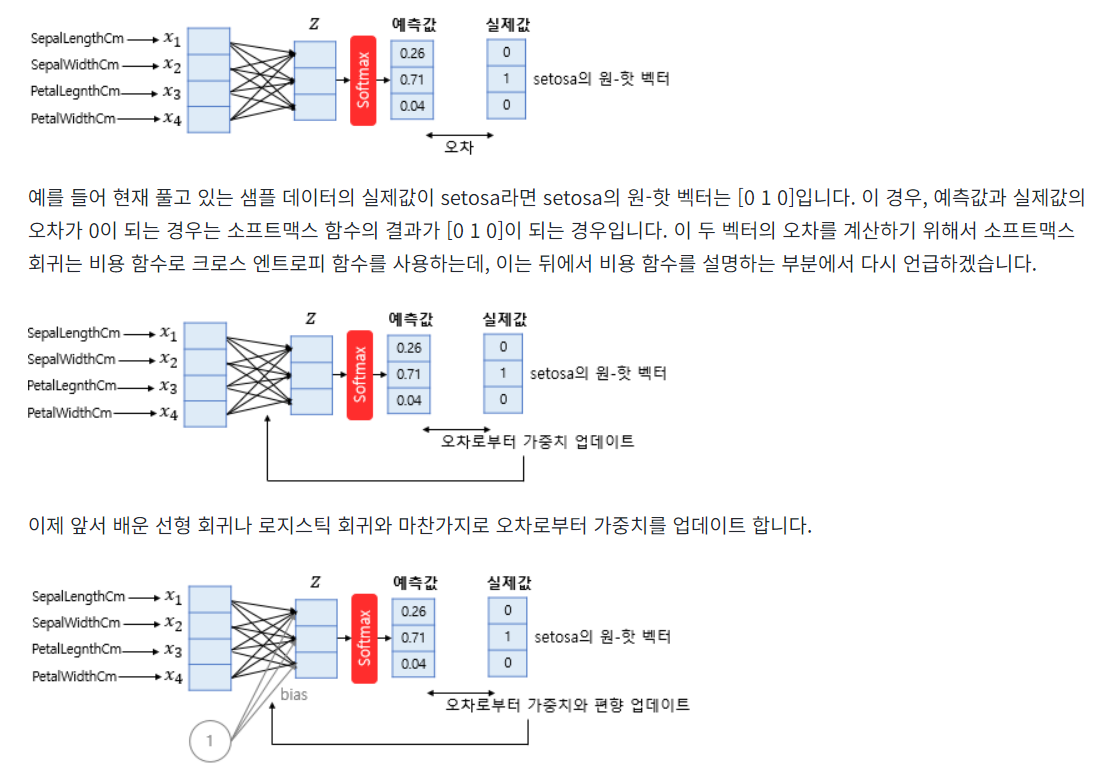
더 정확히는 선형 회귀나 로지스틱 회귀와 마찬가지로 편향 또한 업데이트의 대상이 되는 매개 변수입니다. 소프트맥스 회귀를 벡터와 행렬 연산으로 이해해봅시다. 입력을 특성(feature)의 수만큼의 차원을 가진 입력 벡터 𝑥라고 하고, 가중치 행렬을 𝑊, 편향을 𝑏라고 하였을 때, 소프트맥스 회귀에서 예측값을 구하는 과정을 벡터와 행렬 연산으로 표현하면 아래와 같습니다.
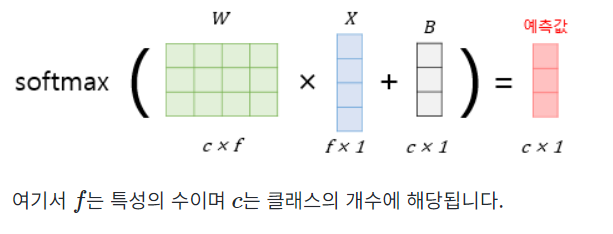
3. 붓꽃 품종 분류하기 행렬 연산으로 이해하기

이번 문제는 선택지가 총 3개인 문제이므로 가설의 예측값으로 얻는 행렬 𝑌^의 열의 개수는 3개여야 합니다. 그리고 각 행은 행렬 𝑋의 각 행의 예측값이므로 행의 크기는 동일해야 합니다.
크기 5 × 3의 행렬 𝑌^는 크기 5 × 4 입력 행렬 𝑋과 가중치 행렬 𝑊의 곱으로 얻어지는 행렬이므로 가중치 행렬 𝑊의 크기는 추정을 통해 4 × 3의 크기를 가진 행렬임을 알 수 있습니다. 결과적으로 행렬 𝑌^의 크기는 5 × 3입니다.
편향 행렬 𝐵는 예측값 행렬 𝑌^와 크기가 동일해야 하므로 5 × 3의 크기를 가집니다.
4. 비용 함수(Cost function)
소프트맥스 회귀에서는 비용 함수로 크로스 엔트로피 함수를 사용합니다. 여기서는 소프트맥스 회귀에서의 크로스 엔트로피 함수뿐만 아니라, 다양한 표기 방법에 대해서 이해해보겠습니다.
1) 크로스 엔트로피 함수

2) 이진 분류에서의 크로스 엔트로피 함수

'AI > ML' 카테고리의 다른 글
| [ML] Feature Engineering (0) | 2024.09.23 |
|---|---|
| [ML] 소프트맥스 회귀 구현하기 (0) | 2024.05.07 |
| [ML] 원-핫 인코딩(One-Hot Encoding) (0) | 2024.04.05 |
| [ML] 로지스틱 회귀(Logistic Regression) (1) | 2024.03.29 |
| [ML] 커스텀 데이터셋(Custom Dataset) (0) | 2024.03.29 |